







该函数主要试用于每一个类别都是相不排斥的分类任务,即一个实例(instance)可以划分为到多个类别,比如图像中有一匹马,他即可以是是马这个标签,也可以是动物这个标签。
以下是代码示例,前面是分解的代码,后面with tf.session是一步到位代码,两者的输出相同
import numpy as np
import tensorflow as tf
def sigmoid(x):
return 1.0/(1+np.exp(-x))
labels=np.array([[1.,0.,0.],[0.,1.,0.],[0.,0.,1.]])
logits=np.array([[-1.,8.,2.],[-3.,14.,1.],[1.,2.,4.]])
y_pred=sigmoid(logits)
prb_error1 = -labels*np.log(y_pred) #计算分类结果在正确类别处的损失,
prb_error2 = -(1-labels)*np.log(1-y_pred)
prob_error1= prb_error1 + prb_error2 #属于该类的损失+其他类的损失
print(prob_error1)
with tf.Session() as sess:
print(sess.run(tf.nn.sigmoid_cross_entropy_with_logits(labels=labels,logits=logits)))label是one-hot的形式,有三行,表示有三个instance,1对应的位置表示每个instance真实的类别,即分别为类1,类2,类3。
Logits是网络预测的结果。
1、首先y_pred= sigmoid (logits) 函数将网络的输出映射为概率,如输出结果如下
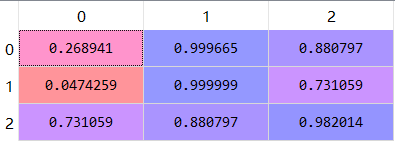
可以看到对于第一个实例,因为其第二类预测结果logits为8,其余分别为-1和2,因此属于第二类的概率就最大,为0.999665;同理第二个实例的第二类预测结果logits为14,因此概率也最大,为0.9999;第三个实例预测为第三类的概率最大为0.982。
2、下面就是要计算sigmoid的交叉熵损失了,由两部分组成。
(1)首先来看第一部分,计算公式为:prb_error1 = labels* - np.log(y_pred)
我们都知道- np.log(y_pred) 就是交叉熵中的log计算部分,计算出来是个矩阵。Labels也是一个矩阵,这两个矩阵的大小都为(2,3),用*号就是对应的元素相乘,就得到了预测结果对应正确类别处的损失,如下。可以看出,由于第二个实例和第三个实例预测的结果是正确的,因此他们的损失就很小,而第一个实例预测为第二个类别的概率最大(它实际是第一个类别),因此损失就很大。

(2) 再来看第二部分,计算公式为-(1-labels)*np.log(1-y_pred)。这个就是计算预测结果在错误类别处的损失,当预测结果在错误类别处的概率较大时,就说明错误的可能性就大,因此损失就大。所以我们在计算-log时,带入的值是(1-p),p越大,1-p越小,-log(1-p)的值就越大,损失就越大。
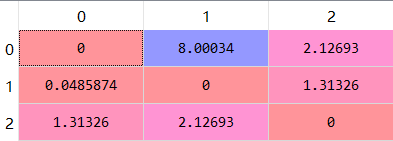
(3)最后将两部分加起来,就是总的损失:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









