







张家骥 + 原创作品转载请注明出处 + 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
第一部分:实验过程
第二部分:分析start_kernel函数的执行过程
第三部分:自己对“Linux系统启动过程”的理解,以及idle进程、1号进程是怎么来的。
第一部分:实验过程
1.1使用实验楼的虚拟机打开shell
cd LinuxKernel/
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img

可以看到内核启动完成后效果如下:
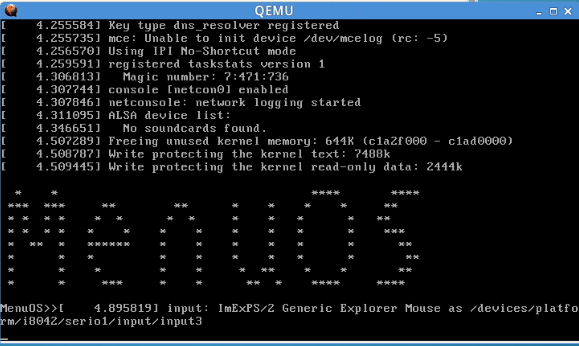
1.2使用gdb跟踪调试内核
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S # 关于-s和-S选项的说明:
-S freeze CPU at startup (use ’c’ to start execution)
-s shorthand for -gdb tcp::1234 若不想使用1234端口,则可以使用-gdb tcp:xxxx来取代-s选项。

执行上述命令后,可以看到如下效果:
1.3用gdb调试。
gdb
(gdb)file linux-3.18.6/vmlinux # 在gdb界面中targe remote之前加载符号表
(gdb)target remote:1234 # 建立gdb和gdbserver之间的连接,按c 让qemu上的Linux继续运行
(gdb)break start_kernel # 断点的设置可以在target remote之前,也可以在之后。
另开一个窗口:输入gdb,启动gdb。加载符号表时,注意当前工作目录是否在LinuxKernel/下,不在的话,路径要写完整才行。
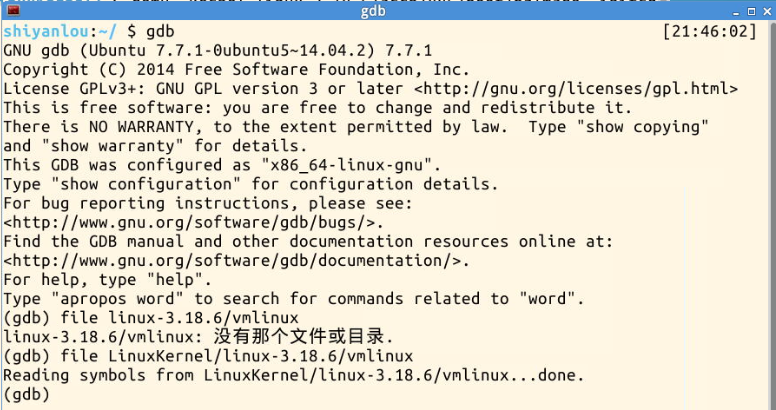
输入:target remote:1234

设置第一个断点位于start_kernel处

按c,继续执行到断点处停止。

此时,可以看到MenuOS系统界面效果如下:
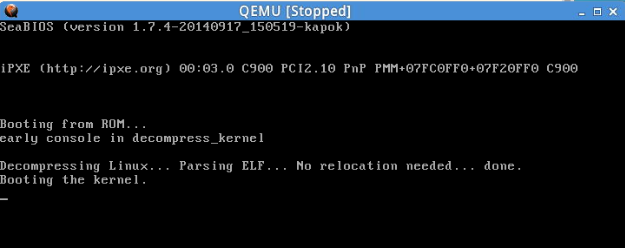
再设置一个断点在rest_init处,按c继续执行。

接下来用n,逐过程执行。
直到cpu_startup_entry,再按n让其继续执行,就进入系统,陷入无限循环。

切换到MenuOS界面,可以看到,已经启动完成。
按Ctrl+C,强制停止调试,可以看到gdb从idle()处退出。

第二部分:分析start_kernel函数的执行过程
2.1sart_kernel 函数位于linux-3.18.6/init/main.c中。其函数体如下:后面会详细分析。
asmlinkage __visible void __init start_kernel(void)
501{
502 char *command_line;
503 char *after_dashes;
504
505 /*
506 * Need to run as early as possible, to initialize the
507 * lockdep hash:
508 */
509 lockdep_init();
510 set_task_stack_end_magic(&init_task);
511 smp_setup_processor_id();
512 debug_objects_early_init();
513
514 /*
515 * Set up the the initial canary ASAP:
516 */
517 boot_init_stack_canary();
518
519 cgroup_init_early();
520
521 local_irq_disable();
522 early_boot_irqs_disabled = true;
523
524/*
525 * Interrupts are still disabled. Do necessary setups, then
526 * enable them
527 */
528 boot_cpu_init();
529 page_address_init();
530 pr_notice("%s", linux_banner);
531 setup_arch(&command_line);
532 mm_init_cpumask(&init_mm);
533 setup_command_line(command_line);
534 setup_nr_cpu_ids();
535 setup_per_cpu_areas();
536 smp_prepare_boot_cpu(); /* arch-specific boot-cpu hooks */
537
538 build_all_zonelists(NULL, NULL);
539 page_alloc_init();
540
541 pr_notice("Kernel command line: %s\n", boot_command_line);
542 parse_early_param();
543 after_dashes = parse_args("Booting kernel",
544 static_command_line, __start___param,
545 __stop___param - __start___param,
546 -1, -1, &unknown_bootoption);
547 if (!IS_ERR_OR_NULL(after_dashes))
548 parse_args("Setting init args", after_dashes, NULL, 0, -1, -1,
549 set_init_arg);
550
551 jump_label_init();
552
553 /*
554 * These use large bootmem allocations and must precede
555 * kmem_cache_init()
556 */
557 setup_log_buf(0);
558 pidhash_init();
559 vfs_caches_init_early();
560 sort_main_extable();
561 trap_init();
562 mm_init();
563
564 /*
565 * Set up the scheduler prior starting any interrupts (such as the
566 * timer interrupt). Full topology setup happens at smp_init()
567 * time - but meanwhile we still have a functioning scheduler.
568 */
569 sched_init();
570 /*
571 * Disable preemption - early bootup scheduling is extremely
572 * fragile until we cpu_idle() for the first time.
573 */
574 preempt_disable();
575 if (WARN(!irqs_disabled(),
576 "Interrupts were enabled *very* early, fixing it\n"))
577 local_irq_disable();
578 idr_init_cache();
579 rcu_init();
580 context_tracking_init();
581 radix_tree_init();
582 /* init some links before init_ISA_irqs() */
583 early_irq_init();
584 init_IRQ();
585 tick_init();
586 rcu_init_nohz();
587 init_timers();
588 hrtimers_init();
589 softirq_init();
590 timekeeping_init();
591 time_init();
592 sched_clock_postinit();
593 perf_event_init();
594 profile_init();
595 call_function_init();
596 WARN(!irqs_disabled(), "Interrupts were enabled early\n");
597 early_boot_irqs_disabled = false;
598 local_irq_enable();
599
600 kmem_cache_init_late();
601
602 /*
603 * HACK ALERT! This is early. We're enabling the console before
604 * we've done PCI setups etc, and console_init() must be aware of
605 * this. But we do want output early, in case something goes wrong.
606 */
607 console_init();
608 if (panic_later)
609 panic("Too many boot %s vars at `%s'", panic_later,
610 panic_param);
611
612 lockdep_info();
613
614 /*
615 * Need to run this when irqs are enabled, because it wants
616 * to self-test [hard/soft]-irqs on/off lock inversion bugs
617 * too:
618 */
619 locking_selftest();
620
621#ifdef CONFIG_BLK_DEV_INITRD
622 if (initrd_start && !initrd_below_start_ok &&
623 page_to_pfn(virt_to_page((void *)initrd_start)) < min_low_pfn) {
624 pr_crit("initrd overwritten (0x%08lx < 0x%08lx) - disabling it.\n",
625 page_to_pfn(virt_to_page((void *)initrd_start)),
626 min_low_pfn);
627 initrd_start = 0;
628 }
629#endif
630 page_cgroup_init();
631 debug_objects_mem_init();
632 kmemleak_init();
633 setup_per_cpu_pageset();
634 numa_policy_init();
635 if (late_time_init)
636 late_time_init();
637 sched_clock_init();
638 calibrate_delay();
639 pidmap_init();
640 anon_vma_init();
641 acpi_early_init();
642#ifdef CONFIG_X86
643 if (efi_enabled(EFI_RUNTIME_SERVICES))
644 efi_enter_virtual_mode();
645#endif
646#ifdef CONFIG_X86_ESPFIX64
647 /* Should be run before the first non-init thread is created */
648 init_espfix_bsp();
649#endif
650 thread_info_cache_init();
651 cred_init();
652 fork_init(totalram_pages);
653 proc_caches_init();
654 buffer_init();
655 key_init();
656 security_init();
657 dbg_late_init();
658 vfs_caches_init(totalram_pages);
659 signals_init();
660 /* rootfs populating might need page-writeback */
661 page_writeback_init();
662 proc_root_init();
663 cgroup_init();
664 cpuset_init();
665 taskstats_init_early();
666 delayacct_init();
667
668 check_bugs();
669
670 sfi_init_late();
671
672 if (efi_enabled(EFI_RUNTIME_SERVICES)) {
673 efi_late_init();
674 efi_free_boot_services();
675 }
676
677 ftrace_init();
678
679 /* Do the rest non-__init'ed, we're now alive */
680 rest_init();
681}2.2第500行:init_task是一个全局变量,其类型是INIT_TASK,它的定义位于include/linux/init_task.h中,内如如下:
#define INIT_TASK(tsk) \
174{ \
175 .state = 0, \
176 .stack = &init_thread_info, \
177 .usage = ATOMIC_INIT(2), \
178 .flags = PF_KTHREAD, \
179 .prio = MAX_PRIO-20, \
180 .static_prio = MAX_PRIO-20, \
181 .normal_prio = MAX_PRIO-20, \
182 .policy = SCHED_NORMAL, \
183 .cpus_allowed = CPU_MASK_ALL, \
184 .nr_cpus_allowed= NR_CPUS, \
185 .mm = NULL, \
186 .active_mm = &init_mm, \
187 .se = { \
188 .group_node = LIST_HEAD_INIT(tsk.se.group_node), \
189 }, \
190 .rt = { \
191 .run_list = LIST_HEAD_INIT(tsk.rt.run_list), \
192 .time_slice = RR_TIMESLICE, \
193 }, \
194 .tasks = LIST_HEAD_INIT(tsk.tasks), \
195 INIT_PUSHABLE_TASKS(tsk) \
196 INIT_CGROUP_SCHED(tsk) \
197 .ptraced = LIST_HEAD_INIT(tsk.ptraced), \
198 .ptrace_entry = LIST_HEAD_INIT(tsk.ptrace_entry), \
199 .real_parent = &tsk, \
200 .parent = &tsk, \
201 .children = LIST_HEAD_INIT(tsk.children), \
202 .sibling = LIST_HEAD_INIT(tsk.sibling), \
203 .group_leader = &tsk, \
204 RCU_POINTER_INITIALIZER(real_cred, &init_cred), \
205 RCU_POINTER_INITIALIZER(cred, &init_cred), \
206 .comm = INIT_TASK_COMM, \
207 .thread = INIT_THREAD, \
208 .fs = &init_fs, \
209 .files = &init_files, \
210 .signal = &init_signals, \
211 .sighand = &init_sighand, \
212 .nsproxy = &init_nsproxy, \
213 .pending = { \
214 .list = LIST_HEAD_INIT(tsk.pending.list), \
215 .signal = {{0}}}, \
216 .blocked = {{0}}, \
217 .alloc_lock = __SPIN_LOCK_UNLOCKED(tsk.alloc_lock), \
218 .journal_info = NULL, \
219 .cpu_timers = INIT_CPU_TIMERS(tsk.cpu_timers), \
220 .pi_lock = __RAW_SPIN_LOCK_UNLOCKED(tsk.pi_lock), \
221 .timer_slack_ns = 50000, /* 50 usec default slack */ \
222 .pids = { \
223 [PIDTYPE_PID] = INIT_PID_LINK(PIDTYPE_PID), \
224 [PIDTYPE_PGID] = INIT_PID_LINK(PIDTYPE_PGID), \
225 [PIDTYPE_SID] = INIT_PID_LINK(PIDTYPE_SID), \
226 }, \
227 .thread_group = LIST_HEAD_INIT(tsk.thread_group), \
228 .thread_node = LIST_HEAD_INIT(init_signals.thread_head), \
229 INIT_IDS \
230 INIT_PERF_EVENTS(tsk) \
231 INIT_TRACE_IRQFLAGS \
232 INIT_LOCKDEP \
233 INIT_FTRACE_GRAPH \
234 INIT_TRACE_RECURSION \
235 INIT_TASK_RCU_PREEMPT(tsk) \
236 INIT_TASK_RCU_TASKS(tsk) \
237 INIT_CPUSET_SEQ(tsk) \
238 INIT_RT_MUTEXES(tsk) \
239 INIT_VTIME(tsk) \
240}
(1) init_task是内核中所有进程、线程的task_struct雏形,在内核初始化过程中,通过静态定义构造出了一个task_struct接口,取名为init_task,然后再内核初始化的后期,通过rest_init()函数新建了内核init线程,kthreadd内核线程。
内核init线程,最终执行/sbin/init进程,变为所有用户态程序的根进程(pstree命令显示)
内核kthreadd内核线程,变为所有内核态其他守护线程的父线程。所以init_task决定了系统所有进程、线程的基因
(2) 内核在初始化过程中,按照1所描述,当创建完init和kthreadd内核线程后,内核会发生调度执行,此时内核将使用该init_task作为其task_struct结构体描述符,当系统无事可做时,会调度其执行, 此时该内核会变为idle进程,让出CPU,自己进入睡眠,不停的循环,查看init_task结构体,其comm字段为swapper,作为idle进程的描述符。(来自http://www.blogbus.com/wanderer-zjhit-logs/172385885.html)
2.2第561行:分析trap_init()。
//在文件arch/arm/kernel/Traps.c中:
void __init trap_init(void)
{
extern void __trap_init(void *);
__trap_init((void *)vectors_base());
//#define vectors_base() ((cr_alignment & CR_V) ? 0xffff0000 : 0)
//从head-armv.S的分析中,知道cr_alignment = 11 0001 0111 0111
//vectors_base() 得到 0xffff0000
//__trap_init()函数分析见后
if (vectors_base() != 0)
printk(KERN_DEBUG "Relocating machine vectors to 0x%08x\n",
vectors_base());
#ifdef CONFIG_CPU_32
modify_domain(DOMAIN_USER, DOMAIN_CLIENT);
#endif
}
//文件linux/arch/arm/kernel/entry-armv.S
.equ __real_stubs_start, .LCvectors + 0x200
.LCvectors: swi SYS_ERROR0
b __real_stubs_start + (vector_undefinstr - __stubs_start)
ldr pc, __real_stubs_start + (.LCvswi - __stubs_start)
b __real_stubs_start + (vector_prefetch - __stubs_start)
b __real_stubs_start + (vector_data - __stubs_start)
b __real_stubs_start + (vector_addrexcptn - __stubs_start)
b __real_stubs_start + (vector_IRQ - __stubs_start)
b __real_stubs_start + (vector_FIQ - __stubs_start)
ENTRY(__trap_init)
stmfd sp!, {r4 - r6, lr}
adr r1, .LCvectors @ set up the vectors
ldmia r1, {r1, r2, r3, r4, r5, r6, ip, lr}
stmia r0, {r1, r2, r3, r4, r5, r6, ip, lr}
add r2, r0, #0x200
adr r0, __stubs_start @ copy stubs to 0x200
adr r1, __stubs_end
1: ldr r3, [r0], #4
str r3, [r2], #4
cmp r0, r1
blt 1b
LOADREGS(fd, sp!, {r4 - r6, pc})
//在文件assembler.h中
/*
* LOADREGS - ldm with PC in register list (eg, ldmfd sp!, {pc})
*/
#ifdef __STDC__
#define LOADREGS(cond, base, reglist...)\
ldm##cond base,reglist
#else
#define LOADREGS(cond, base, reglist...)\
ldm/**/cond base,reglist
#endif
2.3 第584行:分析init_IRQ()。
//在文件irq.c中,该函数主要对内核数据结构irq_desc[]和fiqdesc[]数据结构进行了初始化,同时对fiq的堆栈指针进行了设置。另外对DMA进行了初始化,初始化代码如下:
void __init init_dma(void)
{
/* Thomas Wong - we'll replace this with our routine
arch_dma_init(dma_chan);
*/
dma_t *dma;
int i;
// initialize dma channel data structures
for (i = 0, dma = dma_chan; i < MAX_DMA_CHANNELS; i++, dma++)
{
dma->allocated = 0;
}
// initialize DMA module
_reg_DMA_DIMR = 0x7FF; // disable all interrupts
_reg_DMA_DBTOCR = 0; // disable burst time-out
// disable all channels
{
int i;
for (i=0; i<MAX_DMA_CHANNELS; i++)
*(((P_VU32)&_reg_DMA_CCR0) + i * DMA_REG_SET_OFS) = 0;
}
// register interrupt handler (don't use request_irq)
dma_irq.handler = dma_intr_handler;
setup_arm_irq(61, &dma_irq);
//该函数中,语句desc->unmask(irq),通过写ARM的寄存器来使能该中断号
dma_err_irq.handler = dma_err_intr_handler;
setup_arm_irq(60, &dma_err_irq);
// enable DMA module
_reg_DMA_DCR = 1;
}(来自http://blog.sina.com.cn/s/blog_03225300010120df.html)
2.4 第680行:rest_init()
该函数的最后将调用一个函数叫rest_init(),它执行完,内核就起来了,现在我们来看一下rest_init()函数,它也在文件init/main.c中,它的前面几行是:
static void noinline __init_refok rest_init(void) __releases(kernel_lock)
{
int pid;
kernel_thread(kernel_init, NULL, CLONE_FS | CLONE_SIGHAND);其
中函数kernel_thread定义在文件arch/ia64/kernel/process.c中,用来启动一个内核线程,这里的
kernel_init是要执行的函数的指针,NULL表示传递给该函数的参数为空,CLONE_FS |
CLONE_SIGHAND为do_fork产生线程时的标志,表示进程间的fs信息共享,信号处理和块信号共享,然后我就屁颠屁颠地追随到
kernel_init函数了,现在来瞧瞧它都做了什么好事,它的完整代码如下:
static int __init kernel_init(void * unused)
{
lock_kernel();
/*
* init can run on any cpu.
*/
set_cpus_allowed_ptr(current, CPU_MASK_ALL_PTR);
/*
* Tell the world that we're going to be the grim
* reaper of innocent orphaned children.
* We don't want people to have to make incorrect
* assumptions about where in the task array this
* can be found.
*/
init_pid_ns.child_reaper = current;
cad_pid = task_pid(current);
smp_prepare_cpus(setup_max_cpus);
do_pre_smp_initcalls();
smp_init();
sched_init_smp();
cpuset_init_smp();
do_basic_setup();
/*
* check if there is an early userspace init. If yes, let it do all
* the work
*/
if (!ramdisk_execute_command)
ramdisk_execute_command = "/init";
if (sys_access((const char __user *) ramdisk_execute_command, 0) != 0) {
ramdisk_execute_command = NULL;
prepare_namespace();
}
/*
* Ok, we have completed the initial bootup, and
* we're essentially up and running. Get rid of the
* initmem segments and start the user-mode stuff..
*/
init_post();
return 0;
}在kernel_init函数的一开始就调用了lock_kernel()函数,当编译时选上了CONFIG_LOCK_KERNEL,就加上大内核锁,否
则啥也不做,紧接着就调用了函数set_cpus_allowed_ptr,由于这些函数对init进程的调起还是有影响的,我们还是一个一个来瞧瞧吧,
不要忘了啥东东最好,
static inline int set_cpus_allowed_ptr(struct task_struct *p,
const cpumask_t *new_mask)
{
if (!cpu_isset(0, *new_mask))
return -EINVAL;
return 0;
}这函数其实就调用了cpu_isset宏,定义在文件”include/linux/cpumask.h中,如下:
#define cpu_isset(cpu, cpumask) test_bit((cpu), (cpumask).bits)再来看看set_cpus_allowed_ptr的第二个参数类型吧,也定义在文件include/linux/cpumask.h中,具体如下:
typedef struct { DECLARE_BITMAP(bits, NR_CPUS); } cpumask_t;接着尾随着DECLAR_BITMAP宏到文件include/linux/types.h中,定义如下:
#define DECLARE_BITMAP(name,bits) \
unsigned long name[BITS_TO_LONGS(bits)]而宏BITS_TO_LONGS定义在文件include/linux/bitops.h中,实现如下:
#define BITS_TO_LONGS(nr) DIV_ROUND_UP(nr, BITS_PER_BYTE * sizeof(long))DIV_ROUND_UP宏定义在文件include/linux/kernel.h中,BITS_PER_BYTE 宏定义在文件include/linux/bitops.h中,实现如下:
#define DIV_ROUND_UP(n,d) (((n) + (d) - 1) / (d))
#define BITS_PER_BYTE 8即当NR_CPUS为1~32时,cpumask_t类型为
struct {
unsigned long bits[1];
}然后来看看在set_cpus_allowed_ptr(current, CPU_MASK_ALL_PTR);中的 CPU_MASK_ALL_PTR宏,定义在include/linux/cpumask.h中:
#define CPU_MASK_ALL_PTR (&CPU_MASK_ALL)而CPU_MASK_ALL宏也定义在文件include/linux/cpumask.h中:
#define CPU_MASK_ALL \
(cpumask_t) { { \
[BITS_TO_LONGS(NR_CPUS)-1] = CPU_MASK_LAST_WORD \
} }NR_CPUS宏定义在文件include/linux/threads.h中,实现如下:
#ifdef CONFIG_SMP
#define NR_CPUS CONFIG_NR_CPUS
#else
#define NR_CPUS 1
#endifCPU_MASK_LAST_WORD宏定义在文件include/linux/cpumask.h中,实现如下:
#define CPU_MASK_LAST_WORD BITMAP_LAST_WORD_MASK(NR_CPUS)BITMAP_LAST_WORD_MASK(NR_CPUS)宏定义在文件include/linux/bitmap.h中,实现如下:
#define BITMAP_LAST_WORD_MASK(nbits) \
( \
((nbits) % BITS_PER_LONG) ? \
(1ULcpu_isset(0,CPU_MASK_ALL_PTR)-->test_bit(0,CPU_MASK_ALL_PTR.bits)即当NR_CPUS为n时,就把usigned long bits[0]的第n位置1,应该就如注释所说的,init能运行在任何CPU上吧。
现在kernel_init中的set_cpus_allowed_ptr(current, CPU_MASK_ALL_PTR);分析完了,我们接着往下看,首先 init_pid_ns.child_reaper = current; init_pid_ns定义在kernel/pid.c文件中。
struct pid_namespace init_pid_ns = {
.kref = {
.refcount = ATOMIC_INIT(2),
},
.pidmap = {
[ 0 ... PIDMAP_ENTRIES-1] = { ATOMIC_INIT(BITS_PER_PAGE), NULL }
},
.last_pid = 0,
.level = 0,
.child_reaper = &init_task,
};它是一个pid_namespace结构的变量,先来看看pid_namespace的结构,它定义在文件
include/linux/pid_namespace.h中,具体定义如下:
struct pid_namespace {
struct kref kref;
struct pidmap pidmap[PIDMAP_ENTRIES];
int last_pid;
struct task_struct *child_reaper;
struct kmem_cache *pid_cachep;
unsigned int level;
struct pid_namespace *parent;
#ifdef CONFIG_PROC_FS
struct vfsmount *proc_mnt;
#endif
};即把当前进程设为接受其它孤儿进程的进程,然后取得该进程的进程ID,如:
cad_pid = task_pid(current);
然后调用 smp_prepare_cpus(setup_max_cpus);如果编译时没有指定CONFIG_SMP,它什么也不做,接着往下看,调用do_pre_smp_initcalls()函数,它定义在init/main.c文件中,实现如下:
static void __init do_pre_smp_initcalls(void)
{
extern int spawn_ksoftirqd(void);
migration_init();
spawn_ksoftirqd();
if (!nosoftlockup)
spawn_softlockup_task();
}其中migration_init()定义在文件include/linux/sched.h中,具体实现如下:
#ifdef CONFIG_SMP
void migration_init(void);
#else
static inline void migration_init(void)
{
}
#endif好像什么也没有做,然后是调用spawn_ksoftirqd()函数,定义在文件kernel/softirq.c中,代码如下:
__init int spawn_ksoftirqd(void)
{
void *cpu = (void *)(long)smp_processor_id();
int err = cpu_callback(&cpu_nfb, CPU_UP_PREPARE, cpu);
BUG_ON(err == NOTIFY_BAD);
cpu_callback(&cpu_nfb, CPU_ONLINE, cpu);
register_cpu_notifier(&cpu_nfb);
return 0;
}在该函数中,首先调用smp_processor_id函数获得当前CPU的ID并把它赋值给变量cpu,然后把cpu连同&cpu_nfb,CPU_UP_PREPARE传递给函数cpu_callback,我们先看cpu_callback的前几行:
static int __cpuinit cpu_callback(struct notifier_block *nfb,
unsigned long action,
void *hcpu)
{
int hotcpu = (unsigned long)hcpu;
struct task_struct *p;
switch (action) {
case CPU_UP_PREPARE:
case CPU_UP_PREPARE_FROZEN:
p = kthread_create(ksoftirqd, hcpu, "ksoftirqd/%d", hotcpu);
if (IS_ERR(p)) {
printk("ksoftirqd for %i failed\n", hotcpu);
return NOTIFY_BAD;
}
kthread_bind(p, hotcpu);
per_cpu(ksoftirqd, hotcpu) = p;
break;从上述代码可以看出当action为CPU_PREPARE时,将创建一个内核线程并把它赋值给p,该进程所要运行的函数为ksoftirqd,传递给该函数的参数为hcpu,而紧跟其后的”ksoftirqd/%d”,hotcpu为该进程的名字参数,这就是我们在终端用命令ps -ef | grep ksoftirqd所看到的线程;如果进程创建失败,打印出错信息,否则把创建的线程p绑定到当前CPU的ID上,这就是 kthread_bind(p,hotcpu)所做的,接下来的行为:
case CPU_ONLINE:
case CPU_ONLINE_FROZEN:
wake_up_process(per_cpu(ksoftirqd, hotcpu));
break;即在spawn_ksoftirqd函数中cpu_callback(&cpu_nfb, CPU_ONLINE,
cpu);的action为CPU_ONLINE时,将调用wake_up_process函数来唤醒当前CPU上的ksoftirqd进程。最后调用 register_cpu_notifier(&cpu_nfb);其实也没做什么,只是简单的返回0。返回到
do_pre_smp_initcalls函数中,接着往下看:
if (!nosoftlockup)
spawn_softlockup_task();
spawn_softlockup_task()函数定义在文件include/linux/sched.h中,是个空函数。
到
现在为止,do_pre_smp_initcalls分析完了,它主要就是创建进程ksoftirqd,把它绑定到当前CPU上,然后再把该进程拷贝给每
个CPU,并唤醒所有CPU上的进程ksoftirqd,就是当我们执行ps -ef | grep ksoftirqd的时候所看到的:
root 4 2 0 08:30 ? 00:00:03 [ksoftirqd/0]
root 7 2 0 08:30 ? 00:00:02 [ksoftirqd/1]
革命尚未成功,同志仍需努力!接着享受吧,呵呵!
现在到了kernel_init函数中的smp_init();了
如果在编译时没有选择CONFIG_SMP,若定义CONFIG_X86_LOCAL_APIC则去调用APIC_init_uniprocessor()函数,否则什么也不做,具体代码定义在文件init/main.c中:
#ifndef CONFIG_SMP
#ifdef CONFIG_X86_LOCAL_APIC
static void __init smp_init(void)
{
APIC_init_uniprocessor();
}
#else
#define smp_init() do { } while (0)
#endif如果在编译时选择了CONFIG_SMP呢,那么它的实现就如下喽:
/* Called by boot processor to activate the rest. */
static void __init smp_init(void)
{
unsigned int cpu;
/* FIXME: This should be done in userspace --RR */
for_each_present_cpu(cpu) {
if (num_online_cpus() >= setup_max_cpus)
break;
if (!cpu_online(cpu))
cpu_up(cpu);
}
/* Any cleanup work */
printk(KERN_INFO "Brought up %ld CPUs\n", (long)num_online_cpus());
smp_cpus_done(setup_max_cpus);
}来看看这个函数的,for_each_present_cpu(cpu)宏在文件include/linux/cpumask.h中实现:
#define for_each_present_cpu(cpu) for_each_cpu_mask((cpu), cpu_present_map)而for_each_cpu_mask(cpu,mask)宏也在文件include/linux/cpumask.h中实现:
#if NR_CPUS > 1
#define for_each_cpu_mask(cpu, mask) \
for ((cpu) = first_cpu(mask); \
(cpu) < NR_CPUS; \
(cpu) = next_cpu((cpu), (mask)))
#else /* NR_CPUS == 1 */
#define for_each_cpu_mask(cpu, mask) \
for ((cpu) = 0; (cpu) < 1; (cpu)++, (void)mask)
#endif /* NR_CPUS */即对于每个cpu都要执行大括号里的语句,如果当前cpu没激活就把它激活的,该函数然后打印一些cpu信息,如当前激活的cpu数目。
kernel_init中紧跟smp_init()函数后的是sched_init_smp()函数和do_basic_setup()函数,而其后便是最后一个函数init_post(),在该函数中将调起init进程。
(转载:来自http://os.chinaunix.net/a2010/0120/999/000000999958.shtml)
第三部分:自己对“Linux系统启动过程”的理解,idle进程、1号进程是怎么来的。
3.1 自己对“Linux系统启动过程”的理解
Linux系统启动前,首先会做很多硬件初始化动作,它由BIOS程序完成,之后控制权交给了引导程序Bootloader,引导程序Bootloader负责操作系统的初始化,比如指定kernel、initrd和root所在的分区和目录,然后Linux内核开始启动,在start_kernel函数之前,是很多做初始化的汇编指令,它之后是C代码的操作系统初始化。一般分两阶段启动,先是利用initrd的内存文件系统,然后切换到硬盘文件系统继续启动。initrd文件的功能主要有两个:1、提供开机必需的但kernel文件(即vmlinuz)没有提供的驱动模块(modules) 2、负责加载硬盘上的根文件系统并执行其中的/sbin/init程序进而将开机过程持续下去。
3.2 idle进程、1号进程是怎么来的
3.2.1 idle号进程:
当Power on PC时,BIOS的代码开始执行,然后是Linux初始化的代码,这其中大约很长一段时间Linux都没有进程这一概念,但是这不影响CPU执行它的二进制代码。如果不是多任务以及进程调度的需要,Linux内核可以一直这样走下去。
但是因为多任务的需求,Linux必须能支持任务这一特性,任务即进程,或者更简单地说由task_struct对象实例所代表的一段代码的集合,用以完成特定的任务。所以Linux内核初始化过程中必须为进程以及进程调度做准备。
init_task进程在Linux中属于一个比较特殊的进程,它是内核开发者人为制造出来的,而不是其他进程通过do_fork来完成。init_task对象的初始化在内核代码中由下面代码来完成:
<arch/x86/kernel/init_task.c>
struct task_struct init_task = INIT_TASK(init_task);如果仔细考察INIT_TASK宏的细节,会发现很多有趣的东西,比如inti_task所对应的内核栈,在INIT_TASK宏中由下列代码指定:
.stack = &init_thread_info
可以猜想init_task进程的内核栈一定是通过静态方式分配的,事实上也的确如此:
<arch/x86/kernel/init_task.c>
union thread_union init_thread_union __init_task_data =
{ INIT_THREAD_INFO(init_task) };init_thread_info定义中的__init_task_data表明该内核栈所在的区域位于内核映像的init data区,我们可以通过编译完内核后所产生的System.map来看到该变量及其对应的逻辑地址:
root@build-server:/boot# cat System.map-3.1.6 | grep init_thread_union
ffffffff81a00000 D init_thread_union
这意味着init_task.stack = 0xffffffff81a00000.
Linux在无进程概念的情况下将一直从初始化部分的代码执行到start_kernel,然后再到其最后一个函数调用rest_init。
从rest_init开始,Linux开始产生进程,因为init_task是静态制造出来的,pid=0,它试图将从最早的汇编代码一直到start_kernel的执行都纳入到init_task进程上下文中。在rest_init函数中,内核将通过下面的代码产生第一个真正的进程(pid=1):
<init/main.c>
static noinline void __init_refok rest_init(void)
{
...
kernel_thread(kernel_init, NULL, CLONE_FS | CLONE_SIGHAND);
...
cpu_idle();
}kernel_init函数最有意思的地方在于它会通过调用kernel_execve来执行根文件系统下的/sbin/init文件(所以此前系统根文件系统必须已经就绪),kernel_execve对用户空间程序/sbin/init的调用发起自int $0x80,这是个从内核空间发起的系统调用,与call_usermodehelper函数本质上是完全一样的。
而此时init_task的任务基本上已经完全结束了,它将沦落为一个idle task,事实上在更早前的sched_init()函数中,通过init_idle(current, smp_processor_id())函数的调用就已经把init_task初始化成了一个idle task,init_idle函数的第一个参数current就是&init_task,在init_idle中将会把init_task加入到cpu的运行队列中,这样当运行队列中没有别的就绪进程时,init_task(也就是idle task)将会被调用,它的核心是一个while(1)循环,在循环中它将会调用schedule函数以便在运行队列中有新进程加入时切换到该新进程上。
(来自http://blog.csdn.net/hardy_2009/article/details/7383815)
1号进程:
init是个普通的用户态进程,它是Unix系统内核初始化与用户态初始化的接合点,它是所有process的祖宗。在运行init以前是内核态初始化,该过程(内核初始化)的最后一个动作就是运行/sbin/init可执行文件。从init process运行开始进入Unix系统的用户态初始化。我对整个系统初始化的定义是从开机到屏幕上出现登录界面为止。这整个过程被init一分为二。当然init不单单启动了用户态的初始化,而且它在系统运行的整个期间都扮演着非常重要的角色。比如
在运行当中,具有root权限的用户可以通过再次运行init来切换到不同的运行级别(run level)
init process有认领系统中的所有孤儿进程的责任
当root权限用户想通过按Ctrl-Alt-Del三键来重启系统,也是由init最终来处理的
如果你想要一个daemon进程有这样的效果,它在整个系统运行期间一直要运行,即使它由于各种各样的原因(如在某种情况下它出错而退出了,或被某个用户kill掉了)停止运行了,也希望能马上被再次启动(当然不是依靠人力来手工启动),你可以在init运行的配置文件中加入类是与下面的一行:
myrun::ondemand:/home/wzhou/mydaemon
则/home/wzhou/mydaemon这个脚本只要系统在运行,它必然也在运行。即使有人把它kill掉,等一会儿马上又会被init process启动
等等
而这一切都依赖于init process。
(来自Linux-init-process-analyse.pdf)














 307
307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









