










这个场景的前提是:比如一大批手机号码 需要分区,就是确定那个号码是那个省份的,所以在Maptask阶段是要把所有的省份的号码全部放在一个Map里面,然后提交给reducetask去处理,但是默认的是一个reducetask。 这时候就需要重写Partitioner的方法实现Maptask的去处。
package cn.itcast.bigdata.mr.provinceflow;
import java.util.HashMap;
import org.apache.commons.collections.map.HashedMap;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* Partitioner<K2, V2>
* 对应的是Map 输出的类型
* @author PYF
*
*/
public class ProvicePartitioner extends Partitioner<Text, FlowBean>
{
//这是自己造的一个数据 字典 就是判断一个号码的前几位是哪个省的 也就是归属地。 如果可以的话肯定是通过数据库 相结合 这里只是模拟而已
public static HashMap<String, Integer> proviceDict=new HashMap<String,Integer>();
static{
proviceDict.put("138", 0);
proviceDict.put("139", 1);
proviceDict.put("136", 2);
proviceDict.put("137", 3);
}
@Override
public int getPartition(Text key, FlowBean value, int numPartitions)
{
String profix = key.toString().substring(0, 3);
Integer proviceId = proviceDict.get(profix);
return proviceId==null?4:proviceId;
}
}
2.在主程序中设置
/指定我们自定义的数据分区器
job.setPartitionerClass(ProvicePartitioner.class);
//指定相应数量的Reducetask 相应于数据分区数量的
job.setNumReduceTasks(5);
3.结果
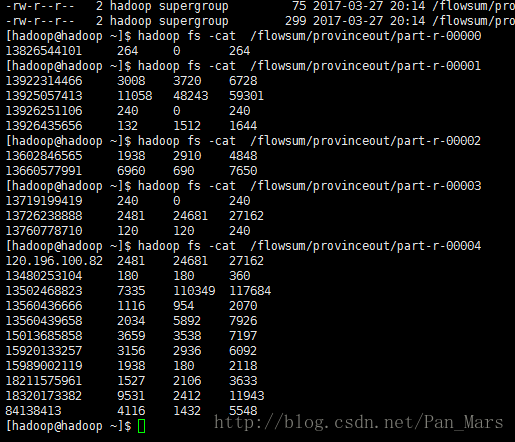
注意:part-t-00000 —->part-t-00004 这五个文件是对应的job.setNumReduceTasks(5);
不足之处,望批评指正,能力有限。














 1442
1442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









