







When a transaction updates a row, it puts a lock so that no one can update the same row until it commits. When another transaction issues an update to the same row, it waits until the first one either commits or rolls back. After the first transaction performs a commit or rollback, the update by the second transaction is executed immediately, since the lock placed by the first transaction is now gone. How exactly does this locking mechanism work? Several questions come to mind in this context:
If you are interested to learn about all this, please read on.
Lock Manager
Since locks convey information on who has what rows modified but not committed, anyone interested in making the update much check with some sort of system that is available across the entire database. So, it makes perfect sense to have a central locking system in the database, doesn’t it? But, when you think about it, a central lock manager can quickly become a single point of contention in a busy system where a lot of updates occur. Also, when a large number of rows are updated in a single transaction, an equally large number of locks will be required as well. The question is: how many? One can guess; but it will be at best a wild one. What if you guessed on the low side and the supply of available locks is depleted? In that case some transactions can’t get locks and therefore will have to wait (or, worse, abort). Not a pleasant thought in a system that needs to be scalable. To counter such a travesty you may want to make the available supply of locks really high. What is the downside of that action? Since each lock would potentially consume some memory, and memory is finite, it would not be advisable to create an infinite supply of locks.
Some databases actually have a lock manager with a finite supply of such locks. Each transaction must ask to get a lock from it before beginning and relinquish locks to it at the completion. In those technologies, the scalability of application suffers immensely as a result of the lock manager being the point of contention. In addition, since the supply of locks is limited, the developers need to commit frequently to release the locks for other transactions. When a large number of rows have locks on them, the database replaces the row locks with a block level lock to cover all the rows in the block – a concept known as lock escalation. Oracle does not follow that approach. In Oracle, there no central lock manager, no finite limit on locks and there is no such concept called lock escalation. The developers commit only when there is a logical need to do so; not otherwise.
Lock Management in Oracle
So, how is that approach different in case of Oracle? For starters, there is no central lock manager. But the information on locking has to be recorded somewhere. Where then? Well, consider this: when a row is locked, it must be available to the session, which means the session’s server process must have already accessed and placed the block in the buffer cache prior to the transaction occurring. Therefore, what is a better place for putting this information than right there in the block (actually the buffer in the buffer cache) itself?
Oracle does precisely that – it records the information in the block. When a row is locked by a transaction, that nugget of information is placed in the header of the block where the row is located. When another transaction wishes to acquire the lock on the same row, it has to access the block containing the row anyway (as you learned in Part 1 of this series) and upon reaching the block, it can easily confirm that the row is locked from the block header. A transaction looking to update a row in a different block puts that information on the header of that block. There is no need to queue behind some single central resource like a lock manager. Since lock information is spread over multiple blocks instead of a single place, this mechanism makes transactions immensely scalable.
Being the smart reader you are, you are now hopefully excited to learn more or perhaps you are skeptical. You want to know the nuts and bolts of this whole mechanism and, more, you want proof. We will see all that in a moment.
Transaction Address
Before understanding the locks, you should understand clearly what a transaction is and how it is addressed. A transaction starts when an update to data such as insert, update or delete occurs (or the intention to do so, e.g. SELECT FOR UPDATE) and ends when the session issues a commit or rollback. Like everything else, a specific transaction should have a name or an identifier to differentiate it from another one of the same type. Each transaction is given a transaction ID. When a transaction updates a row (it could also insert a new row or delete an existing one; but we will cover that little later in this article), it records two things:
The old value is recorded in the undo segments while the new value is immediately updated in the buffer where the row is stored. The data buffer containing the row is updated regardless of whether the transaction is committed or not. Yes, let me repeat – the data buffer is updated as soon as the transaction modifies the row (before commit). If you didn’t know that, please see the Part 1 of this series.
Undo information is recorded in a circular fashion. When new undo is created, it is stored in the next available undo “slot”. Each transaction occupies a record in the slot. After all the slots are exhausted and a new transaction arrives, the next processing depends on the state of the transactions. If the oldest transaction occupying any of the other slots is no longer active (that is either committed or rolled back), Oracle will reuse that slot. If none of the transactions is inactive, Oracle will have to expand the undo tablespace to make room. In the former case (where a transaction is no longer active and its information in undo has been erased by a new transaction), if a long running query that started before the transaction occurred selects the value, it will get an ORA-1555 error. But that will be covered in a different article in the future. If the tablespace containing the undo segment can’t extend due to some reason (such as in case of the filesystem being completely full), the transaction will fail.
Speaking of transaction identifiers, it is in the form of three numbers separated by periods. These three numbers are:
This is sort of like the social security number of the transaction. This information is recorded in the block header. Let’s see the proof now through a demo.
Demo
First, create a table:
Insert some rows into the table.
Remember, this is a single transaction. It started at the “BEGIN” line and ended at “COMMIT”. The 10,000 rows were all inserted as a part of the same transaction. To know the transaction ID of this transaction, Oracle provides a special package - dbms_transaction. Here is how you use it. Remember, you must use it in the same transaction. Let’s see:
Wait? There is nothing. The transaction ID returned is null. How come?
If you followed the previous section closely, you will realize that the transaction ends when a commit or rollback is issued. The commit was issued inside the PL/SQL block. So, the transaction had ended before you called the dbms_transaction is package. Since there was no transaction, the package returned null.
Let’s see another demo. Update one row:
In the same session, check the transaction ID:
There you see – the transaction ID. The three numbers separated by period signify undo segment number, slot# and record# respectively. Now perform a commit:
Check the transaction ID again:
The transaction is gone so the ID is null, as expected.
Since the call to the package must be in the same transaction (and therefore in the same session), how can you check the transaction in a different session? In real life you will be asked to check transaction in other sessions, typically application sessions. Let’s do a slightly different test. Update the row one more time and check the transaction:
From a different session, check for active transactions. This information is available in the view V$TRANSACTION . There are several columns; but we will look at four of the most important ones:
Voila! You see the transaction id of the active transaction from a different session. Compare the above output to the one you got from the call to dbms_transaction package. You can see that the transaction identifier shows the same set of numbers.
Interested Transaction List
You must be eager to know about the section of the block header that contains information on locking and how it records it. It is a simple data structure called "Interested Transaction List" (ITL), a list that maintains information on transaction. The ITL contains several placeholders (or slots) for transactions. When a row in the block is locked for the first time, the transaction places a lock in one of the slots. In other words, the transaction makes it known that it is interested in some rows (hence the term "Interested Transaction List"). When a different transaction locks another set of rows in the same block, that information is stored in another slot and so on. When a transaction ends after a commit or a rollback, the locks are released and the slot which was used to mark the row locks in the block is now considered free (although it is not updated immediately - fact about which you will learn later in a different installment).
[Updated Jan 22, 2011] [Thank you, Randolph Geist ( info@www.sqltools-plusplus.org ) for pointing it out. I follow his blog http://oracle-randolf.blogspot.com/ , which is a treasure trove of information.
The row also stores a bit that represents the whether it is locked or not.
[end of Update Jan 22, 2011]
ITLs in Action
Let's see how ITLs really work. Here is an empty block. The block header is the only occupant of the block.
This is how the block looks like after a single row has been inserted:
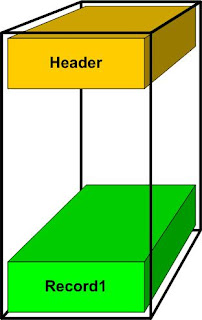
Note, the row was inserted from the bottom of the block. Now, a second row has been inserted:
A session comes in and updates the row Record1, i.e. it places a lock on the row, shown by the star symbol. The lock information is recorded in the ITL slot in the block header:

The session does not commit yet; so the lock is active. Now a second session - Session 2 - comes in and updates row Record2. It puts a lock on the record - as stored in the ITL slot.
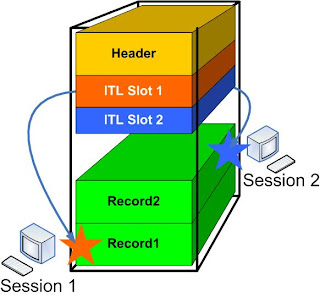
I have used two different colors to show the locks (as shown by the star symbol) and the color of the ITL entry.
As you can clearly see, when a transaction wants to update a specific row, it doesn’t have to go anywhere but the block header itself to know if the row is locked or not. All it has to do is to check the ITL slots. However ITL alone does not show with 100% accuracy that row is locked (again, something I will explain in a different installment). The transaction must go to the undo segment to check if the transaction has been committed. How does it know which specifci part of the undo segment to go to? Well, it has the information in the ITL entry. If the row is indeed locked, the transaction must wait and retry. As soon as the previous transaction ends, the undo information is updated and the waiting transaction completes its operation.
So, there is in fact a queue for the locks, but it's at the block level, not at the level of the entire database or even the segment.
Demo
The proof is in the pudding. Let’s see all this through a demo. Now that you know the transaction entry, let’s see how it is stored in the block header. To do that, first, we need to know which blocks to look for. So, we should get the blocks numbers where the table is stored:
To check inside the block, we need to “dump” the contents of the block to a tracefile so that we can read it. From a different session issue a checkpoint so that the buffer data is now written to the dis:
Now dump the data blocks 3576 through 3583.
This will create a tracefile in the user dump destination directory. In case of Oracle 11g, the tracefile will be in the diag structure under /diag/rdbms///trace directory. It will be most likely the last tracefile generated. You can also get the precise name by getting the OS process ID of the session:
This is where the information on row locking is stored. Remember, the row locking information is known as
Interested Transaction List (ITL) and each ITL is stored in a “slot”. Here it shows two slots, which is the default number. Look for the one where the “Lck” column shows a value. It shows “1”, meaning one of the rows in the blocks is locked by a transaction. But, which transaction? To get that answer, note the value under the “Xid” column. It shows the transaction ID - 0x000a.019.00007c05. These numbers are in hexadecimal (as indicated by the 0x at the beginning of the number). Using the
scientific calculator
in Windows, I converted the values to decimal as 10, 25 and 31749 respectively. Do they sound familiar? Of course they do; they are exactly as reported by both the record in v$transaction and the
dbms_transaction.local_transaction_id function call.
Note the UBASQN (which is the undo block sequence#) value in the earlier output, which was 5639. Let’s revisit the ITL entries in the dump of block:
Look at the entry under the Uba column: 0x00c00288.1607.0e. As indicated by the “0x” at the beginning, these are in hexadecimal. Using a
scientific calculator
, let’s convert them. 1607 in hex means 5639 in decimal – the UBA Sequence# (UBASQN). The value “e” is 14 in decimal, which corresponds to the UBAREC. Finally the value 288 is 648 in decimal, which is the UBABLK. Now you see how the information is recorded in the block header and is also available to the DBA through the view V$TRANSACTION.
- Is there some kind of logical or physical structure called lock?
- How does the second transaction know when the first transaction has lifted the lock?
- Is there some kind of “pool” of such locks where transactions line up to get one?
- If so, do they line up to return it when they are done with the locking?
- Is there a maximum number of possible locks?
- Is there something called a block level lock? Since Oracle stores the rows in blocks, when all or the majority of rows in the blocks are locked by a single transaction, doesn’t it make sense for to lock the entire block to conserve the number of locks?
- The previous question brings up another question – does the number of active locks in the database at any point really matter?
If you are interested to learn about all this, please read on.
Lock Manager
Since locks convey information on who has what rows modified but not committed, anyone interested in making the update much check with some sort of system that is available across the entire database. So, it makes perfect sense to have a central locking system in the database, doesn’t it? But, when you think about it, a central lock manager can quickly become a single point of contention in a busy system where a lot of updates occur. Also, when a large number of rows are updated in a single transaction, an equally large number of locks will be required as well. The question is: how many? One can guess; but it will be at best a wild one. What if you guessed on the low side and the supply of available locks is depleted? In that case some transactions can’t get locks and therefore will have to wait (or, worse, abort). Not a pleasant thought in a system that needs to be scalable. To counter such a travesty you may want to make the available supply of locks really high. What is the downside of that action? Since each lock would potentially consume some memory, and memory is finite, it would not be advisable to create an infinite supply of locks.
Some databases actually have a lock manager with a finite supply of such locks. Each transaction must ask to get a lock from it before beginning and relinquish locks to it at the completion. In those technologies, the scalability of application suffers immensely as a result of the lock manager being the point of contention. In addition, since the supply of locks is limited, the developers need to commit frequently to release the locks for other transactions. When a large number of rows have locks on them, the database replaces the row locks with a block level lock to cover all the rows in the block – a concept known as lock escalation. Oracle does not follow that approach. In Oracle, there no central lock manager, no finite limit on locks and there is no such concept called lock escalation. The developers commit only when there is a logical need to do so; not otherwise.
Lock Management in Oracle
So, how is that approach different in case of Oracle? For starters, there is no central lock manager. But the information on locking has to be recorded somewhere. Where then? Well, consider this: when a row is locked, it must be available to the session, which means the session’s server process must have already accessed and placed the block in the buffer cache prior to the transaction occurring. Therefore, what is a better place for putting this information than right there in the block (actually the buffer in the buffer cache) itself?
Oracle does precisely that – it records the information in the block. When a row is locked by a transaction, that nugget of information is placed in the header of the block where the row is located. When another transaction wishes to acquire the lock on the same row, it has to access the block containing the row anyway (as you learned in Part 1 of this series) and upon reaching the block, it can easily confirm that the row is locked from the block header. A transaction looking to update a row in a different block puts that information on the header of that block. There is no need to queue behind some single central resource like a lock manager. Since lock information is spread over multiple blocks instead of a single place, this mechanism makes transactions immensely scalable.
Being the smart reader you are, you are now hopefully excited to learn more or perhaps you are skeptical. You want to know the nuts and bolts of this whole mechanism and, more, you want proof. We will see all that in a moment.
Transaction Address
Before understanding the locks, you should understand clearly what a transaction is and how it is addressed. A transaction starts when an update to data such as insert, update or delete occurs (or the intention to do so, e.g. SELECT FOR UPDATE) and ends when the session issues a commit or rollback. Like everything else, a specific transaction should have a name or an identifier to differentiate it from another one of the same type. Each transaction is given a transaction ID. When a transaction updates a row (it could also insert a new row or delete an existing one; but we will cover that little later in this article), it records two things:
- The new value
- The old value
The old value is recorded in the undo segments while the new value is immediately updated in the buffer where the row is stored. The data buffer containing the row is updated regardless of whether the transaction is committed or not. Yes, let me repeat – the data buffer is updated as soon as the transaction modifies the row (before commit). If you didn’t know that, please see the Part 1 of this series.
Undo information is recorded in a circular fashion. When new undo is created, it is stored in the next available undo “slot”. Each transaction occupies a record in the slot. After all the slots are exhausted and a new transaction arrives, the next processing depends on the state of the transactions. If the oldest transaction occupying any of the other slots is no longer active (that is either committed or rolled back), Oracle will reuse that slot. If none of the transactions is inactive, Oracle will have to expand the undo tablespace to make room. In the former case (where a transaction is no longer active and its information in undo has been erased by a new transaction), if a long running query that started before the transaction occurred selects the value, it will get an ORA-1555 error. But that will be covered in a different article in the future. If the tablespace containing the undo segment can’t extend due to some reason (such as in case of the filesystem being completely full), the transaction will fail.
Speaking of transaction identifiers, it is in the form of three numbers separated by periods. These three numbers are:
- Undo Segment Number where the transaction records its undo entry
- Slot# in the undo segment
- Sequence# (or wrap) in the undo slot
This is sort of like the social security number of the transaction. This information is recorded in the block header. Let’s see the proof now through a demo.
Demo
First, create a table:
SQL> create table itltest (col1 number, col2 char(8));
Insert some rows into the table.
SQL> begin 2 for i in 1..10000 loop 3 insert into itltest values (i,'x'); 4 end loop; 5 commit; 6 end; 7 /
Remember, this is a single transaction. It started at the “BEGIN” line and ended at “COMMIT”. The 10,000 rows were all inserted as a part of the same transaction. To know the transaction ID of this transaction, Oracle provides a special package - dbms_transaction. Here is how you use it. Remember, you must use it in the same transaction. Let’s see:
SQL> select dbms_transaction.local_transaction_id from dual;
LOCAL_TRANSACTION_ID
------------------------------------------------------------------------
1 row selected.
Wait? There is nothing. The transaction ID returned is null. How come?
If you followed the previous section closely, you will realize that the transaction ends when a commit or rollback is issued. The commit was issued inside the PL/SQL block. So, the transaction had ended before you called the dbms_transaction is package. Since there was no transaction, the package returned null.
Let’s see another demo. Update one row:
SQL> update itltest set col2 = 'y' where col1 = 1; 1 row updated.
In the same session, check the transaction ID:
SQL> select dbms_transaction.local_transaction_id from dual;
LOCAL_TRANSACTION_ID
-------------------------------------------------------------------------
3.23.40484
1 row selected.
There you see – the transaction ID. The three numbers separated by period signify undo segment number, slot# and record# respectively. Now perform a commit:
SQL> commit; Commit complete.
Check the transaction ID again:
SQL> select dbms_transaction.local_transaction_id from dual;
LOCAL_TRANSACTION_ID
-------------------------------------------------------------------------
1 row selected.
The transaction is gone so the ID is null, as expected.
Since the call to the package must be in the same transaction (and therefore in the same session), how can you check the transaction in a different session? In real life you will be asked to check transaction in other sessions, typically application sessions. Let’s do a slightly different test. Update the row one more time and check the transaction:
SQL> update itltest set col2 = 'y' where col1 = 1;
1 row updated.
SQL> select dbms_transaction.local_transaction_id from dual;
LOCAL_TRANSACTION_ID
-----------------------------------------------------------------------
10.25.31749
1 row selected.
From a different session, check for active transactions. This information is available in the view V$TRANSACTION . There are several columns; but we will look at four of the most important ones:
- ADDR – the address of the transaction, which is a raw value
- XIDUSN – the undo segment number
- XIDSLOT – the slot#
- XIDSQN – the sequence# or record# inside the slot
SQL> select addr, xidusn, xidslot, xidsqn 2 from v$transaction; ADDR XIDUSN XIDSLOT XIDSQN -------- ---------- ---------- ---------- 3F063C48 10 25 31749
Voila! You see the transaction id of the active transaction from a different session. Compare the above output to the one you got from the call to dbms_transaction package. You can see that the transaction identifier shows the same set of numbers.
Interested Transaction List
You must be eager to know about the section of the block header that contains information on locking and how it records it. It is a simple data structure called "Interested Transaction List" (ITL), a list that maintains information on transaction. The ITL contains several placeholders (or slots) for transactions. When a row in the block is locked for the first time, the transaction places a lock in one of the slots. In other words, the transaction makes it known that it is interested in some rows (hence the term "Interested Transaction List"). When a different transaction locks another set of rows in the same block, that information is stored in another slot and so on. When a transaction ends after a commit or a rollback, the locks are released and the slot which was used to mark the row locks in the block is now considered free (although it is not updated immediately - fact about which you will learn later in a different installment).
[Updated Jan 22, 2011] [Thank you, Randolph Geist ( info@www.sqltools-plusplus.org ) for pointing it out. I follow his blog http://oracle-randolf.blogspot.com/ , which is a treasure trove of information.
The row also stores a bit that represents the whether it is locked or not.
[end of Update Jan 22, 2011]
ITLs in Action
Let's see how ITLs really work. Here is an empty block. The block header is the only occupant of the block.

This is how the block looks like after a single row has been inserted:

Note, the row was inserted from the bottom of the block. Now, a second row has been inserted:

A session comes in and updates the row Record1, i.e. it places a lock on the row, shown by the star symbol. The lock information is recorded in the ITL slot in the block header:

The session does not commit yet; so the lock is active. Now a second session - Session 2 - comes in and updates row Record2. It puts a lock on the record - as stored in the ITL slot.
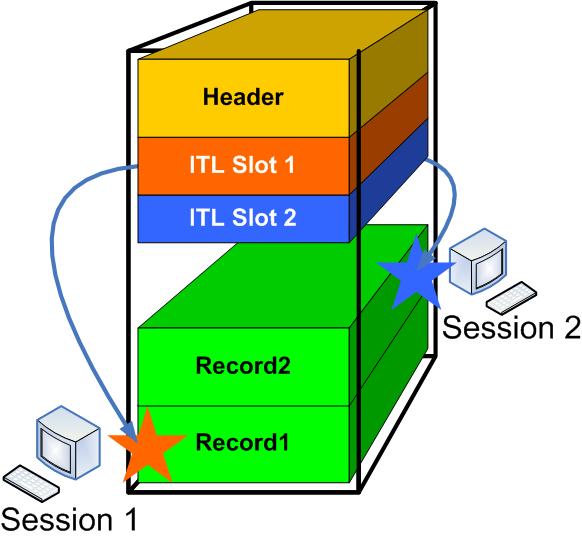
I have used two different colors to show the locks (as shown by the star symbol) and the color of the ITL entry.
As you can clearly see, when a transaction wants to update a specific row, it doesn’t have to go anywhere but the block header itself to know if the row is locked or not. All it has to do is to check the ITL slots. However ITL alone does not show with 100% accuracy that row is locked (again, something I will explain in a different installment). The transaction must go to the undo segment to check if the transaction has been committed. How does it know which specifci part of the undo segment to go to? Well, it has the information in the ITL entry. If the row is indeed locked, the transaction must wait and retry. As soon as the previous transaction ends, the undo information is updated and the waiting transaction completes its operation.
So, there is in fact a queue for the locks, but it's at the block level, not at the level of the entire database or even the segment.
Demo
The proof is in the pudding. Let’s see all this through a demo. Now that you know the transaction entry, let’s see how it is stored in the block header. To do that, first, we need to know which blocks to look for. So, we should get the blocks numbers where the table is stored:
SQL> select file_id, relative_fno, extent_id, block_id, blocks
2 from dba_extents
3 where segment_name = 'ITLTEST';
FILE_ID RELATIVE_FNO EXTENT_ID BLOCK_ID BLOCKS
---------- ------------ ---------- ---------- ----------
7 7 0 3576 8
7 7 1 3968 8
7 7 2 3976 8
7 7 3 3984 8
To check inside the block, we need to “dump” the contents of the block to a tracefile so that we can read it. From a different session issue a checkpoint so that the buffer data is now written to the dis:
SQL> alter system checkpoint;
Now dump the data blocks 3576 through 3583.
SQL> alter system dump datafile 7 block min 3576 block max 3583; System altered.
This will create a tracefile in the user dump destination directory. In case of Oracle 11g, the tracefile will be in the diag structure under /diag/rdbms///trace directory. It will be most likely the last tracefile generated. You can also get the precise name by getting the OS process ID of the session:
SQL> select p.spid 2 from v$session s, v$process p 3 where s.sid = (select sid from v$mystat where rownum < 2) 4 and p.addr = s.paddr 5 / SPID ------------------------ 9202 1 row selected.Now look for a file named _ora_9202.trc. Open the file in vi and search for the phrase “Itl”. Here is an excerpt from the file:
Itl Xid Uba Flag Lck Scn/Fsc 0x01 0x000a.019.00007c05 0x00c00288.1607.0e ---- 1 fsc 0x0000.00000000 0x02 0x0003.017.00009e24 0x00c00862.190a.0f C--- 0 scn 0x0000.02234e2b
This is how Oracle determines that there is a transaction has locked the row and correlates it to the various components in the other areas – mostly the undo segments to determne if it is active. Now that you know undo segments holds the transaction details, you may want to know more about the segment. Remember, the undo segment is just a segment, like any other table, indexes, etc. It resides in a tablespace, which is on some datafile. To find out the specifics of the segment, we will look into some more columns of the view V$TRANSACTION:
SQL> select addr, xidusn, xidslot, xidsqn, ubafil, ubablk, ubasqn, ubarec,
2 status, start_time, start_scnb, start_scnw, ses_addr
3 from v$transaction;
ADDR XIDUSN XIDSLOT XIDSQN UBAFIL UBABLK UBASQN
-------- ---------- ---------- ---------- ---------- ---------- ----------
UBAREC STATUS START_TIME START_SCNB START_SCNW SES_ADDR
---------- ---------------- -------------------- ---------- ---------- --------
3F063C48 10 25 31749 3 648 5639
14 ACTIVE 12/30/10 20:00:25 35868240 0 40A73784
1 row selected.
The columns with names starting with UBA show the undo block address information. Look at the above output. The UBAFIL shows the file#, which is “3” in this case. Checking for the file_id:
SQL> select * from dba_data_files
2> where file_id = 3;
FILE_NAME
-------------------------------------------------------------------------
FILE_ID TABLESPACE_NAME BYTES BLOCKS STATUS
---------- ------------------------------ ---------- ---------- ---------
RELATIVE_FNO AUT MAXBYTES MAXBLOCKS INCREMENT_BY USER_BYTES USER_BLOCKS
------------ --- ---------- ---------- ------------ ---------- -----------
ONLINE_
-------
+DATA/d112d2/datafile/undotbs1.260.722742813
3 UNDOTBS1 4037017600 492800 AVAILABLE
3 YES 3.4360E+10 4194302 640 4035969024 492672
ONLINE
1 row selected.
Itl Xid Uba Flag Lck Scn/Fsc 0x01 0x000a.019.00007c05 0x00c00288.1607.0e ---- 1 fsc 0x0000.00000000 0x02 0x0003.017.00009e24 0x00c00862.190a.0f C--- 0 scn 0x0000.02234e2b
Let’s see some more important columns of the view. A typical database will have many sessions; not just one. Each session may have an active transaction, which means you have to link sessions to transactions to generate meaningful information. The transaction information also contains the session link. Note the column SES_ADDR, which is the address of the session that issued the transaction. From that, you can get the session information
There you go – you now have the SID of the session. And now that you know the SID, you can look up any other relevant data on the session from the view V$SESSION.
Takeaways
Here is a summary of what you learned so far:
I hope you found it useful. As always, I will be grateful to know how you liked it. In the next installment we will examine how these ITLs could cause issues and how to identify or resolve them.
SQL> select sid, username 2 from v$session 3 where saddr = '40A73784'; SID USERNAME --- -------- 123 ARUP
There you go – you now have the SID of the session. And now that you know the SID, you can look up any other relevant data on the session from the view V$SESSION.
Takeaways
Here is a summary of what you learned so far:
- Transaction in Oracle starts with a data update (or intention to update) statement. Actually there are some exceptions which we will cover in a later article.
- It ends when a commit or rollback is issued
- A transaction is identified by a transaction ID (XID) which is a set of three numbers – undo segment#, undo slot# and undo record# - separated by periods.
- You can view the transaction ID in the session itself by callingdbms_transaction.local_transaction_id function.
- You can also check all the active transactions in the view v$transaction, where the columns XIDUSN, XIDSLOT and XIDSQN denote the undo segment#, undo slot# and undo rec# - the values that make up the transaction ID.
- The transaction information is also stored in the block header. You can check it by dumping the block and looking for the term “Itl”.
- The v$transaction view also contains the session address under SES_ADDR column, which can be used to join with the SADDR column of v$session view to get the session details.
- From the session details, you can find out other actions by the session such as the username, the SQL issues, the machine issued from, etc.
I hope you found it useful. As always, I will be grateful to know how you liked it. In the next installment we will examine how these ITLs could cause issues and how to identify or resolve them.
http://arup.blogspot.com/2011/01/how-oracle-locking-works.html














 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









