







安装NLTK
1.3 整合中文分词模块
按照使用的算法不同,下面介绍两大类中文分词模块
基于条件随机场(CRF)的中文分词算法的开源系统
基于张华平的NShort的中文分词算法的开源系统
安装Ltp Python组件
https://github.com/HIT-SCIR/ltp
下载源代码:wget https://github.com/HIT-SCIR/ltp/archive/v3.4.0.tar.gz
下载语言模型:http://ospm9rsnd.bkt.clouddn.com/model/ltp_data_v3.4.0.zip http://ospm9rsnd.bkt.clouddn.com/model/ltp_data_v3.3.0.zip
源代码和语言模型包括:中文分词、词性标注、未登录词识别、依存句法、语义角色标注几个模块
将项目与Python整合
pip install pyltp
部署语言模型库:解压
使用Ltp进行中文分词
(1)
# -*- coding: utf-8 -*-
import sys
import os
from pyltp import Segmentor
reload(sys)
sys.setdefaultencoding('utf-8')
model_path = "ltp3.4/cws.model"
segmentor = Segmentor()
segmentor.load(model_path)
words = segmentor.segment("在包含问题的所有解的解空间树中,按照深度优先搜索的策略,从根节点出发深度探索解空间树。")
print " | ".join(words)(2)分词结果的后处理
上述分词粒度过细,为了获得更精确的结果可以将错分的结果合并为专有名词。这就是分词结果的后处理过程,即一般外部用户词典的构成原理。
postdict = {"解 | 空间":"解空间",
"深度 | 优先":"深度优先"}
seg_sent = " | ".join(words)
for key in postdict:
seg_sent = seg_sent.replace(key, postdict[key])
print seg_sent(3)现在加入用户词典,词典中登录一些新词,如解空间
user_dict = "ltp3.4/fulluserdict.txt" #外部专有名词词典
segmentor1 = Segmentor()
segmentor1.load_with_lexicon(model_path, user_dict) #加载专有名词词典
sent = "在包含问题的所有解的解空间树中,按照深度优先搜索的策略,从根节点出发深度探索解空间树。"
words = segmentor.segment(sent)
print " | ".join(words)使用结巴分词模块
张华平的NShort的中文分词算法是目前大规模中文分词的主流算法。在商用领域,大多数搜索引擎公司都使用该算法作为主要的分词算法。具有算法原理简单、容易理解、便于训练、大规模分词的效率高、模型支持增量扩展、模型占用资源低等优势。
这里使用的结巴分词器是该算法的Python实现,结巴分词的算法核心就是Nshort中文分词算法。
https://github.com/fxsjy/jieba,结巴分词模块可支持如下三种分词方式:
精确模式,试图将句子最精确地切开,适合文本分析(类似Ltp的分词方式)
全模式:把句子中所有可以成词的词语都扫描出来,速度非常块,但是不能解决歧义
搜索引擎模式,在精确模式的基础上对长词再次切分,提高召回率,适合用于搜索引擎分词
支持繁体分词
支持基于概率的用户词典
(1)安装
pip install jieba
(2)使用结巴分词
# -*- coding: utf-8 -*-
import sys
import os
import jieba
reload(sys)
sys.setdefaultencoding('utf-8')
sent = "在包含问题的所有解的解空间树中,按照深度优先搜索的策略,从根节点出发深度探索解空间树。"
wordlist = jieba.cut(sent, cut_all=True) #全模式
print " | ".join(wordlist)
wordlist = jieba.cut(sent) #精确模式
print " | ".join(wordlist)
wordlist = jieba.cut_for_search(sent) #搜索引擎模式
print " | ".join(wordlist)在 | 包含 | 问题 | 的 | 所有 | 解 | 的 | 解 | 空间 | 树中 | , | 按照 | 深度 | 优先 | 搜索 | 的 | 策略 | , | 从根 | 节点 | 出发 | 深度 | 探索 | 解 | 空间 | 树 | 。
在 | 包含 | 问题 | 的 | 所有 | 解 | 的 | 解 | 空间 | 树中 | , | 按照 | 深度 | 优先 | 搜索 | 的 | 策略 | , | 从根 | 节点 | 出发 | 深度 | 探索 | 解 | 空间 | 树 | 。
(3)使用用户词典
○ → cat userdict.txt
解空间 5 n
解空间树 5 n
根结点 5 n
深度优先 5 n
jieba.load_userdict("userdict.txt")
wordlist = jieba.cut(sent, cut_all=True) #全模式
print " | ".join(wordlist)1.4 整合词性标注模块
词性标注(Part of speech tagging 或者 POS Tagging),有称为词类标注,是指判断出在一个句子中每个词所扮演的语法角色。例如,表示人、事物、地点或抽象概念的名称就是名词;表示动作或状态变化的词为动词;用来描写或修饰名词性成分或表示概念的性质、状态、特征或属性的词称为形容词,等等。
中文词性标注中影响词性标注精度的因素主要是要正确判断文本中那些常用词的词性。
一般而言,中文的词性标注算法比较统一,大多数使用HMM或最大熵算法,如结巴的词性标注。为了获得更高的精度,也有使用CRF算法的,如Ltp中的词性标注。
在一般的工程应用中,语料的中文分词和词性标注通常同时完成。
目前流行的中文词性标签有两个类:北大词性标注集和宾州词性标注集,它们各有千秋
Ltp3.3 词性标注
词性标注模块的文件名为pos.model
# -*- coding: utf-8 -*-
import sys
import os
from pyltp import *
reload(sys)
sys.setdefaultencoding('utf-8')
#已分好词
sent = "在 包含 问题 的 所有 解 的 解空间树 中 , 按照 深度优先 搜索 的 策略 , 从 根节点 出发 深度 探索 解空间树 。"
words = sent.split(" ")
postagger = Postagger() #实例化词性标注类
postagger.load('ltp3.4/pos.model')
postags = postagger.postag(words)
for word,postag in zip(words,postags):
print word+"/"+postag,安装StanfordNLP并编写Python接口类
https://stanfordnlp.github.io/CoreNLP/
http://nlp.stanford.edu/software/stanford-corenlp-full-2017-06-09.zip只携带了英文的语言模型包,中文部分的语言模型需要单独下载,
http://nlp.stanford.edu/software/stanford-chinese-corenlp-2017-06-09-models.jar
mkdir stanford-corenlp #解压到此目录
其中stanford-corenlp.jar为主执行文件
将stanford-chinese-corenlp-2017-06-09-models.jar中的中文模型全部解压到models目录中。其中pos-tagger目录下放置了词性标注的中文模型。
jar xvf ../../stanford-chinese-corenlp-2017-06-09-models.jar
https://nlp.stanford.edu/software/tagger.shtml
wget https://nlp.stanford.edu/software/stanford-postagger-full-2017-06-09.zip
执行命令的参考脚本
○ → cat stanford-postagger.sh
java -mx300m -cp 'stanford-postagger.jar:' edu.stanford.nlp.tagger.maxent.MaxentTagger -model $1 -textFile $2
执行./stanford-postagger.sh models/english-left3words-distsim.tagger sample-input.txt
○ → cat ../postest.txt
在 包含 问题 的 所有 解 的 解空间树 中 , 按照 深度优先 搜索 的 策略 , 从 根节点 出发 深度 探索 解空间树 。
○ → ./stanford-postagger.sh models/chinese-distsim.tagger ../postest.txt
Loading default properties from tagger models/chinese-distsim.tagger
Loading POS tagger from models/chinese-distsim.tagger ... done [1.5 sec].
在#P 包含#VV 问题#NN 的#DEC 所有#DT 解#VV 的#DEC 解空间树#NN 中#LC ,#PU 按照#P 深度优先#NN 搜索#NN 的#DEC 策略#NN ,#PU 从#P 根节点#NN 出发#VV 深度#JJ 探索#NN 解空间树#VV 。#PU
Tagged 23 words at 338.24 words per second.
进入stanford-corenlp
○ → java -mx5g -cp "./*" edu.stanford.nlp.tagger.maxent.MaxentTagger -model models/edu/stanford/nlp/models/pos-tagger/chinese-distsim/chinese-distsim.tagger -textFile ../postest.txt
在#P 包含#VV 问题#NN 的#DEC 所有#DT 解#VV 的#DEC 解空间树#NN 中#LC ,#PU 按照#P 深度优先#NN 搜索#NN 的#DEC 策略#NN ,#PU 从#P 根节点#NN 出发#VV 深度#JJ 探索#NN 解空间树#VV 。#PU
(1)新建stanford.py
# -*- coding: utf-8 -*-
import sys
import os
reload(sys)
sys.setdefaultencoding('utf-8')
# CoreNLP 3.6 jar包和中文模型包
# ejml-0.23.jar javax.json.jar jollyday.jar joda-time.jar jollyday.jar protobuf.jar slf4j.api.jar
# slf4j-simple.jar stanford-corenlp-3.6.0.jar xom.jar
class StanfordCoreNLP(): #所有StanfordNLP的父类
def __init__(self, jarpath):
self.root = jarpath
self.tempsrcpath = "tempsrc" #输入临时文件路径
self.jarlist = ["ejml-0.23.jar",
"javax.json.jar",
"jollyday.jar",
"joda-time.jar",
"protobuf.jar",
"slf4j-api.jar",
"slf4j-simple.jar",
"stanford-corenlp-3.8.0.jar",
"xom.jar"]
self.jarpath = ""
self.buildjars()
def buildjars(self): #根据root路径构建所有的jar包路径
#self.jarpath += self.root + "/*"
for jar in self.jarlist:
self.jarpath += self.root + jar + ":"
def savefile(self,path,sent): #创建临时文件存储路径
fp = open(path, "wb")
fp.write(sent)
fp.close()
def delfile(self, path):
os.remove(path)
#词性标注子类
class StanfordPOSTagger(StanfordCoreNLP):
def __init__(self, jarpath, modelpath):
StanfordCoreNLP.__init__(self, jarpath)
self.modelpath = modelpath
self.classfier = "edu.stanford.nlp.tagger.maxent.MaxentTagger"
self.delimiter = "/"
self.__buildcmd()
def __buildcmd(self):
self.cmdline = 'java -mx1g -cp "'+self.jarpath+'" ' + self.classfier+' -model "'+self.modelpath+'" -tagSeparator ' + self.delimiter
print self.cmdline
def tag(self, sent):
self.savefile(self.tempsrcpath, sent)
tagtxt = os.popen(self.cmdline+" -textFile "+self.tempsrcpath, 'r').read()
self.delfile(self.tempsrcpath)
return tagtxt
def tagfile(self,inputpath, outpath):
os.system(self.cmdline+' -textFile '+inputpath+' > '+outpath) # -*- coding: utf-8 -*-
import sys
import os
reload(sys)
sys.setdefaultencoding('utf-8')
from stanford import StanfordPOSTagger
root = "stanford-corenlp/"
modelpath = root+"models/edu/stanford/nlp/models/pos-tagger/chinese-distsim/chinese-distsim.tagger"
st = StanfordPOSTagger(root, modelpath)
seg_sent = "在 包含 问题 的 所有 解 的 解空间树 中 , 按照 深度优先 搜索 的 策略 , 从 根节点 出发 深度 探索 解空间树 。"
taglist = st.tag(seg_sent)
print taglist1.5 整合命名实体识别模块
本书将命名实体识别划分在语义范畴的原因是,命名实体识别不仅需要标注词的语法信息(名词),更重要的是要指示词的语义信息(人名还是组织机构名等)。这里所需要识别的命名实体一般不是指已知名词(词典中的登录词),而是指新词(或称未登录词)。更具体的命名实体识别任务还要识别出文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。
Ltp命名实体识别
命名实体识别模块的文件名为ner.model
# -*- coding: utf-8 -*-
import sys
import os
from pyltp import *
reload(sys)
sys.setdefaultencoding('utf-8')
sent = "欧洲 东部 的 罗马尼亚 , 首都 是 布加勒斯特 , 也 是 一 座 世界性 的 城市 。"
words = sent.split(" ")
postagger = Postagger()
postagger.load("ltp3.4/pos.model") # 导入词性标注模块
postags = postagger.postag(words)
recognizer = NamedEntityRecognizer()
recognizer.load("ltp3.4/ner.model") # 导入命名实体识别模块
netags = recognizer.recognize(words, postags)
for word,postag,netag in zip(words,postags,netags):
print word+"/"+postag+"/"+netag,第一段是词”欧洲“,第二段是词性”ns“,第三段”S-Ns“就是识别的专名,”O“表示非专名,”S-Ns“表示地名。
Stanford命名实体识别
如果仅用NER,可从http://nlp.stanford.edu/software/CRF-NER.shtml下载
#命名实体类
class StanfordNERTagger(StanfordCoreNLP):
def __init__(self,modelpath,jarpath):
StanfordCoreNLP.__init__(self,jarpath)
self.modelpath = modelpath
self.classfier = "edu.stanford.nlp.ie.crf.CRFClassifier"
self.__buildcmd()
def __buildcmd(self):
self.cmdline = 'java -mx1g -cp "'+self.jarpath+'" '+self.classfier+' -loadClassifier "'+self.modelpath+'"'
print self.cmdline
#标注句子
def tag(self, sent):
self.savefile(self.tempsrcpath,sent)
tagtxt = os.popen(self.cmdline+' -textFile '+self.tempsrcpath,'r').read()
self.delfile(self.tempsrcpath)
return tagtxt
#标注文件
def tagfile(self,sent,outpath):
self.savefile(self.tempsrcpath,sent)
os.system(self.cmdline+' -textFile '+self.tempsrcpath+' > '+outpath)
self.delfile(self.tempsrcpath)# -*- coding: utf-8 -*-
import sys
import os
from stanford import StanfordNERTagger
reload(sys)
sys.setdefaultencoding('utf-8')
root = "stanford-corenlp/"
modelpath = root+'models/edu/stanford/nlp/models/ner/chinese.misc.distsim.crf.ser.gz'
st = StanfordNERTagger(modelpath,root)
seg_sent = "欧洲 东部 的 罗马尼亚 , 首都 是 布加勒斯特 , 也 是 一 座 世界性 的 城市 。"
taglist = st.tagfile(seg_sent, "ner_test.txt")
print taglist
1.6 整合句法解析模块
目前句法分析有两种不同的理论:一种是短语结构语法;另一种是依存语法。句法分析的开源系统也很多,但迄今为此,这些解析技术都还不够理想,仍旧很难找到高精度处理中文的句法解析系统。
其中,比较突出的是Ltp中文句法分析系统,使用依存句法理论
还有最著名的句法解析器是Stanford句法解析器。截至2015年,Stanford的句法树包含了如下三大主要解析器。
PCFG概率解析器。是一个高度优化的词汇化PCFG依存解析器。该解析器使用A*算法,是一个随机上下无关文法解析器。除英语之外,该解析器还包含一个中文版本,使用滨州中文树库训练。解析器的输出格式包含依存关系输出和短语结构树输出。
Shift-Reduce解析器。为了提高PCFG概率解析器的性能,Stanford提供了一个基于移进-归约算法的高性能解析器。其性能远高于任何PCFG解析器,而且精度上比其他任何版本(包括RNN)的解析器都更准确。
神经网络依存解析器。神经网络依存解析器是深度学习算法在句法解析中的一个重要应用。它通过中心词和修饰词之间的依存关系来构建出句子的句法树。有关此方面的研究是目前NLP的研究重点。
Ltp句法依存树
句法解析模块的文件名为parser.model
# -*- coding: utf-8 -*-
import sys
import os
import nltk
from nltk.tree import Tree #导入nltk tree结构
from nltk.grammar import DependencyGrammar #导入依存句法包
from nltk.parse import *
from pyltp import * # 导入ltp应用包
import re
reload(sys)
sys.setdefaultencoding('utf-8')
words = "罗马尼亚 的 首都 是 布加勒斯特 。".split(" ") #例句
print words
postagger = Postagger() #词性标注
postagger.load("ltp3.4/pos.model")
postags = postagger.postag(words)
print len(postags)
parser = Parser() #句法解析
parser.load("ltp3.4/parser.model")
arcs = parser.parse(words, postags)
arclen = len(arcs)
print arclen
conll = ""
for i in xrange(arclen): #构建Conll标准的数据结构
if arcs[i].head == 0:
arcs[i].relation = "ROOT"
conll += "\t"+words[i]+"("+postags[i]+")"+"\t"+postags[i]+"\t"+str(arcs[i].head)+"\t"+arcs[i].relation+"\n"
print conll
conlltree = DependencyGraph(conll) #转换为依存句法图
tree = conlltree.tree() # 构建树结构
tree.draw() 罗马尼亚(ns) ns 3 ATT
的(u) u 1 RAD
首都(n) n 4 SBV
是(v) v 0 ROOT
布加勒斯特(ns) ns 4 VOB
。(wp) wp 4 WP

依存关系
Stanford Parser类
如果仅使用中文句法解析模块,可从http://nlp.stanford.edu/software/lex-parser.shtml下载
#句法解析
class StanfordParser(StanfordCoreNLP):
def __init__(self,modelpath,jarpath,opttype):
StanfordCoreNLP.__init__(self,jarpath)
self.modelpath = modelpath # 模型文件路径
self.classfier = "edu.stanford.nlp.parser.lexparser.LexicalizedParser"
self.opttype = opttype
self.__buildcmd()
def __buildcmd(self):
self.cmdline = 'java -mx500m -cp "' + self.jarpath + '" ' + self.classfier + ' -outputFormat "' + self.opttype + '" ' + self.modelpath + ' '
print self.cmdline
#句法解析
def parse(self, sent):
self.savefile(self.tempsrcpath, sent)
tagtxt = os.popen(self.cmdline + self.tempsrcpath, "r").read()
self.delfile(self.tempsrcpath)
return tagtxt
def tagfile(self, sent, outpath):
self.savefile(self, tempsrcpath, sent)
os.system(self.cmdline + self.tempsrcpath + ' > ' + outpath)
self.delfile(self.tempsrcpath)
# -*- coding: utf-8 -*-
import sys
import os
import nltk
from nltk.tree import Tree #导入nltk tree结构
from stanford import *
reload(sys)
sys.setdefaultencoding('utf-8')
# 配置环境变量
#os.environ['JAVA_HOME'] =
root = "stanford-corenlp/"
modelpath = root + "models/edu/stanford/nlp/models/lexparser/chinesePCFG.ser.gz"
opttype = 'penn' #滨州树库格式
parser = StanfordParser(modelpath, root, opttype)
result = parser.parse("罗马尼亚 的 首都 是 布加勒斯特 。")
print result
tree = Tree.fromstring(result)
tree.draw()
(IP
(NP
(DNP
(NP (NR 罗马尼亚))
(DEG 的))
(NP (NN 首都)))
(VP (VC 是)
(NP (NR 布加勒斯特)))
(PU 。)))
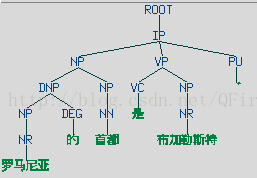
stanford依存句法树
# -*- coding: utf-8 -*-
import sys
import os
import nltk
from nltk.tree import Tree #导入nltk tree结构
from stanford import *
reload(sys)
sys.setdefaultencoding('utf-8')
# 配置环境变量
#os.environ['JAVA_HOME'] =
root = "stanford-corenlp/"
modelpath = root + "models/edu/stanford/nlp/models/lexparser/chinesePCFG.ser.gz"
opttype = 'typedDependencies' #
parser = StanfordParser(modelpath, root, opttype)
result = parser.parse("罗马尼亚 的 首都 是 布加勒斯特 。")
print resultcase(罗马尼亚-1, 的-2)
nsubj(布加勒斯特-5, 首都-3)
cop(布加勒斯特-5, 是-4)
root(ROOT-0, 布加勒斯特-5)
punct(布加勒斯特-5, 。-6)
1.7 整合语义角色标注模块
语义角色标注(SRL)来源于20世纪60年代美国语言学家菲尔墨提出的格语法理论。该理论是在句子语义理解上的一个重要突破。基于此理论,语义角色标注就发展起来了,并成为句子语义分析的一种重要方式。它采用”谓词-论元角色“的结构形式,标注句子成分相对于给定谓语动词的语义角色,每个语义角色被赋予一定的语义。
美国宾州大学已经开发出一个具有使用价值的表示语义命题库,称为PropBank。
语义角色标注系统已经处于NLP系统的末端,其精度和效率都受到前面几个模块的影响,所以,当前系统的精度都不高,在中文领域还没有投入商业应用的成功案例,本节介绍的是Ltp中文语义角色标注系统
# -*- coding: utf-8 -*-
import sys
import os
reload(sys)
sys.setdefaultencoding('utf-8')
from pyltp import *
MODELDIR = "ltp3.4/"
sentence = "欧洲东部的罗马尼亚,首都是布加勒斯特,也是一座世界性的城市。"
segmentor = Segmentor()
segmentor.load(os.path.join(MODELDIR, "cws.model"))
words = segmentor.segment(sentence)
wordlist = list(words) #从生成器变为列表元素
postagger = Postagger()
postagger.load(os.path.join(MODELDIR, "pos.model"))
postags = postagger.postag(words)
parser = Parser()
parser.load(os.path.join(MODELDIR, "parser.model"))
arcs = parser.parse(words, postags)
recognizer = NamedEntityRecognizer()
recognizer.load(os.path.join(MODELDIR, "ner.model"))
netags = recognizer.recognize(words, postags)
#语义角色标注
labeller = SementicRoleLabeller()
labeller.load(os.path.join(MODELDIR, "srl/"))
roles = labeller.label(words, postags, netags, arcs)
#输出标注结果
for role in roles:
print 'rel:', wordlist[role.index] #谓词
for arg in role.arguments:
if arg.range.start != arg.range.end:
print arg.name, ' '.join(wordlist[arg.range.start:arg.range.end])
else:
print arg.name,wordlist[arg.range.start]A0 欧洲 东部 的 罗马尼亚
A0 首都
A1 布加勒斯特
rel: 是
ADV 也
A1 一 座 世界性 的
rel标签表示谓词,A0指动作的实施,A1指动作的受事














 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









