







下载地址:下载完整MP4视频
1. 邱洋的总结
企业用云可以从灾备云开始
为了让应用具备高可用和灾备能力,云平台自身针对基础设施以及云服务都应提供灾备与HA机制,例如:
- 云平台自身:云的分布式存储、虚拟机HA、控制器容灾、SDN网络容灾、虚拟机数据保护
- 云提供具备灾备的云服务
– EC2(虚拟机可以漂移)、EC2实例恢复
– AMI(虚拟机模板备份)
– EBS(数据2+份拷贝)、EBS快照/恢复
– S3(数据2+份拷贝)
– ELB(负载均衡到多数个EC2实例)
– RDS(读写分离、主主部署)
– CloudFormation(多区域一致化部署)
– AutoScale(自动伸缩服务器规模)
– EIP(EC2的实例IP可漂移)
云可以为物理机应用提供灾备能力,例如:
– 将应用、数据库数据放入S3(可能需要开发),提供高可靠保障
– 将数据放入灾备服务(如爱数的服务)中,需要时恢复到本地
– 将物理机P2V(例如使用爱数的服务)到EC2中,需要时恢复到云中
– 将数据库数据复制一份到云中的RDS(采用mysql、oracle、sqlserver的复制工具)企业实施云灾备可以“逐步”的方式
- 单纯备份恢复数据
- 指示灯(应用冷备份)
- 暖待机 (云中存放减配的应用运行资源)
- 热待机 (云中和物理机中1:1热备)
2. 容灾与可用性概述
2.1 云和传统方法的数据中心对比
| 传统方法 | 云 |
|---|---|
| 数据中心建立灾备系统,成本昂贵 | 低成本:低廉的总体拥有成本 |
| 存储、归档、备份和恢复的工具和流程都产生费用 | 统一流程工具:高扩展性的存储、跨AWS区域和可用区的统一流程工具 |
| 容量设计规划、设备采购等面临挑战 | 弹性:不需要精细的规划 |
2.2 什么会造成系统中断?
包括:
- 人为(60%以上的原因)
- 死机停机
- 设备故障
- 自然灾害
- 安全事故
- …
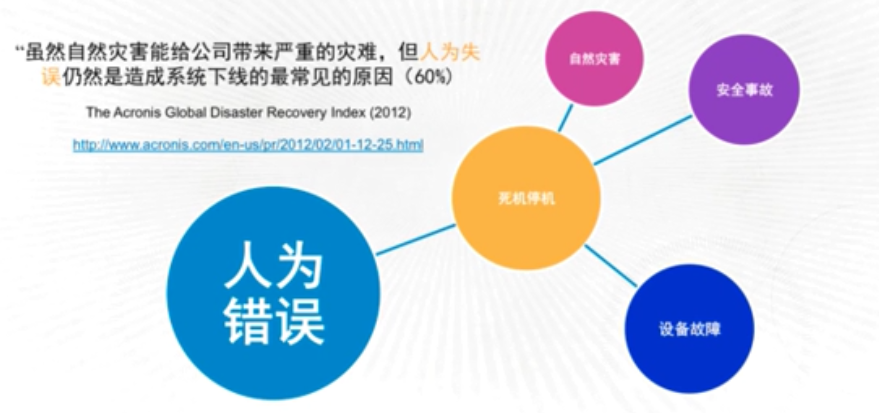
典型人为事故:(虽然有A,B备份机制)某人用root权限删除A中的文件权限(结果rm -rf /)了。虽然B机接管,但是忙中出错用B恢复A的时候,用A恢复了B
2.3 高可用HA和容错FT的定义
- 都是是业务连续性计划的一部分
- 不是有或无,而是可以定制
- 当意外发生时,希望做到的效果包括:业务7*24运行、确保数据安全、大灾难后恢复应用运行)
2.4 灾难备份的序列图
复原时间目标(RTO出了问题后多久恢复ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 430
430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









