







小问题可能存在大问题,希望大神帮忙解答
求大神帮忙解决同样的代码:
setMaster("local")可以运行,但是设置成setMaster("local[3]")或setMaster("local[*]")则报错。
一、Spark中本地运行模式
Spark中本地运行模式有3种,如下
(1)local 模式:本地单线程运行;
(2)local[k]模式:本地K个线程运行;
(3)local[*]模式:用本地尽可能多的线程运行。
二、读取的数据如下
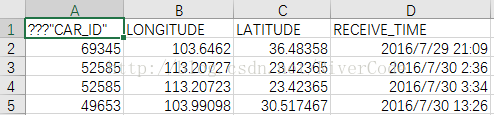
三、牵扯数组越界代码如下
val pieces = line.replaceAll("\"" , "")
val carid = pieces.split(',')(0)
val lngstr = pieces.split(',')(1)
val latstr = pieces.split(',')(2)
var lng=BigDecimal(0)
var lat=BigDecimal(0)
try {
lng = myround(BigDecimal(lngstr), 3)
lat = myround(BigDecimal(latstr), 3)
}catch {
case e: NumberFormatException => println(".....help......"+lngstr+"....."+latstr)
}四、遇到的local、local[k]、local[*]问题
Spark 中Master初始化如下:
val sparkConf = new SparkConf().setMaster("local").setAppName("count test")问题描述如下:
代码其他部门没有改动,只是改变setMaster(),则出现不同结果:</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 234
234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









