







1.#### 基本数据类型和引用类型
基本数据类型:8种,
byte,short,int,long,char,float,double,boolean
引用类型:除了基本数据类型其他的都是引用,即对象:类class、接口、数组
2.抽象类和接口
抽象类可以有构造方法,接口中不能有构造方法。
抽象类中可以有普通成员变量,接口中没有普通成员变量!!!!!!!(注意重点在 普通 即 非静态 和 变量!!!!)
抽象类中可以包含非抽象的普通方法,接口中的所有方法必须都是抽象的,不能有非抽象的普通方法。
抽象类中的抽象方法的访问类型可以是public,protected,但接口中的抽象方法只能是public类型的,并且默认即为public abstract类型,由于private方法不能被覆写。
3.hashCode() 与 equals()
equals()相等的两个对象,hashcode()一定相等,equals()不相等的两个对象,却并不能证明他们的hashcode()不相等。换句话说,equals()方法不相等的两个对象,hashCode()有可能相等。(我的理解是由于哈希码在生成的时候产生冲突造成的)
equals和==的区别
对于基本类型,==是值是否相同
对于对象:==比较内存地址,equals方法不重写的话比较内存地址,如果重写以重写的为准,比如String的equals()方法
4.模式
单例模式
基本思路:static A = new A();懒汉式
public A getA() {}
private A() {}构造方法私有化
如果A需要做复杂的事情,则static A a = null;
private A() {}构造方法私有化
public synchronized A getA() {
if (a == null) a= new A();
return a;
}
工厂模式
简单工厂模型来讲解一下
//通过接口实现不同功能的实现类
interface Fruit{
void doMethod();
};
接口对应的实现:
public Apple implements Fruit() {
public void deMethod() {
//do thing
}
}
public Orange implements Fruit() {
public void deMethod() {
//do thing
}
}
工程类:
public FruitFactory{
public Fruit getFruit(String type) {
if (type.equals(“apple”)) return new Apple();
else if (type.equals(“orange)) return new Orange();
return null;
}
}
5.hashMap和hashTable区别,底层是如何实现的
HashMap是通过”拉链法”实现的哈希表【是通过“拉链法”解决哈希冲突】。它包括几个重要的成员变量:table, size, threshold, loadFactor, modCount。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的”key-value键值对”都是存储在Entry数组中的。
size是HashMap的大小,它是HashMap保存的键值对的数量。
threshold是HashMap的阈值,用于判断是否需要调整HashMap的容量。threshold的值=”容量*加载因子”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
loadFactor就是加载因子。
modCount是用来实现fail-fast机制的。
map是否是有序的,treeMap和treeSet
6.LinkedList,ArrayList区别
ArrayList基于数组实现,
- ArrayList 实际上是通过一个数组去保存数据的。当我们构造ArrayList时;若使用默认构造函数,则ArrayList的默认容量大小是10。
- 当ArrayList容量不足以容纳全部元素时,ArrayList会重新设置容量:新的容量=“(原始容量x3)/2 + 1”。
- ArrayList的克隆函数,即是将全部元素克隆到一个数组中。
- ArrayList实现java.io.Serializable的方式。当写入到输出流时,先写入“容量”,再依次写入“每一个元素”;当读出输入流时,先读取“容量”,再依次读取“每一个元素”。
(01) LinkedList 实际上是通过双向链表去实现的。
它包含一个非常重要的内部类:Entry。Entry是双向链表节点所对应的数据结构,它包括的属性有:当前节点所包含的值,上一个节点,下一个节点。
(02) 从LinkedList的实现方式中可以发现,它不存在LinkedList容量不足的问题。
(03) LinkedList的克隆函数,即是将全部元素克隆到一个新的LinkedList对象中。
更令人惊讶的是ConcurrentHashMap的读取并发,因为在读取的大多数时候都没有用到锁定,所以读取操作几乎是完全的并发操作,而写操作锁定的粒度又非常细,比起之前又更加快速(这一点在桶更多时表现得更明显些)。只有在求size等操作时才需要锁定整个表。
更令人惊讶的是ConcurrentHashMap的读取并发,因为在读取的大多数时候都没有用到锁定,所以读取操作几乎是完全的并发操作,而写操作锁定的粒度又非常细,比起之前又更加快速(这一点在桶更多时表现得更明显些)。只有在求size等操作时才需要锁定整个表。
8.Sring和StringBuffer,StringBuilder区别
简要的说, String 类型和 StringBuffer 类型的主要性能区别其实在于 String 是不可变的对象, 因此在每次对 String 类型进行改变的时候其实都等同于生成了一个新的 String 对象,然后将指针指向新的 String 对象,所以经常改变内容的字符串最好不要用 String ,因为每次生成对象都会对系统性能产生影响,特别当内存中无引用对象多了以后, JVM 的 GC 就会开始工作,那速度是一定会相当慢的。
字节流和字符流可以相互转换,以文件为例,字符流存储在硬盘上的也是二进制文件,只是二进制流可以按照编码转换为字符
IO流中一定要注意编码,否则就可以发生硬转码的情况
10.NIO相关知识点
Channels(通道)
Buffers(缓存区)
Selectors(选择器)
Java NIO的选择器 允许一个单独的线程来监视多个输入通道 ,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道 :可以选择这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
其实NIO的核心是IO线程池,一定要记住这个关键点。
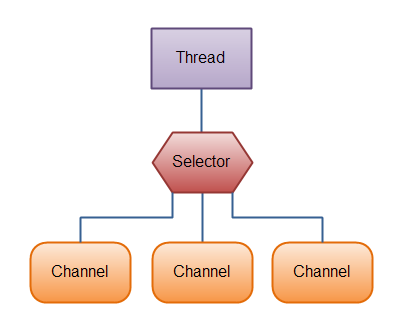
NIO本身是基于事件驱动思想来完成的,其主要想解决的是网络编程的大并发问题
11.递归读取文件夹下的文件
-
public void traverseFolder2(String path){ -
File file =newFile(path); -
if(file.exists()){ -
File[] files = file.listFiles(); -
if(files.length==0){ -
System.out.println("文件夹是空的!"); -
return; -
}else{ -
for(File file2: files){ -
if(file2.isDirectory()){ -
System.out.println("文件夹:"+ file2.getAbsolutePath()); -
traverseFolder2(file2.getAbsolutePath()); -
}else{ -
System.out.println("文件:"+ file2.getAbsolutePath()); -
} -
} -
} -
}else{ -
System.out.println("文件不存在!"); -
} -
} -
如果用非递归的方式的话,就要用到list了,然后list不为空进行循环了,如下:
public void traverseFolder1(String path) {int fileNum = 0, folderNum = 0;File file = new File(path);if (file.exists()) {LinkedList<File> list = new LinkedList<File>();File[] files = file.listFiles();for (File file2 : files) {if (file2.isDirectory()) {System.out.println("文件夹:" + file2.getAbsolutePath());list.add(file2);fileNum++;} else {System.out.println("文件:" + file2.getAbsolutePath());folderNum++;}}File temp_file;while (!list.isEmpty()) {temp_file = list.removeFirst();files = temp_file.listFiles();for (File file2 : files) {if (file2.isDirectory()) {System.out.println("文件夹:" + file2.getAbsolutePath());list.add(file2);fileNum++;} else {System.out.println("文件:" + file2.getAbsolutePath());folderNum++;}}}} else {System.out.println("文件不存在!");}System.out.println("文件夹共有:" + folderNum + ",文件共有:" + fileNum);}
数据库隔离级别,举例说明
- 原子性:整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性:在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
- 隔离性:隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。如果有两个事务,运行在相同的时间内,执行 相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。这种属性有时称为串行化,为了防止事务操作间的混淆,必须串行化或序列化请求,使得在同一时间仅有一个请求用于同一数据。
- 持久性:在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。















 450
450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









