







跟着Scott老师把上一次的那个爬虫代码进行改造,主要包括单个网页爬取变为多个网页爬取、使用Promise来优化多层回调、动态数据的获取(Scott老师视频中没有的,自己乱搞一个晚上出来的。。。)
首先来介绍一下Promise,Promise可以将多层的回调转换为链式来操作,大大提升了代码的可读性与维护性。从表面上看,Promise只是能够简化层层回调的写法,而实质上,Promise的精髓是“状态”,用维护状态、传递状态的方式来使得回调函数能够及时调用,它比传递callback函数要简单、灵活的多。下面来介绍如何使用Promise来优化
1. 由于该爬虫是多个页面并发爬取的,使用普通的方法需要层层回调,所以对该回调函数(获取页面数据函数)进行Promise包装
function getPageAsync(url) {//使用Promise对象来包装获取到页面的html的方法
return new Promise(function (resolve,reject) {
console.log('正在爬取 ' + url + '\n');
http.get(url,function(res){
var html = '';
res.on('data',function (data) {
html += data.toString('utf-8');
})
res.on('end',function(){
resolve(html);//把当前的获取到页面的html返回回去(传递下去)
})
}).on('error',function (e) {
reject(e);
console.log("获取课程数据出错!");
})
})
}2. 使用Promise的all方法(参数是一个数组,当这个数组里面所有的 Promise 对象都变为 resolve 时,该方法才会返回)来并发获取每个页面的源码,然后执行then方法来执行每个页面的爬取操作
Promise
.all(fetchPageUrl)//针对每个url地址返回的页面HTML源码并发操作进行爬取
.then(function (Pages) {
var coursesData = [];
Pages.forEach(function (html) {
var course = selecttHtml(html);//获取当前爬取的数据
coursesData.push(course);//保存当前爬取的数据
})
//console.log(courseMembers);
for(var i in courseIds)//获取每个课程的学习人数,因为获取是异步操作的,所以要用同步地给每个课程对象赋值
{
for(var j in courseMembers.id)
if(courseMembers.id[j] === courseIds[i]) {
coursesData[i].number = courseMembers.numbers[j];
}
}
coursesData.sort(function (a, b) {//按照学习的人数从高到低排序
return a.number < b.number;
})
printinfo(coursesData);//打印已经爬取好的数据
})动态数据的获取,因为慕课网页面源码的改变,原本Scott老师视频中获取的学习人数是静态数据来的,现在却是动态数据(好心塞啊。。),下面我来介绍一下自己是怎么获取到的动态数据的
1.首先在页面源码中找到学习人数这个数值的标签位置,发现它由一个特有的类(js-learn-num)来控制的。
2. 然后在开发人员工具中的调试程序面板下搜索js-learn-num,然后发现该数据是通过ajax的GET方法来异步获取的(如下图所示)
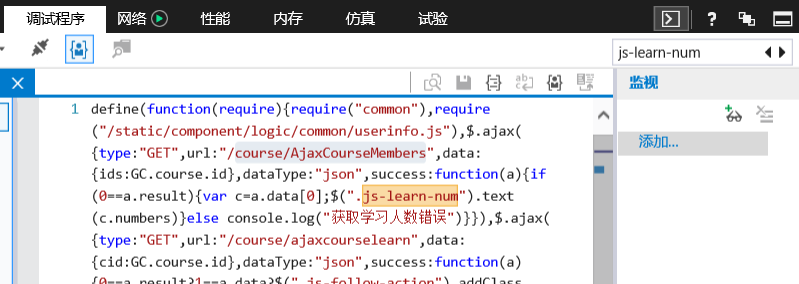
3. 在网络面板中搜索上图的url地址,然后找到一个AjaxCourseMembers?ids=259的请求,里面用JSON格式来封装的就是我们需要获取学习人数的动态数据
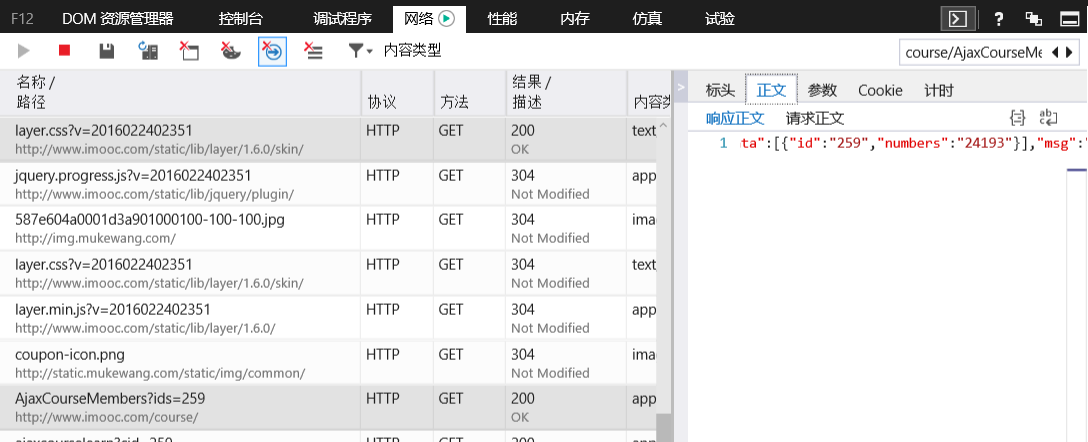
4. 下面直接用Nodejs中http模块的get方法去获取这个JSON数据,然后进行JSON解析该数据从而获得我们想要的数据
下面直接来看代码:
/**
* Created by Turne on 2017/2/10.
*/
var http = require('http');
var Promise = require('bluebird')
var querystring = require('querystring');
var url = 'http://www.imooc.com/course/AjaxCourseMembers?ids=728';
var titleBaseUrl = 'http://www.imooc.com/course/AjaxCourseMembers?ids=';//用以获取每个课程的学习人数,该数据是动态的
var cheerio = require('cheerio');
var baseUrl = 'http://www.imooc.com/learn/';
var courseIds = [728,637,348,259,197,134,75];//需要爬取课程的id
var courseMembers = {id:[],numbers:[]};//每个课程学习的人数
function printinfo(coursesData) {//打印已经爬好的东西
coursesData.forEach(function (courseData) {
console.log(courseData.number + " 学过了 " + courseData.title + '\n');
})
var chapterTitle;
coursesData.forEach(function (courseDatas) {
console.log('###'+courseDatas.title +'###'+ '\n');//打印每个课程的标题
courseDatas.courseData.forEach(function (item) {
chapterTitle = item.chapterTitle;
console.log(chapterTitle + '\n');//打印每一章的标题
item.videos.forEach(function (video) {
console.log(' 【' + video.id + '】 '+ video.title + '\n');//打印每个视频的id和标题
})
})
})
}
function selecttHtml(html) {//通过页面源码来选择需要爬取的东西
var $ = cheerio.load(html);
var contents = $('.chapter');//某章节下的HTML的源码
var title = $($('.course-infos')).find('h2').text();//整个课程的大标题
var id = $($(".course-infos").find('a')[3]).attr('href').split('/learn/')[1];
//getCourseMembers(parseInt(id,10));
//console.log(number);
//var courseData = [];
var coursesData = {
title:title,
number:0,
courseData:[]
}
contents.each(function (item) {
var content = $(this);//当前这一章的HTML源码数据
var text = content.find('.chapter-content').text();
var chapterTitle = content.find('strong').text().split(text)[0].trim();//获取每一章的标题
var videos = content.find('.video').children('li');//获取每个视频的信息,包含视频的id和标题
var chapterData = {
chapterTitle:chapterTitle,
videos: []
};
videos.each(function (item) {
var video = $(this).find('a');
var title = video.text().split('开始学习')[0].trim();//获取每个视频的标题
//console.log(title.length);
title = title.substring(0,title.length - 10).trim() + " " + title.substring(title.length - 10,title.length).trim();
var id = video.attr('href').split('video/')[1];//获取每个视频的id
chapterData.videos.push({
title:title,
id:id
})
})
coursesData.courseData.push(chapterData)//保存爬取的数据
})
return coursesData;
}
function getPageAsync(url) {//使用Promise对象来包装获取到页面的html的方法
return new Promise(function (resolve,reject) {
console.log('正在爬取 ' + url + '\n');
http.get(url,function(res){
var html = '';
res.on('data',function (data) {
html += data.toString('utf-8');
})
res.on('end',function(){
resolve(html);//把当前的获取到页面的html返回回去(传递下去)
})
}).on('error',function (e) {
reject(e);
console.log("获取课程数据出错!");
})
})
}
function getCourseMembers(id) {//用以获取每个课程的学习人数
var url = titleBaseUrl + id;
var members;
//由于学习人数是通过AjAX来异步更新的,所以我们要使用http的个get方法去获取AJAX获取数据的url去获得我们想要的数据
http.get(url,function(res){
var datas = '';
res.on('data',function (chunk) {
datas += chunk;
})
res.on('end',function(){
datas = JSON.parse(datas);//由于获取到的数据是JSON格式的,所以需要JSON.parse方法浅解析
courseMembers.id.push(id);//保存每个课程的
courseMembers.numbers.push(parseInt(datas.data[0].numbers,10));//保存每个课程的学习人数
})
})
}
var fetchPageUrl = [];
courseIds.forEach(function (id) {
fetchPageUrl.push(getPageAsync(baseUrl + id));
getCourseMembers(id);
})
Promise
.all(fetchPageUrl)//针对每个url地址返回的页面HTML源码并发操作进行爬取
.then(function (Pages) {
var coursesData = [];
Pages.forEach(function (html) {
var course = selecttHtml(html);//获取当前爬取的数据
coursesData.push(course);//保存当前爬取的数据
})
//console.log(courseMembers);
for(var i in courseIds)//获取每个课程的学习人数,因为获取是异步操作的,所以要用同步地给每个课程对象赋值
{
for(var j in courseMembers.id)
if(courseMembers.id[j] === courseIds[i]) {
coursesData[i].number = courseMembers.numbers[j];
}
}
coursesData.sort(function (a, b) {//按照学习的人数从高到低排序
return a.number < b.number;
})
printinfo(coursesData);//打印已经爬取好的数据
})















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









