







最近一直在学Lucene3.5,感觉里面的知识真的很棒。今天就和大家一起分享一下我们自己来实现一个同义词的分词器。
一个分词器由多个Tokenizer和TokenFilter组成,这篇文章讲解的就是我们利用这两个特性实现自己的一个简单的同义词分词器,不妥之处请大家指出。
一、设计思路
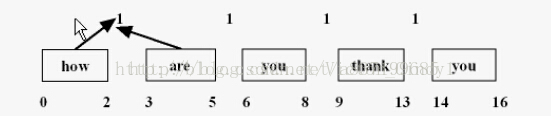
什么叫同义词搜索呢?比如我们在搜 ”中国“ 这个词的时候,我们也可以搜索 ”大陆“ 这个词,后者搜索的要包含 ”中国“ 这个单词的文章, 前者搜索的要包含 ”大陆“ 这个单词的文章。这里我们就必须要了解Lucene是怎么处理我们的文档了,首先我们得了解这3个类:
PositionIncrementAttribute (位置增量的属性,存储语汇单元之间的距离)
OffsetAttribute (每个语汇单元的位置偏移量)
CharTermAttribute (存储每一个语汇单元的信息,即分词单元信息)
如图:
这些东西都有一个叫做AttributeSource的类决定,这个类中保存了这些信息。里面有一个叫做STATE的静态内部类。我们在以后的过程中可以用下面这个方法捕获当前状态。
/**
* Captures the state of all Attributes. The return value can be passed to
* {@link #restoreState} to restore the state of this or another AttributeSource.
*/
public State captureState() {
final State state = this.getCurrentState();
return (state == null) ? null : (State) state.clone();
}二、实现
1、首先我们定义一个同义词的接口(为了提高我们程序的扩展性)
package com.dhb.util;
public interface SamewordContext {
public String[] getSamewords(String name);
}
2、我们继承这个接口(把同义词放进我们的Map)
package com.dhb.util;
import java.util.HashMap;
import java.util.Map;
public class SimpleSamewordContext implements SamewordContext {
Map<String , String[]> maps = new HashMap<String, String[]>();
public SimpleSamewordContext() {
maps.put("中国", new String[] {"天朝", "大陆"});
maps.put("我", new String[] {"俺", "咱"});
}
@Override
public String[] getSamewords(String name) {
return maps.get(name);
}
}
package com.dhb.util;
import java.io.Reader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import com.chenlb.mmseg4j.Dictionary;
import com.chenlb.mmseg4j.MaxWordSeg;
import com.chenlb.mmseg4j.analysis.MMSegTokenizer;
public class MySameAnalyzer extends Analyzer {
private SamewordContext samewordContext;
public MySameAnalyzer(SamewordContext samewordContext) {
this.samewordContext = samewordContext;
}
@Override
public TokenStream tokenStream(String fieldName, Reader reader) {
Dictionary dic = Dictionary.getInstance("F:\\邓海波jar\\mmseg4j\\mmseg4j-1.8.5\\data");
return new MySameTokenFilter(new MMSegTokenizer(new MaxWordSeg(dic), reader), samewordContext);
}
}
4、看我们的filter,主要看注释,关键都在注释里面
package com.dhb.util;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Stack;
import org.apache.lucene.analysis.TokenFilter;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.PositionIncrementAttribute;
import org.apache.lucene.util.AttributeSource;
public class MySameTokenFilter extends TokenFilter {
private CharTermAttribute cta = null;
private PositionIncrementAttribute pia = null;
private AttributeSource.State current;
private Stack<String> sames = null;
private SamewordContext samewordContext;
protected MySameTokenFilter(TokenStream input, SamewordContext samewordContext) {
super(input);
cta = this.addAttribute(CharTermAttribute.class);
pia = this.addAttribute(PositionIncrementAttribute.class);
sames = new Stack<String>();
this.samewordContext = samewordContext;
}
@Override
public boolean incrementToken() throws IOException {
//System.out.println(cta);
/*if(cta.toString().equals("中国")) {
cta.setEmpty();
cta.append("大陆");
}*/
while(sames.size() > 0) {
// 将元素出栈,并且获取这个同义词
String str = sames.pop();
// 还原状态
restoreState(current);
//System.out.println("--------"+cta);
cta.setEmpty();
cta.append(str);
//设置位置0
pia.setPositionIncrement(0);
return true; // 如果不返回true,会把之前的覆盖掉
}
if(!input.incrementToken()) return false; // 不能放在开头,放在这里是因为不会把之前的给覆盖掉
if(addSames(cta.toString())) { //getSameWords改成addSames
//如果捕获到有同义词,则将当前状态先保存
current = captureState();
}
return true;
}
/*private boolean getSameWords(String name) {
Map<String , String[]> maps = new HashMap<String, String[]>();
maps.put("中国", new String[] {"天朝", "大陆"});
maps.put("我", new String[] {"俺", "咱"});
String[] sws = maps.get(name);
if(sws != null) {
for(String s : sws) {
sames.push(s);
}
return true;
}
return false;
}*/
private boolean addSames(String name) {
String[] sws = samewordContext.getSamewords(name);
if(sws != null) {
for(String s : sws) {
sames.push(s);
}
return true;
}
return false;
}
}
5、最后我们的测试工具类里的一个方法
@Test
public void test06() {
Analyzer a = new MySameAnalyzer(new SimpleSamewordContext());
String txt = "我来自中国重庆南岸区崇文路2号重庆邮电大学";
Directory dir =new RAMDirectory();
try {
IndexWriter writer = new IndexWriter(dir, new IndexWriterConfig(Version.LUCENE_35, a));
Document doc = new Document();
doc.add(new Field("content", txt, Field.Store.YES, Field.Index.ANALYZED));
writer.addDocument(doc);
writer.close();
IndexSearcher searcher = new IndexSearcher(IndexReader.open(dir));
//搜大陆或者中国都可以搜到
TopDocs tds = searcher.search(new TermQuery(new Term("content", "大陆")), 10);
Document d =searcher.doc(tds.scoreDocs[0].doc);
System.out.println(d.get("content"));
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}这是一个位置信息:
1:我[0-1]-->word
0:咱[0-1]-->word
0:俺[0-1]-->word
1:来自[1-3]-->word
1:中国[3-5]-->word
0:大陆[3-5]-->word
0:天朝[3-5]-->word
1:重庆[5-7]-->word
1:南岸[7-9]-->word
1:区[9-10]-->word
1:崇文[10-12]-->word
1:路[12-13]-->word
1:2[13-14]-->digit
1:号[14-15]-->word
1:重庆[15-17]-->word
1:邮电[17-19]-->word
1:电大[18-20]-->word
1:大学[19-21]-->word有没有发现,同义词已经加进去了,而且他们的偏移量和位置增量都是一样的,然后我们搜索【】的时候就可以把这篇文档搜索出来了。
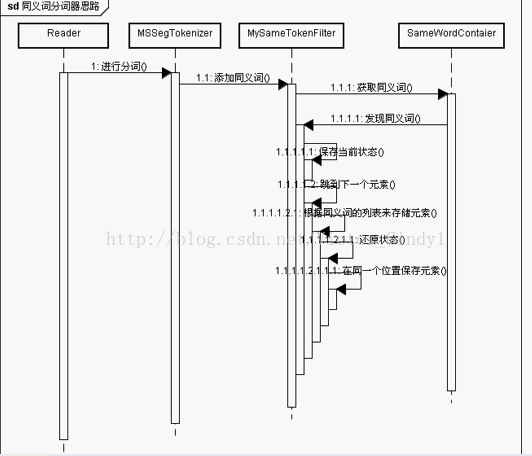
这是我的思路图:














 2909
2909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









