







原文不是python3,我把其代码更正成python3.了
更正代码:
# coding=utf-8
# 声明编码方式 默认编码方式ASCII 参考https://www.python.org/dev/peps/pep-0263/
import urllib.request
import time
import re
import os
'''''
Python下载游迅网图片 BY:Eastmount
'''
'''''
#html用decode('utf-8')进行解码,由bytes变成string。
#py3的urlopen返回的不是string是bytes
**************************************************
#第一步 遍历获取每页对应主题的URL
#http://pic.yxdown.com/list/0_0_1.html
#http://pic.yxdown.com/list/0_0_75.html
**************************************************
'''
fileurl=open('yxdown_url.txt','w')
fileurl.write('****************获取游讯网图片URL*************\n\n')
#建议num=3 while num<=3一次遍历一个页面所有主题,下次换成num=4 while num<=4而不是1-75
num=3
while num<=3:
temp = 'http://pic.yxdown.com/list/0_0_'+str(num)+'.html'
content = urllib.request.urlopen(temp).read().decode('utf-8')
open('yxdown_'+str(num)+'.html','w+').write(content)
print (temp )
fileurl.write('****************第'+str(num)+'页*************\n\n')
#爬取对应主题的URL
#<div class="cbmiddle"></div>中<a target="_blank" href="/html/5533.html" >
count=1 #计算每页1-75中具体网页个数
res_div = r'<div class="cbmiddle">(.*?)</div>'
m_div = re.findall(res_div,content,re.S|re.M)
for line in m_div:
#fileurl.write(line+'\n')
#获取每页所有主题对应的URL并输出
if "_blank" in line: #防止获取列表list/1_0_1.html list/2_0_1.html
#获取主题
fileurl.write('\n\n********************************************\n')
title_pat = r'<b class="imgname">(.*?)</b>'
title_ex = re.compile(title_pat,re.M|re.S)
title_obj = re.search(title_ex, line)
title = title_obj.group()
# print (unicode(title,'utf-8') )
fileurl.write(title+'\n')
#获取URL
res_href = r'<a target="_blank" href="(.*?)"'
m_linklist = re.findall(res_href,line)
#print unicode(str(m_linklist),'utf-8')
for link in m_linklist:
fileurl.write(str(link)+'\n') #形如"/html/5533.html"
'''''
**************************************************
#第二步 去到具体图像页面 下载HTML页面
#http://pic.yxdown.com/html/5533.html#p=1
#注意先本地创建yxdown 否则报错No such file or directory
**************************************************
'''
#下载HTML网页无原图 故加'#p=1'错误
#HTTP Error 400. The request URL is invalid.
html_url = 'http://pic.yxdown.com'+str(link)
print (html_url )
html_content = urllib.request.urlopen(html_url).read().decode('utf-8')#具体网站内容
#可注释它 暂不下载静态HTML
open('yxdown/yxdown_html'+str(count)+'.html','w+').write(html_content)
'''''
#第三步 去到图片界面下载图片
#图片的链接地址为http://pic.yxdown.com/html/5530.html#p=1 #p=2
#点击"查看原图"HTML代码如下
#<a href="javascript:;" style=""οnclick="return false;">查看原图</a>
#通过JavaScript实现 而且该界面存储所有图片链接<script></script>之间
#获取"original":"http://i-2.yxdown.com/2015/3/18/6381ccc..3158d6ad23e.jpg"
'''
html_script = r'<script>(.*?)</script>'
m_script = re.findall(html_script,html_content,re.S|re.M)
for script in m_script:
res_original = r'"original":"(.*?)"' #原图
m_original = re.findall(res_original,script)
for pic_url in m_original:
print (pic_url )
fileurl.write(str(pic_url)+'\n')
'''''
#第四步 下载图片
#如果浏览器存在验证信息如维基百科 需添加如下代码
class AppURLopener(urllib.request.FancyURLopener):
version = "Mozilla/5.0"
urllib.request._urlopener = AppURLopener()
#参考 http://bbs.csdn.net/topics/380203601
#http://www.lylinux.org/python使用多线程下载图片.html
'''
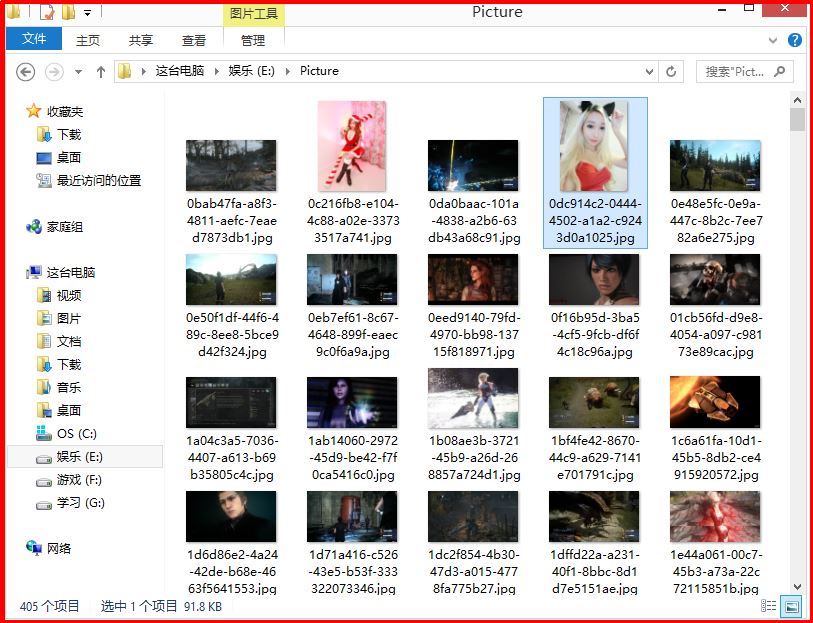
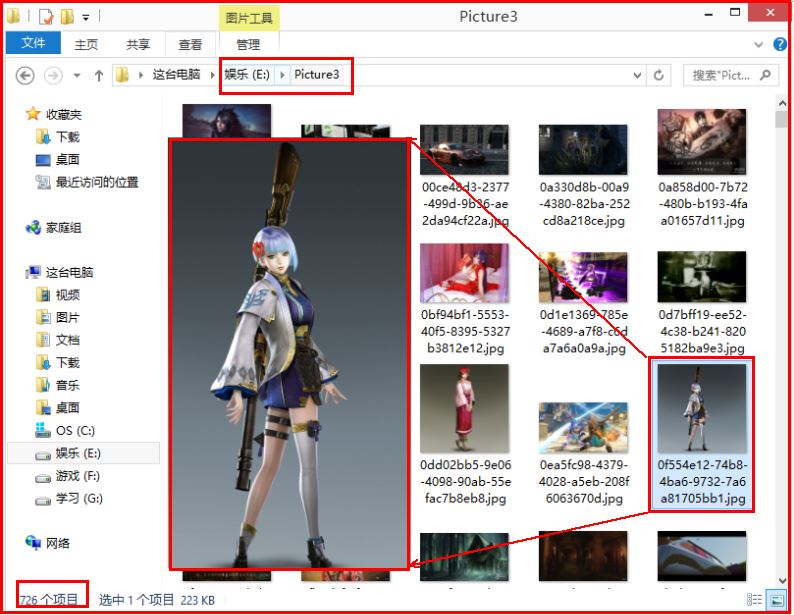
filename = os.path.basename(pic_url) #去掉目录路径,返回文件名
#No such file or directory 需要先创建文件Picture3
urllib.request.urlretrieve(pic_url, 'Picture3\\'+filename)
#http://pic.yxdown.com/html/5519.html
#IOError: [Errno socket error] [Errno 10060]
#只输出一个URL 否则输出两个相同的URL
break
#当前页具体内容个数加1
count=count+1
time.sleep(0.1)
else:
print ('no url about content' )
time.sleep(1)
num=num+1
else:
print ('Download Over!!!' )
原文:
最近老师让学习Python与维基百科相关的知识,无聊之中用Python简单做了个爬取“游讯网图库”中的图片,因为每次点击下一张感觉非常浪费时间又繁琐。主要分享的是如何爬取HTML的知识和Python如何下载图片;希望对大家有所帮助,同时发现该网站的图片都挺精美的,建议阅读原网下载图片,支持游讯网不要去破坏它。
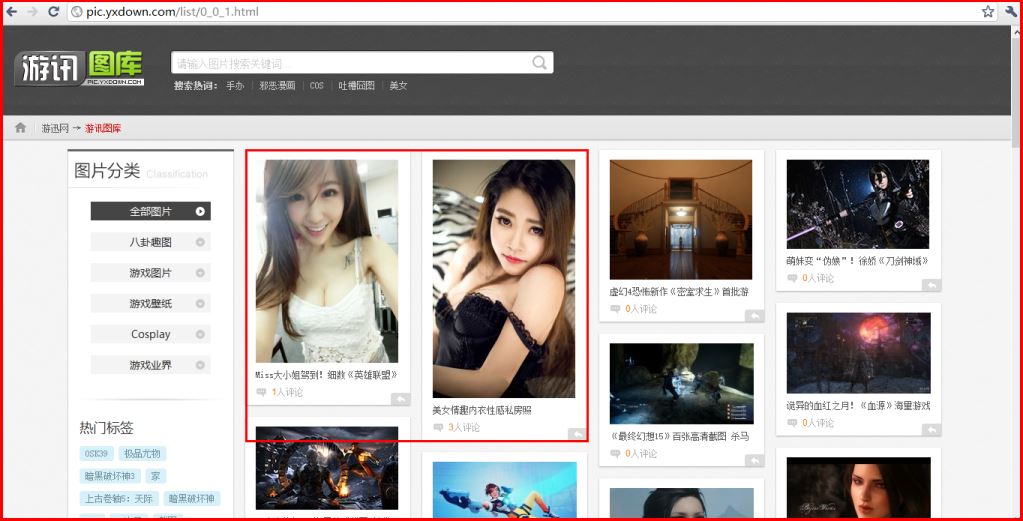
通过浏览游讯网发现它的图库URL为,其中全部图片为0_0_1到0_0_75:http://pic.yxdown.com/list/0_0_1.html
http://pic.yxdown.com/list/0_0_75.html

(需在本地创建E:\\Picture3文件夹和Python运行目录创建yxdown文件夹)
- # coding=utf-8
- # 声明编码方式 默认编码方式ASCII 参考https://www.python.org/dev/peps/pep-0263/
- import urllib
- import time
- import re
- import os
- '''''
- Python下载游迅网图片 BY:Eastmount
- '''
- '''''
- **************************************************
- #第一步 遍历获取每页对应主题的URL
- #http://pic.yxdown.com/list/0_0_1.html
- #http://pic.yxdown.com/list/0_0_75.html
- **************************************************
- '''
- fileurl=open('yxdown_url.txt','w')
- fileurl.write('****************获取游讯网图片URL*************\n\n')
- #建议num=3 while num<=3一次遍历一个页面所有主题,下次换成num=4 while num<=4而不是1-75
- num=3
- while num<=3:
- temp = 'http://pic.yxdown.com/list/0_0_'+str(num)+'.html'
- content = urllib.urlopen(temp).read()
- open('yxdown_'+str(num)+'.html','w+').write(content)
- print temp
- fileurl.write('****************第'+str(num)+'页*************\n\n')
- #爬取对应主题的URL
- #<div class="cbmiddle"></div>中<a target="_blank" href="/html/5533.html" >
- count=1 #计算每页1-75中具体网页个数
- res_div = r'<div class="cbmiddle">(.*?)</div>'
- m_div = re.findall(res_div,content,re.S|re.M)
- for line in m_div:
- #fileurl.write(line+'\n')
- #获取每页所有主题对应的URL并输出
- if "_blank" in line: #防止获取列表list/1_0_1.html list/2_0_1.html
- #获取主题
- fileurl.write('\n\n********************************************\n')
- title_pat = r'<b class="imgname">(.*?)</b>'
- title_ex = re.compile(title_pat,re.M|re.S)
- title_obj = re.search(title_ex, line)
- title = title_obj.group()
- print unicode(title,'utf-8')
- fileurl.write(title+'\n')
- #获取URL
- res_href = r'<a target="_blank" href="(.*?)"'
- m_linklist = re.findall(res_href,line)
- #print unicode(str(m_linklist),'utf-8')
- for link in m_linklist:
- fileurl.write(str(link)+'\n') #形如"/html/5533.html"
- '''''
- **************************************************
- #第二步 去到具体图像页面 下载HTML页面
- #http://pic.yxdown.com/html/5533.html#p=1
- #注意先本地创建yxdown 否则报错No such file or directory
- **************************************************
- '''
- #下载HTML网页无原图 故加'#p=1'错误
- #HTTP Error 400. The request URL is invalid.
- html_url = 'http://pic.yxdown.com'+str(link)
- print html_url
- html_content = urllib.urlopen(html_url).read() #具体网站内容
- #可注释它 暂不下载静态HTML
- open('yxdown/yxdown_html'+str(count)+'.html','w+').write(html_content)
- '''''
- #第三步 去到图片界面下载图片
- #图片的链接地址为http://pic.yxdown.com/html/5530.html#p=1 #p=2
- #点击"查看原图"HTML代码如下
- #<a href="javascript:;" style=""οnclick="return false;">查看原图</a>
- #通过JavaScript实现 而且该界面存储所有图片链接<script></script>之间
- #获取"original":"http://i-2.yxdown.com/2015/3/18/6381ccc..3158d6ad23e.jpg"
- '''
- html_script = r'<script>(.*?)</script>'
- m_script = re.findall(html_script,html_content,re.S|re.M)
- for script in m_script:
- res_original = r'"original":"(.*?)"' #原图
- m_original = re.findall(res_original,script)
- for pic_url in m_original:
- print pic_url
- fileurl.write(str(pic_url)+'\n')
- '''''
- #第四步 下载图片
- #如果浏览器存在验证信息如维基百科 需添加如下代码
- class AppURLopener(urllib.FancyURLopener):
- version = "Mozilla/5.0"
- urllib._urlopener = AppURLopener()
- #参考 http://bbs.csdn.net/topics/380203601
- #http://www.lylinux.org/python使用多线程下载图片.html
- '''
- filename = os.path.basename(pic_url) #去掉目录路径,返回文件名
- #No such file or directory 需要先创建文件Picture3
- urllib.urlretrieve(pic_url, 'E:\\Picture3\\'+filename)
- #http://pic.yxdown.com/html/5519.html
- #IOError: [Errno socket error] [Errno 10060]
- #只输出一个URL 否则输出两个相同的URL
- break
- #当前页具体内容个数加1
- count=count+1
- time.sleep(0.1)
- else:
- print 'no url about content'
- time.sleep(1)
- num=num+1
- else:
- print 'Download Over!!!'
1.简单遍历网站,获取每页对应主题的URL。其中每页都有无数个主题,其中主题的格式如下:
- <!-- 第一步 爬取的HTML代码如下 -->
- <div class="conbox">
- <div class="cbtop">
- </div>
- <div class="cbmiddle">
- <a target="_blank" href="/html/5533.html" class="proimg">
- <img src="http://i-2.yxdown.com/2015/3/19/KDE5Mngp/a78649d0-9902-4086-a274-49f9f3015d96.jpg" alt="Miss大小姐驾到!细数《英雄联盟》圈的电竞女神" />
- <strong></strong>
- <p>
- <span>b></b>1836人看过</span>
- <em><b></b>10张</em>
- </p>
- <b class="imgname">Miss大小姐驾到!细数《英雄联盟》圈的电竞女神</b>
- </a>
- <a target="_blank" href="/html/5533.html" class="plLink"><em>1</em>人评论</a>
- </div>
- <div class="cbbottom">
- </div>
- <a target="_blank" class="plBtn" href="/html/5533.html"></a>
- </div>


http://pic.yxdown.com/html/5533.html#p=1
同时下载本地HTML页面可以注释该句代码。此时需要点击“查看图片”才能下载原图,点击右键只能另存为网站html。
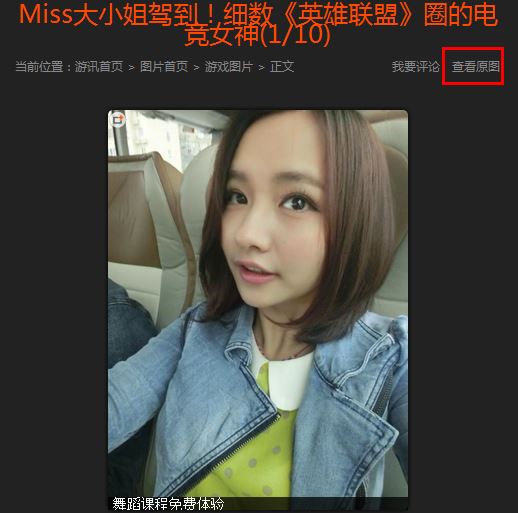
<a href="javascript:;" οnclick="return false;" id="photoOriginal">查看原图</a>
同时它把所有图片都写在下面代码<script></script>中:
- <script>var images = [
- { "big":"http://i-2.yxdown.com/2015/3/18/KDkwMHgp/6381ccc0-ed65-4422-8671-b3158d6ad23e.jpg",
- "thumb":"http://i-2.yxdown.com/2015/3/18/KHgxMjAp/6381ccc0-ed65-4422-8671-b3158d6ad23e.jpg",
- "original":"http://i-2.yxdown.com/2015/3/18/6381ccc0-ed65-4422-8671-b3158d6ad23e.jpg",
- "title":"","descript":"","id":75109},
- { "big":"http://i-2.yxdown.com/2015/3/18/KDkwMHgp/fec26de9-8727-424a-b272-f2827669a320.jpg",
- "thumb":"http://i-2.yxdown.com/2015/3/18/KHgxMjAp/fec26de9-8727-424a-b272-f2827669a320.jpg",
- "original":"http://i-2.yxdown.com/2015/3/18/fec26de9-8727-424a-b272-f2827669a320.jpg",
- "title":"","descript":"","id":75110},
- ...
- </script>
res_original = r'"original":"(.*?)"' #原图
m_original = re.findall(res_original,script)
4.最后一步就是下载图片,其中我不太会使用线程,只是简单添加了time.sleep(0.1) 函数。下载图片可能会遇到维基百科那种访问受限,需要相应设置,核心代码如下:
- import os
- import urllib
- class AppURLopener(urllib.FancyURLopener):
- version = "Mozilla/5.0"
- urllib._urlopener = AppURLopener()
- url = "http://i-2.yxdown.com/2015/2/25/c205972d-d858-4dcd-9c8b-8c0f876407f8.jpg"
- filename = os.path.basename(url)
- urllib.urlretrieve(url , filename)
(By:Eastmount 2015-3-20 下午5点 http://blog.csdn.net/eastmount/)















 53万+
53万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









