







在做深度学习的时候突然发现一个问题,除了一些网站提供的数据集之外,我该如何获取自己的数据集呢?于是我想到了爬虫,之前也没接触过爬虫,但是那有什么关系,算法的可是站在鄙视链顶端的存在,爬个图片还不是小case。于是我花了两天时间研究了下爬虫,原来天下的坑都是一般的深,我爬取的网站是“http://699pic.com/”,也就是下面这个摄图网。

在爬取这个网站的时候,首先你要找到你的‘user-Agent‘,然后把它作为请求网页的一个参数,不然人家不让你爬,在浏览器中输入“about://version”,然后就可以看见你的用户代理,复制下来就行
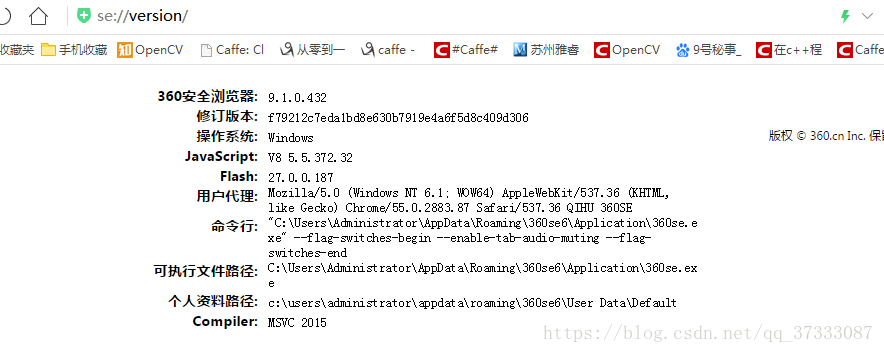
下面上代码,
import requests
import urllib
from bs4 import BeautifulSoup
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 QIHU 360SE"
}
cookies={'cookies':''}
def getImage(word):
#这里拼凑成一个url
url='http://699pic.com/tupian/'+word+'.html'
#这里获取网站的源码,源码主要是很长的一段html格式的字符串
r=requests.get(url)
#BeautifulSoup这个库可以解析html格式的字符串,把网页的源码解析成一个个类,然后你就可以依次去访问它#的属性,比如head,div,src等等
soup = BeautifulSoup(r.content,'html.parser')
#这里就是对BeautifulSoup的运用了
all_a = soup.find_all('div',class_='list')
for i in range(len(all_a)):
imgurl=all_a[i].img.attrs['data-original']
#这里获得的imgurl是图片的网站,一个网站一张图片,然后通过urllib里面的urlretrieve的这个函数把图片下#载到本地
urllib.urlretrieve(imgurl, 'D://img//%s.jpg'%i)
if __name__ == '__main__':
getImage('feiji')
简单吧!比看网络简单吧O(∩_∩)O哈哈~,下面是我下的图
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









