










1.准备数据
下面是两个简单的矩阵:
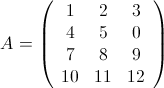
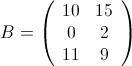
不难看出相乘结果为:
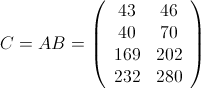
2.在HDFS上的存储方式
因为大矩阵一般为稀疏矩阵,因此,我们可以采用稀疏矩阵的存储方式,只存储那些非零的数值。存储矩阵的文件每一条记录的结构如下:
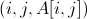
所以,矩阵A为(文件ytu_a):
1 1 1
1 2 2
1 3 3
2 1 4
2 2 5
3 1 7
3 2 8
3 3 9
4 1 10
4 2 11
4 3 12矩阵B为(文件ytu_b):
1 1 10
1 2 15
2 2 2
3 1 11
3 2 93.算法过程
矩阵乘法计算模型
设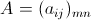 ,
,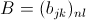 ,那么
,那么
,,那么
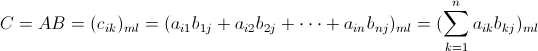
转化成mapreduce过程如下:
(1)在Map阶段,把来自矩阵A的元素Aij,标识成l条<key, value>的形式。其中key=(i,k),k=1,2,...l,其中l为矩阵B的列数,value = ('a',j,Aij);把来自矩阵B的元素Bij,标识成m条<key, value>形式,其中key=(k,j),k=1,2,...m,其中m为矩阵A的行数,value = ('b',i,Bij);
在Map阶段,我们通过key,我们把参与计算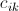 的数据归为一类。通过value,我们能区分元素是来自A还是B,以及具体的位置。
的数据归为一类。通过value,我们能区分元素是来自A还是B,以及具体的位置。
的数据归为一类。通过value,我们能区分元素是来自A还是B,以及具体的位置。
(2)在Shuffle阶段,相同key的value会被加入到同一个列表中,形成<key, list(value)>对,传递Reduce,这个由Hadoop自动完成。
(3)在Reduce阶段:
因为我们在Map阶段已经将key构造为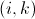 形式。而且我们也在Map阶段做了标志。
接下来所要做的,就是把list(value)解析出来,来自
形式。而且我们也在Map阶段做了标志。
接下来所要做的,就是把list(value)解析出来,来自
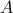 的元素,单独放在一个数组中,来自
的元素,单独放在一个数组中,来自
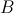 的元素,放在另一个数组中,然后,我们计算两个数组(各自看成一个向量)的点积,即可算出
的元素,放在另一个数组中,然后,我们计算两个数组(各自看成一个向量)的点积,即可算出
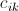 的值。
的值。
形式。而且我们也在Map阶段做了标志。
接下来所要做的,就是把list(value)解析出来,来自
的元素,单独放在一个数组中,来自
的元素,放在另一个数组中,然后,我们计算两个数组(各自看成一个向量)的点积,即可算出
的值。
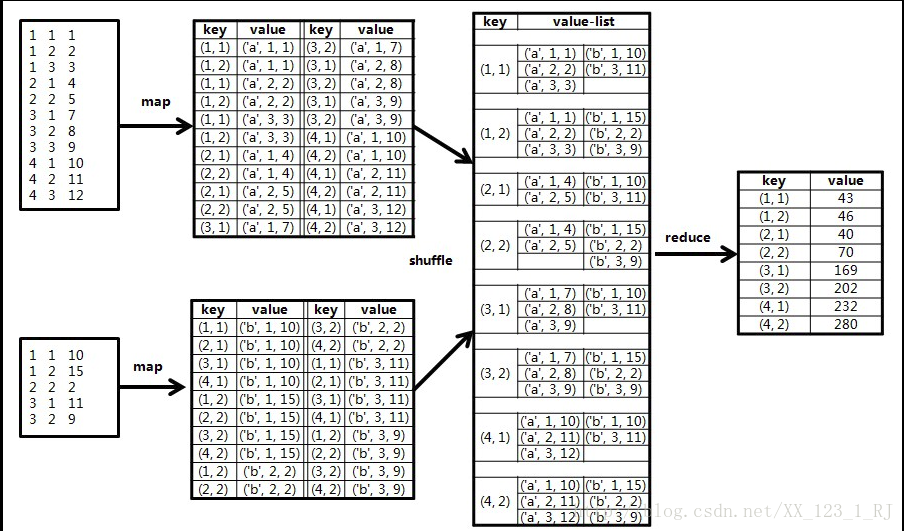
示例矩阵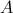 和
和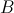 相乘的计算过程如下图所示:
相乘的计算过程如下图所示:
和相乘的计算过程如下图所示:
package com.xing.multiply;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.util.GenericOptionsParser;
/**
*
* @author LiuYinxing
*
*/
public class Matrix_Multiply
{
public static final String CONTROL_I = "\u0009";
public static final int MATRIX_AM = 4; //矩阵A的行数
public static final int MATRIX_ABN = 3;//矩阵A的列数 和 矩阵B的行数
public static final int MATRIX_BL = 2; //矩阵B的列数
private static class MatrixMapper extends Mapper<LongWritable, Text, Text, Text>
{
private String file;
public void map(LongWritable key, Text value, Context context) throws IOException, ClassCastException, InterruptedException {
// 获取输入文件的全路径和名称
FileSplit fileSplit = (FileSplit) context.getInputSplit();
file = fileSplit.getPath().getName();
if(file.equals("ytu_a"))
{
String line = value.toString();
if ( line == null || line.equals("") )
return;
String[] values = line.split(" ");
if (values.length < 3)
return;
String rowindex = values[0]; //A矩阵的行下标
String colindex = values[1];//A矩阵的列下标
String elevalue = values[2]; //A矩阵的Aij的值
for (int i = 1; i <= MATRIX_BL; i ++)
{ //输出<key,value> <(i,k),('a#',j,Aij)> k=MATRIX_BL
context.write(new Text(rowindex + CONTROL_I + i), new Text("a#"+colindex+"#"+elevalue));
}
}
else //如果是矩阵B
{
String line = value.toString();
if (line == null || line.equals(""))
return;
String[] values = line.split(" ");
if (values.length < 3)
return;
String rowindex = values[0];//B矩阵的行下标
String colindex = values[1];//B矩阵的列下标
String elevalue = values[2]; //B矩阵的Aij的值
for (int i = 1; i <= MATRIX_AM; i ++)
{ //输出<key,value> <(k,j),('b#',j,Aij)> k=MATRIX_AM
context.write(new Text(i + CONTROL_I + colindex), new Text("b#"+rowindex+"#"+elevalue));
}
}
}
}
public static class MatrixReducer extends Reducer<Text, Text, Text, Text>
{
@Override
protected void reduce(Text key, Iterable<Text> values,Context context)
throws IOException, InterruptedException {
int[] valA = new int[MATRIX_ABN];//矩阵A的列数 = 矩阵B的行数
int[] valB = new int[MATRIX_ABN];//矩阵B的行数 = 矩阵A的列数
int i;
for (i = 0; i < MATRIX_ABN; i ++) //初始化数组
{
valA[i] = 0;
valB[i] = 0;
}
for(Text line:values)
{
String value = line.toString();
if (value.startsWith("a#")) //取出矩阵A的数据
{
StringTokenizer token = new StringTokenizer(value, "#");
String[] temp = new String[3];
int k = 0;
while(token.hasMoreTokens())
{//temp[a][j][Aij]
temp[k] = token.nextToken();
k++;
}
valA[Integer.parseInt(temp[1])-1] = Integer.parseInt(temp[2]);
}
else if (value.startsWith("b#")) //取出矩阵B的数据
{
StringTokenizer token = new StringTokenizer(value, "#");
String[] temp = new String[3];
int k = 0;
while(token.hasMoreTokens())
{//temp[b][i][Bij]
temp[k] = token.nextToken();
k++;
}
valB[Integer.parseInt(temp[1])-1] = Integer.parseInt(temp[2]);
}
}
int result = 0;
for (i = 0; i < MATRIX_ABN; i ++)
{
result += valA[i] * valB[i];
}
//输出结果<坐标,值>=<(x,y),value>
context.write(key, new Text(Integer.toString(result)));
}
}
public static void main(String[] args) throws Exception {
//job开始时间
long main_start=System.currentTimeMillis();
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2)
{
System.err.println("Usage: Matrix_Multiply <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "Matrix_Multiply ");
job.setJarByClass(Matrix_Multiply.class);
job.setMapperClass(MatrixMapper.class);
// job.setCombinerClass(MatrixReducer.class);
job.setReducerClass(MatrixReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
// System.exit(job.waitForCompletion(true) ? 0 : 1);
if (job.waitForCompletion(true)) {
long main_end=System.currentTimeMillis(); //job正常结束的时间
System.out.println("程序已经运行结束");
System.out.println("矩阵相乘程序一共运行了"+ " : "+(main_end - main_start) +" ms");
System.exit(0);
}else {
System.out.println("程序没有正常结束");
}
}
}

6.思考存在的问题:
如果两个1000*1000的稠密矩阵相乘,那么每个元素都要拷贝1000份,那么记录数目达到2*10^9条,占用的空间大小为二三十G,那么对于更大规模的矩阵运算,文件空间要占用多大那?














 758
758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









