







核心内容:
1、 Could not find the main class: org.apache.spark.launcher.Main. Program will exit.
2、 failed to launch org.apache.spark.deploy.worker.Worker:
今天在安装Spark的伪分布运行模式下,启动hadoop之后总是报一个错误:
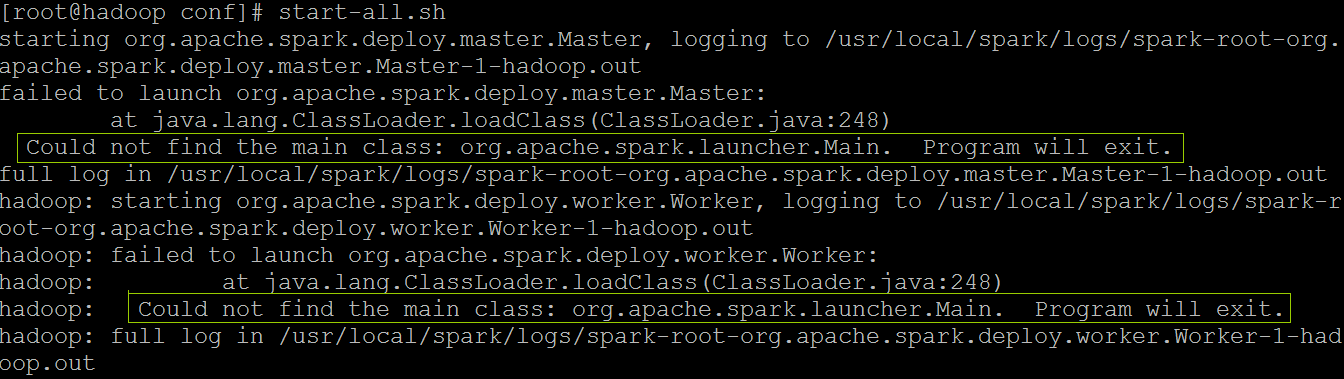
即启动的过程中无法加载主类: Could not find the main class: org.apache.spark.launcher.Main. Program will exit.
在百度之后,在帮助帖:http://bbs.csdn.net/topics/391835718 中找到了答案:
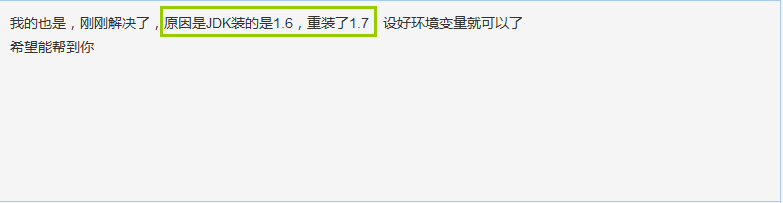
于是查看自己的JDK版本:
[root@hadoop conf]# java -version
java version "1.6.0_24"
Java(TM) SE Runtime Environment (build 1.6.0_24-b07)
Java HotSpot(TM) Client VM (build 19.1-b02, mixed mode, sharing)没想到安装JDK真的是1.6版本,到这里也理解了为什么Spark的最低Jdk版本是1.7了。
解决措施:安装JDK1.8
[root@hadoop conf]# java -version
java version "1.8.0_11"
Java(TM) SE Runtime Environment (build 1.8.0_11-b12)
Java HotSpot(TM) Client VM (build 25.11-b03, mixed mode)但是让人不爽的是启动之后,Master节点启动了,但是Worker节点没有启动:
[root@hadoop local]# start-all.sh
org.apache.spark.deploy.master.Master running as process 8591. Stop it first.
hadoop: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop.out
hadoop: failed to launch org.apache.spark.deploy.worker.Worker:
hadoop: at org.apache.spark.deploy.worker.Worker$.main(Worker.scala:691)
hadoop: at org.apache.spark.deploy.worker.Worker.main(Worker.scala)
hadoop: full log in /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop.out查看操作日志:
[root@hadoop local]# more /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop.out
Spark Command: /usr/local/jdk/bin/java -cp /usr/local/spark/conf/:/usr/local/spark/lib/spark-ass
embly-1.6.0-hadoop2.4.0.jar:/usr/local/spark/lib/datanucleus-core-3.2.10.jar:/usr/local/spark/li
b/datanucleus-api-jdo-3.2.6.jar:/usr/local/spark/lib/datanucleus-rdbms-3.2.9.jar:/usr/local/hado
op/etc/hadoop/ -Xms1g -Xmx1g org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://192
.168.80.100:7077
========================================
16/11/22 19:35:28 INFO worker.Worker: Registered signal handlers for [TERM, HUP, INT]
Exception in thread "main" java.lang.NumberFormatException: Size must be specified as bytes (b),
kibibytes (k), mebibytes (m), gibibytes (g), tebibytes (t), or pebibytes(p). E.g. 50b, 100k, or
250m.
Fractional values are not supported. Input was: 0.5
at org.apache.spark.network.util.JavaUtils.parseByteString(JavaUtils.java:244)
at org.apache.spark.network.util.JavaUtils.byteStringAsBytes(JavaUtils.java:255)
at org.apache.spark.util.Utils$.memoryStringToMb(Utils.scala:1037)
at org.apache.spark.deploy.worker.WorkerArguments.<init>(WorkerArguments.scala:46)
at org.apache.spark.deploy.worker.Worker$.main(Worker.scala:691)
at org.apache.spark.deploy.worker.Worker.main(Worker.scala)呵呵,原来是:
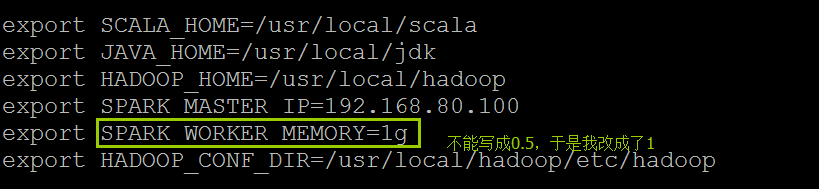
此时再次启动OK了!
[root@hadoop conf]# jps
7712 NameNode
8100 ResourceManager
9226 Jps
7819 DataNode
8187 NodeManager
9053 Worker
7950 SecondaryNameNode
8591 Master每次解决问题的过程其实很爽的!
















 2497
2497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











