







1、准备工作
scala-2.9.3:一种编程语言,下载地址:http://www.scala-lang.org/download/
spark-1.4.0:必须是编译好的Spark,如果下载的是Source,则需要自己根据环境使用SBT或者MAVEN重新编译才能使用。
编译好的 Spark下载地址:http://spark.apache.org/downloads.html。
2、安装scala-2.9.3
#解压scala-2.9.3.tgz
tar -zxvf scala-2.9.3.tgz
#配置SCALA_HOME
vi /etc/profile
#添加如下环境
export SCALA_HOME=/home/apps/scala-2.9.3
export PATH=.:$SCALA_HOME/bin:$PATH
#测试scala安装是否成功
#直接输入
scala
3、安装spark-1.4.0
#解压spark-1.4.0.tgz
tar -zxvf spark-1.4.0.tgz
#配置SPARK_HOME
vi /etc/profile
#添加如下环境
export SCALA_HOME=/home/apps/spark-1.4.0
export PATH=.:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
4、修改Spark配置文件
#复制slaves.template和 spark-env.sh.template各一份
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
#slaves,此文件是指定子节点的主机,直接添加子节点主机名即可
在spark-env.sh末端添加如下几行:
#JDK安装路径
export JAVA_HOME=/root/app/jdk
#SCALA安装路径
export SCALA_HOME=/root/app/scala-2.9.3
#主节点的IP地址
export SPARK_MASTER_IP=192.168.1.200
#分配的内存大小
export SPARK_WORKER_MEMORY=200m
#指定hadoop的配置文件目录
export HADOOP_CONF_DIR=/root/app/hadoop/etc/hadoop
#指定worker工作时分配cpu数量
export SPARK_WORKER_CORES=1
#指定spark实例,一般1个足以
export SPARK_WORKER_INSTANCES=1
#jvm操作,在spark1.0之后增加了spark-defaults.conf默认配置文件,该配置参数在默认配置在该文件中
export SPARK_JAVA_OPTS
spark-defaults.conf中还有如下配置参数:
SPARK.MASTER //spark://hostname:8080
SPARK.LOCAL.DIR //spark工作目录(做shuffle的目录)
SPARK.EXECUTOR.MEMORY //spark1.0抛弃SPARK_MEM参数,使用该参数
5、测试spark安装是否成功
在主节点机器上启动顺序
1、先启动hdfs(./sbin/start-dfs.sh)
2、启动spark-master(./sbin/start-master.sh)
3、启动spark-worker(./sbin/start-slaves.sh)
4、jps查看进程有
主节点:namenode、secondrynamnode、master
从节点:datanode、worker
5、启动spark-shell
15/06/21 21:23:47 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/06/21 21:23:47 INFO spark.SecurityManager: Changing view acls to: root
15/06/21 21:23:47 INFO spark.SecurityManager: Changing modify acls to: root
15/06/21 21:23:47 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
15/06/21 21:23:47 INFO spark.HttpServer: Starting HTTP Server
15/06/21 21:23:47 INFO server.Server: jetty-8.y.z-SNAPSHOT
15/06/21 21:23:47 INFO server.AbstractConnector: Started SocketConnector@0 .0.0.0:38651
15/06/21 21:23:47 INFO util.Utils: Successfully started service 'HTTP class server' on port 38651.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
进入Spark的Web管理页面: http://master:8080 http://master:4040

编写测试案例:
Wordcount示例
列表内容
在命令行输入:spark-shell开启spark(scala)
把输入文件加载进RDD:
val textFile = sc.textFile("YOUR_INPUT_FILE")
1
1
MapReduce操作,以work为key,1为value:
val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
1
1
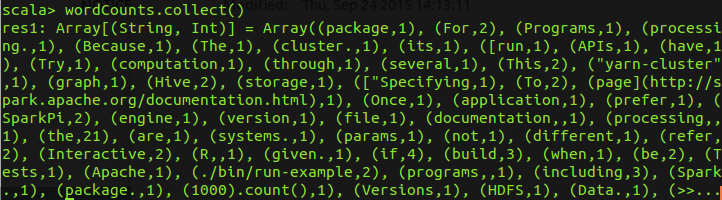
查看每个单词出现的次数
wordCounts.collect()
- 进入bin目录,输入./run-example SparkPi 10(迭代次数) 计算π的值
案例 计算单词出现频率
找到 spark目录下的 README.md 提交到 hdfs文件系统下然后输入
测试成功~















 2776
2776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









