







LRU
在读LruCache源码之前,我们先来了解一下这里的Lru是什么。LRU全称为Least Recently Used,即最近最少使用,是一种缓存置换算法。我们的缓存容量是有限的,它会面临一个问题:当有新的内容需要加入我们的缓存,但我们的缓存空闲的空间不足以放进新的内容时,如何舍弃原有的部分内容从而腾出空间用来放新的内容。解决这个问题的算法有多种,比如LRU,LFU,FIFO等。
需要注意区分的是LRU和LFU。前者是最近最少使用,即淘汰最长时间未使用的对象;后者是最近最不常使用,即淘汰一段时间内使用最少的对象。比如我们缓存对象的顺序是:A B C B D A C A ,当需要淘汰一个对象时,如果采用LRU算法,则淘汰的是B,因为它是最长时间未被使用的。如果采用LFU算法,则淘汰的是D,因为在这段时间内它只被使用了一次,是最不经常使用的。
了解了LRU之后,我们再来看一下LruCache是如何实现的。
LinkedHashMap
我们看一下LruCache的结构,它的成员变量及构造方法定义如下(这里分析的是android-23里的代码):
private final LinkedHashMap<K, V> map;
private int size; //当前缓存内容的大小。它不一定是元素的个数,比如如果缓存的是图片,一般用的是图片占用的内存大小
private int maxSize; // 最大可缓存的大小
private int putCount; // put 方法被调用的次数
private int createCount; // create(Object) 被调用的次数
private int evictionCount; // 被置换出来的元素的个数
private int hitCount; // get 方法命中缓存中的元素的次数
private int missCount; // get 方法未命中缓存中元素的次数
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);
}从上面的定义中会发现,LruCache进行缓存的内容是放在LinkedHashMap对象当中的。那么,LinkedHashMap是什么?它是怎么实现LRU这种缓存策略的?
LinkedHashMap继承自HashMap,不同的是,它是一个双向循环链表,它的每一个数据结点都有两个指针,分别指向直接前驱和直接后继,这一个我们可以从它的内部类LinkedEntry中看出,其定义如下:
static class LinkedEntry<K, V> extends HashMapEntry<K, V> {
LinkedEntry<K, V> nxt;
LinkedEntry<K, V> prv;
/** Create the header entry */
LinkedEntry() {
super(null, null, 0, null);
nxt = prv = this;
}
/** Create a normal entry */
LinkedEntry(K key, V value, int hash, HashMapEntry<K, V> next,
LinkedEntry<K, V> nxt, LinkedEntry<K, V> prv) {
super(key, value, hash, next);
this.nxt = nxt;
this.prv = prv;
}
}
LinkedHashMap实现了双向循环链表的数据结构,它的定义如下:
public class LinkedHashMap<K, V> extends HashMap<K, V> {
transient LinkedEntry<K, V> header;
private final boolean accessOrder;
} 当链表不为空时,header.nxt指向第一个结点,header.prv指向最后一个结点;当链表为空时,header.nxt与header.prv都指向它本身。accessOrder是指定它的排序方式,当它为false时,只按插入的顺序排序,即新放入的顺序会在链表的尾部;而当它为true时,更新或访问某个节点的数据时,这个对应的结点也会被放到尾部。它通过构造方法public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)来赋值。
我们来看一下加入一个新结点时的方法执行过程:
@Override void addNewEntry(K key, V value, int hash, int index) {
LinkedEntry<K, V> header = this.header;
// Remove eldest entry if instructed to do so.
LinkedEntry<K, V> eldest = header.nxt;
if (eldest != header && removeEldestEntry(eldest)) {
remove(eldest.key);
}
// Create new entry, link it on to list, and put it into table
LinkedEntry<K, V> oldTail = header.prv;
LinkedEntry<K, V> newTail = new LinkedEntry<K,V>(
key, value, hash, table[index], header, oldTail);
table[index] = oldTail.nxt = header.prv = newTail;
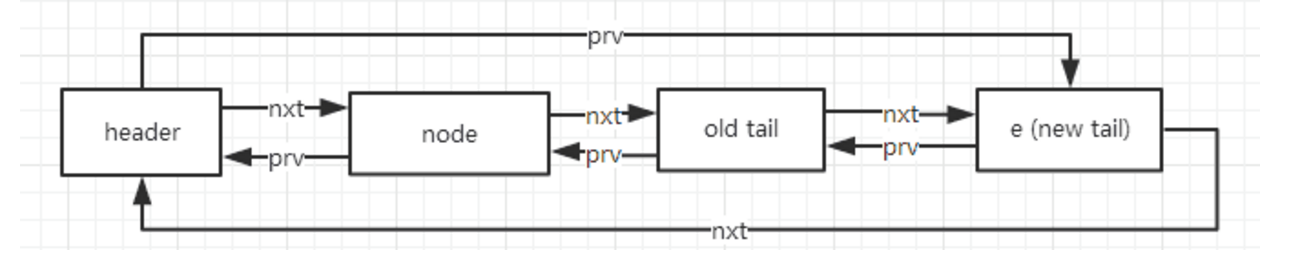
}可以看到,当加入一个新结点时,结构如下:

当accessOrder为true时,更新或者访问一个结点时,它会把这个结点移到尾部,对应代码如下:
private void makeTail(LinkedEntry<K, V> e) {
// Unlink e
e.prv.nxt = e.nxt;
e.nxt.prv = e.prv;
// Relink e as tail
LinkedEntry<K, V> header = this.header;
LinkedEntry<K, V> oldTail = header.prv;
e.nxt = header;
e.prv = oldTail;
oldTail.nxt = header.prv = e;
modCount++;
}以上代码分为两步,第一步是先把该节点取出来(Unlink e),如下图:

第二步是把这个这个结点移到尾部(Relink e as tail),也就是把旧的尾部的nxt以及头部的prv指向它,并让它的nxt指向头部,把它的prv指向旧的尾部。如下图:
除此之外,LinkedHashMap还提供了一个方法public Entry
LruCache
熟悉了LinkedHashMap之后,我们发现,通过它来实现Lru算法也就变得理所当然了。我们所需要做的,就只剩下定义缓存的最大大小,记录缓存当前大小,在放入新数据时检查是否超过最大大小。所以LruCache定义了以下三个必需的成员变量:
private final LinkedHashMap<K, V> map;
/** Size of this cache in units. Not necessarily the number of elements. */
private int size;
private int maxSize;然后我们来读一下它的get方法:
public final V get(K key) {
if (key == null) {
throw new NullPointerException("key == null");
}
V mapValue;
synchronized (this) {
mapValue = map.get(key);
if (mapValue != null) {// 当能获取到对应的值时,返回该值
hitCount++;
return mapValue;
}
missCount++;
}
/*
* Attempt to create a value. This may take a long time, and the map
* may be different when create() returns. If a conflicting value was
* added to the map while create() was working, we leave that value in
* the map and release the created value.
*/
//尝试创建一个值,这个方法的默认实现是直接返回null。但是在它的设计中,这个方法可能执行完成之后map已经有了变化。
V createdValue = create(key);
if (createdValue == null) {//如果不为没有命名的key创建新值,则直接返回
return null;
}
synchronized (this) {
createCount++;
//将创建的值放入map中,如果map在前面的过程中正好放入了这对key-value,那么会返回放入的value
mapValue = map.put(key, createdValue);
if (mapValue != null) {//如果不为空,说明不需要我们所创建的值,所以又把返回的值放进去
// There was a conflict so undo that last put
map.put(key, mapValue);
} else {
size += safeSizeOf(key, createdValue);//为空,说明我们更新了这个key的值,需要重新计算大小
}
}
if (mapValue != null) {//上面放入的值有冲突
entryRemoved(false, key, createdValue, mapValue);// 通知之前创建的值已经被移除,而改为mapValue
return mapValue;
} else {
trimToSize(maxSize);//没有冲突时,因为放入了新创建的值,大小已经有变化,所以需要修整大小
return createdValue;
}
}LruCache是可能被多个线程同时访问的,所以在读写map时进行加锁。当获取不到对应的key的值时,它会调用其create(K key)方法,这个方法用于当缓存没有命名时计算一个key所对应的值,它的默认实现是直接返回null。这个方法并没有加上同步锁,也就是在它进行创建时,map可能已经有了变化。
所以在get方法中,如果create(key)返回的V不为null,会再把它给放到map中,并检查是否在它创建的期间已经有其他对象也进行创建并放到map中了,如果有,则会放弃这个创建的对象,而把之前的对象留下,否则因为我们放入了新创建的值,所以要计算现在的大小并进行trimToSize。
trimToSize方法是根据传进来的maxSize,如果当前大小超过了这个maxSize,则会移除最老的结点,直到不超过。代码如下:
public void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
if (size <= maxSize) {
break;
}
Map.Entry<K, V> toEvict = map.eldest();
if (toEvict == null) {
break;
}
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}
接下来,我们再来看put方法,它的代码也很简单:
public final V put(K key, V value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
putCount++;
size += safeSizeOf(key, value);
previous = map.put(key, value);
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
if (previous != null) {
entryRemoved(false, key, previous, value);
}
trimToSize(maxSize);
return previous;
}主要逻辑是,计算新增加的大小,加入size,然后把key-value放入map中,如果是更新旧的数据(map.put(key, value)会返回之前的value),则减去旧数据的大小,并调用entryRemoved(false, key, previous, value)方法通知旧数据被更新为新的值,最后也是调用trimToSize(maxSize)修整缓存的大小。
剩下的其他方法,比如删除里面的对象,或进行调整大小的操作,逻辑上都和上面的类似,这里略过。LruCache还定义了一些变量用于统计缓存命中率等,这里也不再进行赘述。
结语
LruCache的源码分析就到这里,它对LRU算法的实现主要是通过LinkedHashMap来完成。另外,使用LRU算法,说明我们需要设定缓存的最大大小,而缓存对象的大小在不同的缓存类型当中的计算方法是不同的,计算的方法通过protected int sizeOf(K key, V value)实现,这里的默认实现是存放的元素的个数。举个例子,如果我们要缓存Bitmap对象,则需要重写这个方法,并返回bitmap对象的所有像素点所占的内存大小之和。还有,LruCache在实现的时候考虑到了多线程的访问问题,所以在对map进行更新时,都会加上同步锁。
LruCache是对LRU策略的内存缓存的实现,基于它,我们可以去实现自己的图片缓存或其它缓存等。除了内存缓存的LRU算法实现,谷歌在后来的系统源码中也曾经加上该算法的磁盘缓存的实现,目前在android-23的示例DisplayingBitmaps中,也有对应的源码DiskLruCache.java。对了,关于如何使用LruCache来实现图片内存缓存的具体代码,同样可以参照谷歌提供的这个示例代码中的ImageCache.java(在线浏览示例代码请翻墙访问:https://android.googlesource.com/platform/developers/samples/android/+/master/ui/graphics/DisplayingBitmaps/Application/src/main/java/com/example/android/displayingbitmaps/util/)。
另外,啰嗦一句:LRU的缓存策略由来已久,图片缓存也并非没有策略,弱引用和软引用更不是各种图片框架没流行之前的很常用的内存缓存技术,垃圾回收机制更倾向于回收弱引用和软引用对象的这种说法也是不妥当的。















 482
482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









