







 皮尔逊相似度是推荐系统中用于计算用户间相似度的常见方法,但它存在一些局限性,如无法处理全相同评分或数据稀疏的情况。本文提供了Python实现的代码示例。
皮尔逊相似度是推荐系统中用于计算用户间相似度的常见方法,但它存在一些局限性,如无法处理全相同评分或数据稀疏的情况。本文提供了Python实现的代码示例。
皮尔逊相似度是推荐算法中常见的 计算相似度的方法,其公式如下:
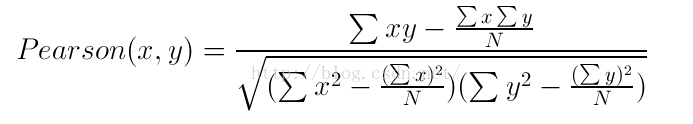
从公式可以看出 该算法有几个缺点:
1,如果用户A对所有item的评分都一样,那么将无法计算别人跟A的相似度(分母为0);所以该算法不适用于 boolean preference类型的推荐
2,如果用户A只对1个item进行了评分,那么也无法计算别人跟A的相似度(分母为0);所以对于数据量较小,或者矩阵非常之稀疏的数据都不太好用
3,如果2个人有200个common item,尽管ratings并不总是一样,但她们的相似度 可能好于2个只有2 commen item的人的相似度(这个我不能直接从公式看出来,哪位大神指点一下)
下面是python实现:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4363
4363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









