







啥也不说,先上代码
#-*-coding:utf-8 -*-
#-*-encoding:utf8 -*-
import urllib2
import BeautifulSoup
import codecs
User_Agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0'
header = {}
header['User-Agent'] = User_Agent
url = 'http://www.xicidaili.com/nn/1'
req = urllib2.Request(url,headers=header)
res = urllib2.urlopen(req).read()
soup = BeautifulSoup.BeautifulSoup(res)
ips = soup.findAll('tr')
f = codecs.open("./proxy","w", 'utf-8')
for x in range(1, len(ips)):
ip = ips[x]
tds = ip.findAll("td")
ip_temp = tds[1].contents[0]+"\t"+tds[2].contents[0]+"\n"
f.write(ip_temp)
f.close()
import urllib
import socket
socket.setdefaulttimeout(3)
f = open("./proxy")
fd_proxy = codecs.open("./access.txt", "w", 'utf-8')
lines = f.readlines()
proxys = []
for i in range(0, len(lines)):
ip = lines[i].strip("\n").split("\t")
proxy_host = "http://" + ip[0] + ":" + ip[1]
proxy_temp = {"http":proxy_host}
proxys.append(proxy_temp)
url = "http://ip.chinaz.com/getip.aspx"
for proxy in proxys:
try:
res = urllib.urlopen(url,proxies=proxy).read()
fd_proxy.write(proxy["http"]+"\n")
print res
except Exception,e:
print proxy
print e
continue
f.close()
fd_proxy.close()我们获取的代理服务器网址位于 http://www.xicidaili.com/nn/1
里面会经常更新可用的代理服务器ip,如图所示

在safari浏览器页面右键弹出快捷菜单,选择显示页面源文件就能看到如下界面:
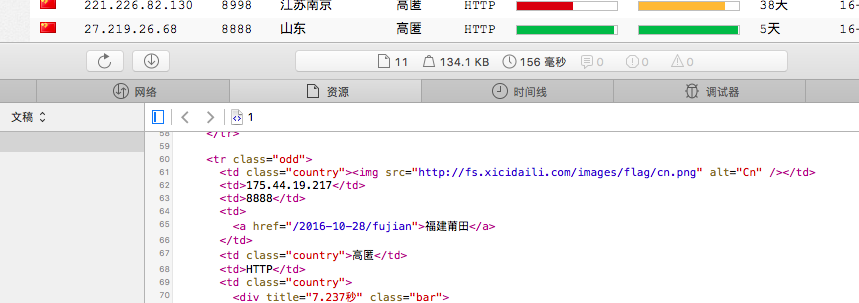
我们先获得tr字段,然后从tr字段中选择ip地址所在的td字段就能把代理服务器地址给提取出来,同样的方法提取端口号,然后保存为文件proxy。
保存下来后,不能保证每一个代理服务器地址都是可以连接的,需要进行测试,后半部分代码就是把保存在proxy文件中的ip地址一个个拿出来,通过访问页面 http://ip.chinaz.com/getip.aspx 进行测试。
















 3848
3848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











