







sqlite3树形结构遍历效率对比测试
一、缘起
项目数据结构:本人从事安防行业,视频监控领域。项目中会遇到监控点位的组织机构划分、临时划分的巡逻点位等。这些相机点位、连同组织机构,它们在逻辑关系上构成了一个树形结构。
二、方案
方案3:sql语句递归查询
方案1、2的思路都是在sql语句之外递归查询。如果能够写出递归的sql语句,效果是不是能更好呢?于是有了方案3。简单来说,方案3是将方案2中用函数实现的"查找子节点的子节点的子节点......",替换为用sql语句来实现。
关于sqlite3的递归语句,请参考我的另外一篇博文《sqlite3-递归查询》。
这里要注意一下,sqlite3的递归语法 with recursive 可能在 其3.7.X 及以下版本不受支持,可能会提示语法错误syntax error。我的sqlite3库升级到3.8.x之后就能查询到结果了。
方案4:引入关系表
现在数据库表的结构如下图所示。

它是一种结构化的数据库表结构。将节点的id和父节点id都存储在一个记录中。好处是开发时候快速,坏处是,不便于扩展和修改。
说它不便于扩展,是因为假如一个节点有两个父节点,则一个字段无法满足。再加一个father_id字段吗?显然不现实,因为不知道会有多少个父节点。
说它不便于修改,是因为,如果将多个父节点id都采用格式化都填入father_id字段,则在维护记录的时候会带来“拼串和解析串”的步骤,带来维护上的麻烦。
那么,是否可以换一种思路,采用面向对象的思维创建数据库表呢?于是想到了下面的表结构和表关系。

如图所示,增加一个关系表,专门用来存储节点之间的关系。将father_id和son_id作为联合主键。如此一来,节点与节点之间的关系,其实就对应的是关系表中的一条记录!一个节点有多少个子节点,关系表中就有多少条记录。一个节点有多少个父节点,也是这样。
这样改造了数据库表之后,带来的好处是显而易见的,
首先是可维护性的提升。从以前的解析修改表字段,到现在的插入删除一条或多条记录。
其次是开发维护人员对于数据的关系也会理解地更加深刻和清楚。
但不可避免,也有不足之处,
首先是开发的成本。这样的表结构和表关系,不利于快速开发。
其次是现在的软件系统已经用了好几年,突然修改,可能会造成现场维护上的压力突然增大。
第三,这样的结构,是否满足业务功能要求的效能,还是个未知数。
三、结果对比
下面给出上述方案1、2、3的测试对比表。
方案1

方案2

方案3
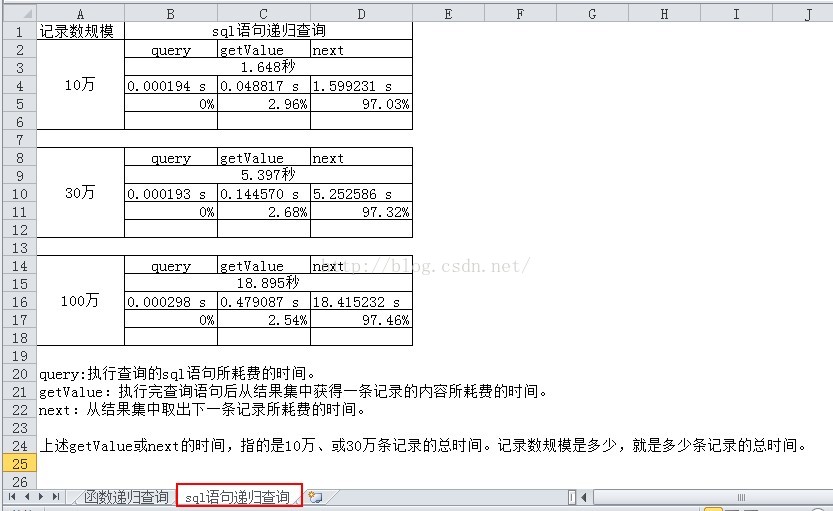
从理论上来讲,查询得到结果的效率是 方案3 > 方案1 > 方案2。
从上面3个表来看,结果的确如期望的那样。
但是,有些意外的是,方案3中从结果集中获取下一条记录这一步骤(即next),太占用时间,竟然达到了97%的占比。
从综合效率上来看,方案1时间最快。其次是方案3,最慢的是方案2。因为方案2要执行大量的函数递归调用,函数栈切换,这是最为耗时的。














 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









