





第二篇:用右值引用来转移
这是关于C++中的高效值类型的系列文章中的第二篇。在上一篇中,我们讨论了复制省略如何被用来消除可能发生的多次复制操作。复制省略是透明的,在看起来非常普通的代码中自动发生的,几乎没有任何缺点。好消息已经够多了;下面看看坏的消息:
- 复制省略不是标准强制要求的,因此你写不出可以保证它会发生的可移植代码。
- 有些时候这也做不到。例如:
被调用者最多可以将调用者传入的内存用于 var1 或 var2 其中一个。如果它选择将 var1 保存在该内存中,而 q 为 false,那么 var2 还是要被复制(反之亦然)。return q ? var1 : var2;- 复制省略很有可能超出编译器的栈空间分配技巧的能力。
低效转移
当一个操作是要对数据进行重排时,有很多机会可以进行优化。以一个简单的泛型插入排序算法为例:
template <class Iter>
void insertion_sort(Iter first, Iter last)
{
if (first == last) return;
Iter i = first;
while (++i != last) // Invariant: elements preceding i are sorted
{
Iter next = i, prev = i;
if (*--prev > *i)
{
typename std::iterator_traits<Iter>::value_type x(*next);
do *next = *prev;
while(--next != first && *--prev > x);
*next = x;
}
}
} 
第7行:外层循环的不变式
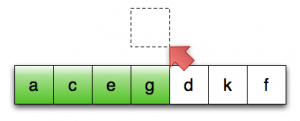
第12行:将第一个未排序元素复制至临时位置
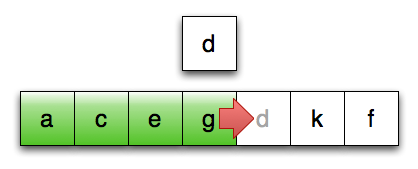
第13行:将最后一个已排序元素复制向后复制
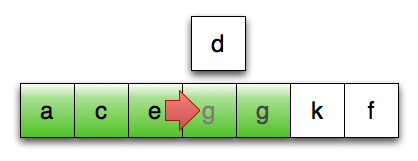
第13行:继续向后复制,直至找到合适位置
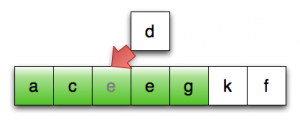
第15行:将临时位置的元素复制至正确位置
想象一下,如果进行排序的序列中的元素是 std::vector<std::string>,会发生什么:在第12、13、15行,我们要潜在地复制一个字符串 vector,这会导致大量的内存分配和数据复制。
由于排序操作从根本上说,是一种数据守恒的操作,所以这些数据复制的开销应该都是可避免的:原则上,我们真正要做的就是将对象在序列中移来移去。
对于这些高代价的复制操作,要留意的一个重点是,在所有情况下,源对象的值都不会再被使用。听起来很熟悉吧?是的,当源对象是右值时也是如此。不过这次源对象是左值:这些对象都是有地址的。
引用计数可以吗?
解决这类低效问题的一个常用方法是,在堆上分配元素并在序列(容器)中持有指向这些元素的引用计数智能指针,而不是直接保存这些元素。引用计数智能指针跟普通的指针类似,只是它还跟踪了有多少引用计数智能指针指向同一个对象,并且会在最后一个智能指针被删时销毁对象。复制一个引用计数指针只需递增其引用计数即可,这是很快的。对引用计数指针赋值则是递增一个引用计数且递减另一个。这也是很快的。
那么,还可以更快吗?当然是根本就不进行计数!另外,引用计数还有其它一些我们希望避免的弱点:
- 它的开销在多线程环境中是非常大的,因为计数本身要跨线程共享,这就需要同步。
- 在泛型代码中该方法要失效,因为元素的类型有可能是象 int 这样的轻量型类型。在这种情况下,引用计数的增减才是真正的性能开销。你要么忍受这种开销,要么就必须引入一个复杂的框架来确定哪些类型是轻量型的,应该直接保存,同时还要以统一的风格来访问这些值。
- 引用语义会使得代码难以阅读。例如:
将 s2 变为大写同时会修改到 s1 的值。这是一个比我们在这里讨论的要大得多的主题,简而言之,当数据共享被隐藏时,看似局部的修改,其效果却不一定是完全局部的。typedef std::vector<std::shared_ptr<std::string> > svec; … svec s2 = s1; std::for_each( s2.begin(), s2.end(), to_uppercase() );
引入C++0x的右值引用
为了解决这些问题,C++0x 引入了一种新的引用,右值引用。T 的右值引用写作 T&&(读作“tee ref-ref”),我们现在将原来的 T& 引用称为“左值引用”。就我们讨论的范围而言,左值引用与右值引用的主要区别在于,非 const 的右值引用可以绑定至右值。许多C++程序员都曾经遇到过这样的错误提示:
invalid initialization of non-const reference of type 'X&'
from a temporary of type 'X'这类提示通常是由以下这样的代码引起的:
X f(); // call to f yields an rvalue
int g(X&);
int x = g( f() ); // error标准规定,非 const 的(左值)引用应绑定至一个左值,而不是一个临时对象(即一个右值)。这是有意义的,因为对引用所引向的临时对象进行的任何修改都肯定会丢失。与之相反,非 const 右值引用应绑定至一个临时对象,而不是一个左值:
X f();
X a;
int g(X&&);
int b = g( f() ); // OK
int c = g( a ); // ERROR: can't bind rvalue reference to an lvalue偷取资源
假设我们的函数 g() 要保存一份它的参数的拷贝,以备后用:
static X cache;
int g(X&& a)
{
cache = a; // keep it for later
}
int b = g( X() ); // call g with a temporary依赖于类型 X,这个复制可能是开销很大的操作,可能引起内存分配和许多子对象的深度复制。
由于 g() 的参数是一个右值引用,我们知道它只能自动绑定到匿名临时对象,而不是其它对象。因此,
- 在我们把这个临时对象复制到 cache 之后不久,被复制的源对象就会被销毁。
- 我们对这个临时对象的任何修改,对于程序的其它地方都是不可见的。
这给了我们一个机会来执行一些新的优化,通过修改临时对象的值来避免多余的工作。最为常见的一种优化就是资源偷取。
资源偷取是指从一个对象取走资源(如内存、大的子对象)并将资源转移给另一个对象。例如,string 类可能拥有一个在堆上分配的字符缓冲区。复制一个 string 需要分配一块新的缓冲区并将所有字符复制到新的缓冲区中,这看起来很慢。而偷取一个 string 则只需要让另一个对象取走这个 string 的缓冲区并通知源对象它不再拥有有效的缓冲区——这个操作要快很多。使用右值引用,我们可以通过把从临时对象复制改为从临时对象偷取,来优化我们的代码。同时,由于只有临时对象被改变,所以这个优化在逻辑上是无改写的。
说明:从右值引用偷取(或修改)可以在逻辑上视为无改写操作。
右值重载用法
从以上说明我们可以得到一个新的维持语义的编程变化:我们可以用另一个在同一位置接受右值引用的版本来对接受一个(const)引用参数的任意函数进行重载:
void g(X const& a) { … } // doesn't mutate argument
void g(X&& a) { modify(a); } // new overload; logically non-mutatingg 的第二个重载版本可以修改它的参数,但不会对程序的其它地方产生影响,所以它具有与第一个重载版本相同的语义。
绑定与重载
下表总结了 C++0x 对于引用绑定与重载的完整规则:
表达式→ 引用类型↓ | T 右值 | const T 右值 | T 左值 | const T 左值 | 优先级 |
| T&& | X | 4 | |||
| const T&& | X | X | 3 | ||
| T& | X | 2 | |||
| const T& | X | X | X | X | 1 |
“优先级”一列描述了这些引用在重载决议中的行为。例如,给出以下重载:
void f(int&&); // #1
void f(const int&&); // #2
void f(const int&); // #3把一个 const int 类型的右值传入 f,将会调用#2,因为#1无法绑定而#3的优先级较低。
声明一个可转移的类型
有了以上方法,我们可以通过两个新的操作,转移构造和转移赋值,来令任意类型的右值成为可隐式转移的,这两个操作都是接受右值引用参数。例如,一个可转移的 std::vector 在 C++0x 中可能会这样写:
template <class T, class A>
struct vector
{
vector(vector const& lvalue); // copy constructor
vector& operator=(vector const& lvalue); // copy assignment operator
vector(vector&& rvalue); // move constructor
vector& operator=(vector&& rvalue); // move assignment operator
…
};转移构造函数和转移赋值操作符的工作就是从它的参数中“偷取”资源,然后将参数置于一个可析构或可赋值的状态。
在 std::vector 的例子中,这可能意味着将其参数置回空容器的状态。一个典型的 std::vector 实现包含有三个指针:一个指向已分配空间的起始,一个指向最后一个元素,还有一个指向已分配空间的结尾。所以,当容器为空时,这三个指针均为 null,转移构造函数会象这样:
vector(vector&& rhs)
: start(rhs.start) // adopt rhs's storage
, elements_end(rhs.elements_end)
, storage_end(rhs.storage_end)
{ // mark rhs as empty.
rhs.start = rhs.elements_end = rhs.storage_end = 0;
}而转移赋值操作符可能会是这样:
vector& operator=(vector&& rhs)
{
std::swap(*this, rhs);
return *this;
}由于右值参数会马上被销毁,所以交换操作不仅获取它的资源,同时还将我们本来拥有的资源“安排好”准备销毁。
注意:先别太高兴,这个转移赋值操作符还不是很正确。右值引用与复制省略
std::vector 的转移构造函数的开销非常低(大约只有对内存的3次读和6次写),但也还不是免费的。幸好,标准列明了复制省略(这是真正无代价的)的优先级高于转移操作。当你把一个右值以传值方式进行传递时,或是从某个函数返回一个值时,编译器首先应选择消除复制。如果复制不能被消除,而相应的类型又具有转移构造函数,编译器就被要求使用转移构造函数。最后,如果连转移构造函数都没有,编译器就只能使用复制构造函数了。
举例:
A compute(…)
{
A v;
…
return v;
}- 如果 A 具有可访问的复制构造函数或转移构造函数,则编译器可以选择消除复制
- 否则,如果 A 具有转移构造函数,则 v 被转移
- 否则,如果 A 具有复制构造函数,则 v 被复制
- 否则,编译器报错
因此,上一篇文章中的指引依然有效:
指引:不要复制你的函数参数。而应该以传值的方式来传递它,让编译器来做复制。
以这个指引的提示下,你可能会问:“除了转移构造函数和转移赋值操作符,我还可以在哪里使用右值重载用法呢?一旦我的所有类型都是可转移的,那么还有什么要做的呢?”请看以下例子。
从左值转移
所有的这些转移优化都具有一个共通点:当我们不再使用源对象时才可以进行优化。但是有些时候,我们需要提醒一下编译器。例如:
void g(X);
void f()
{
X b;
g(b);
…
g(b);
}在第8行中,我们以一个左值来调用 g,这样就不能进行资源偷取——即使我们知道 b 已不会再被用到。为了告诉编译器可以从 b 进行转移,我们可以用 std::move 来传递它:
void g(X);
void f()
{
X b;
g(b); // still need the value of b
…
g( std::move(b) ); // all done with b now; grant permission to move
}注意,std::move 本身并不做任何转移。它只是将参数变为一个右值引用,以便于在符合“转移优化”的环境中可以采用转移优化。当你看到 std::move 时,你可以这样想:授予转移的权限。你也可以将 std::move(a) 看作是 static_cast<X&&>(a) 的描述方式。
高效转移
现在我们有办法对左值进行转移了,我们可以将前几节中的 insertion_sort 算法优化一下:
template
void insertion_sort(Iter first, Iter last)
{
if (first == last) return;
Iter i = first;
while (++i != last) // Invariant: [first, i) is sorted
{
Iter next = i, prev = i;
if (*--prev > *i)
{
typename std::iterator_traits::value_type
x( std::move(*next) );
do *next = std::move(*prev);
while(--next != first && *--prev > x);
*next = std::move(x);
}
}
}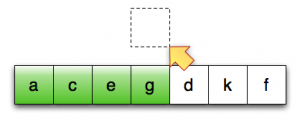
第12行:将第一个未排序元素移至临时位置
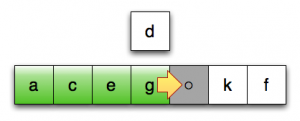
第13行:将最后一个已排序元素向后移

第13行:继续后移
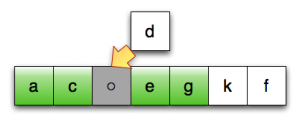
第15行:将临时位置中的元素移至正确位置
除了格式上的差异以外,这个版本与前一个的区别仅在于增加了对 std::move 的调用。值得指出的是,我们只需要这一个 insertion_sort 的实现,不论元素类型是否具有转移构造函数。这是典型的可转移代码:右值引用的设计是让你“在可以的时候转移,有必须的时候复制”。
后续内容
暂时先到这里了,不过这个系列的文章还会继续的(很快,我保证——材料已经着手在写了!),内容将覆盖右值复活、异常安全、完美前转等等。哦,对了:我们还将告诉你如何正确写出 vector 的转移赋值操作符。回头见!















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









