






MapReduce适合离线计算
Storm适合流式计算,实时计算
MapReduce——移动计算 不移动数据
移动计算:把写好的计算程序分别拷贝一份到不同的机器上
HDFS上存储的数据,作为MapReduce的输入
每一个片段split,由一个map线程执行 (如何把hdfs上的文件切分成split,按照怎样的规则去切分)
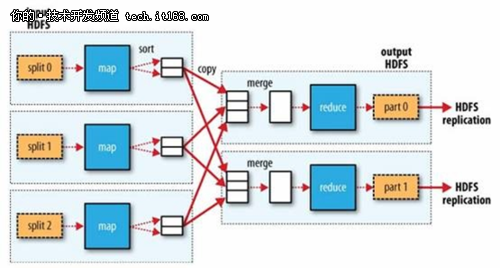
例子 word count
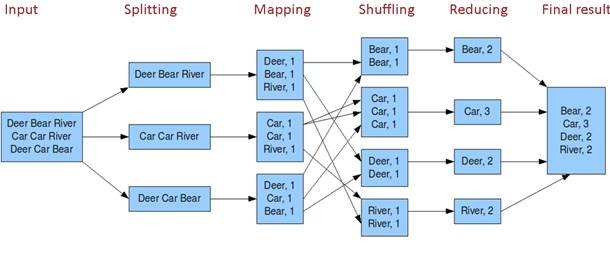
shuffling阶段是mapper和reducer中间步骤
可以吧mapper的输出按照某种key,value重新切分和组合成n份,把key值符合某种范围的输出送到特定的ereducer去处理,可以简化reducer过程
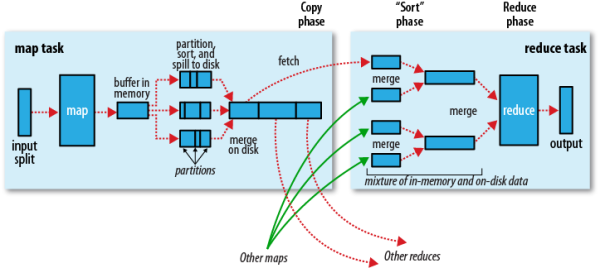
分区、排序、溢写到磁盘,由于map输出的结果存在内存中,内存有溢值,超过这个值,就写到磁盘中
默认分区partition方式是:哈希摸运算,模reduce的个数。partition把map的数据分成一块块区域,每一个区域对应一个reduce去执行
reduce阶段的“数据倾斜”,整数模reduce的个数之后,得到的0或1的数量不同,可能产生数据倾斜。
为避免数据倾斜,需要更改partition规则,重新定义分区方式
默认排序sort方式是:按照对象对应的ask码排序————字典排序
merge步骤为了减少map阶段网络输出
shuffle过程详解:
——每个map task都有一个内存缓冲区(默认100MB),存储map的输出结果
——缓冲区快满的时候,需要将缓冲区的数据以一个临时文件的方式存到磁盘(spill溢写 to disk)
——溢写由单独线程完成,不影响往缓冲区写map结果的线程
——当溢写线程启动后,需要对着80MB空间内的key排序(sort)
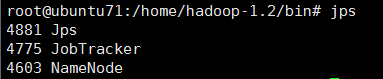
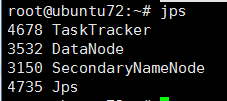
MapReduce的主从结构
主:JobTracker(随意指定)
从:TaskTracker
以71机器作为JobTracker,在71机器上修改配置文件
再把配置文件同步到其他机器

启动mapreduce
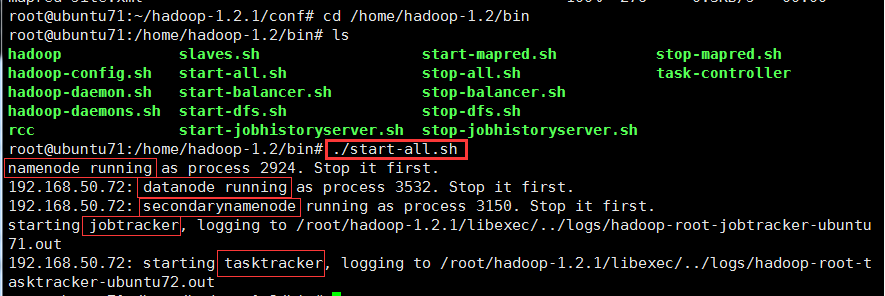
71机器
72机器
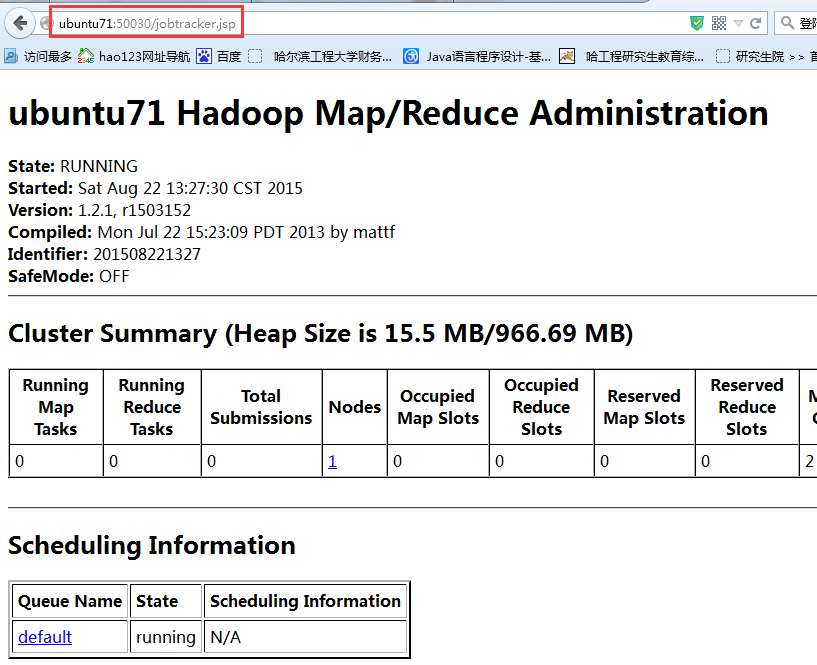
访问
通过eclipse插件,连接HDFS,以下是eclipse插件的源码所在位置

http://my.oschina.net/allman90/blog/296841跑wordcount,参考参考,谢谢分享














 1221
1221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









