










1 主要区别
1.1、Hbase适合大量插入同时又有读的情况
1.2、 Hbase的瓶颈是硬盘传输速度,Oracle的瓶颈是硬盘寻道时间。
Hbase本质上只有一种操作,就是插入,其更新操作是插入一个带有新的时间戳的行,而删除是插入一个带有插入标记的行。其主要操作是收集内存中一批数据,然后批量的写入硬盘,所以其写入的速度主要取决于硬盘传输的速度。Oracle则不同,因为他经常要随机读写,这样硬盘磁头需要不断的寻找数据所在,所以瓶颈在于硬盘寻道时间。
1.3、Hbase很适合寻找按照时间排序top n的场景
1.4、索引不同造成行为的差异。
1.5、Oracle 既可以做OLTP又可以做OLAP,但在某种极端的情况下(负荷十分之大),就不适合了。
2 Hbase的局限:
1、只能做简单的Key value查询,复杂的sql统计做不到。
2、只能在row key上做快速查询。
3 传统数据库的行式存储
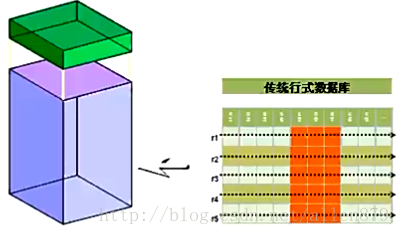
在数据分析的场景里面,我们经常是以某个列作为查询条件,返回的结果经常也只是某些列,不是全部的列。行式数据库在这种情况下的I/O性能会很差,以Oracle为例,Oracle会有一个很大的数据文件,在这个数据文件中,划分了很多block,然后在每个block中放入行,行是一行一行放进去,挤在一起,然后把block塞满,当然也会预留一些空间,用于将来update。这种结构的缺点是:当我们读某个列的时候,比如我们只需要读红色标记的列的时候,不能只读这部分数据,我必须把整个block读取到内存中,然后再把这些列的数据取出来,换句话说,我为了读表中某些列的数据,我必须把整个列的行读完,才可以读到这些列。如果这些列的数据很少,比如1T的数据中只占了100M, 为了读100M数据却要读取1TB的数据到内存中去,则显然是不划算。
3.1 B+索引
Oracle中采用的数据访问技术主要是B数索引:
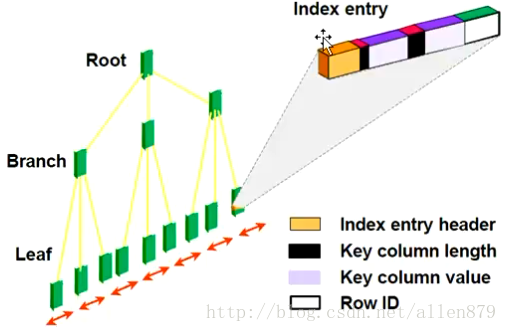
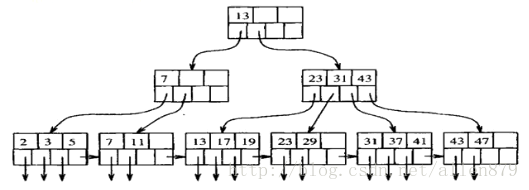
从树的跟节点出发,可以找到叶子节点,其记录了key值对应的那行的位置。
对B树的操作:
B树插入——分裂节点
B数删除——合并节点
4 列式存储
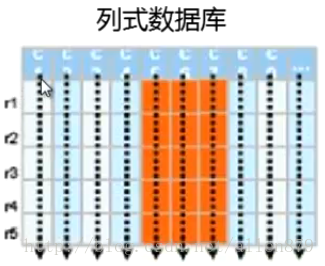
同一个列的数据会挤在一起,比如挤在block里,当我需要读某个列的时候,值需要把相关的文件或块读到内存中去,整个列就会被读出来,这样I/O会少很多。
同一个列的数据的格式比较类似,这样可以做大幅度的压缩。这样节省了存储空间,也节省了I/O,因为数据被压缩了,这样读的数据量随之也少了。
行式数据库适合OLTP,反倒列式数据库不适合OLTP。
4.1 BigTable的LSM(Log Struct Merge)索引
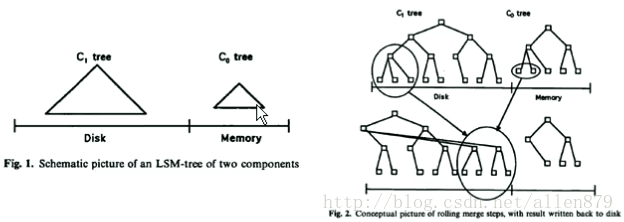
在Hbase中日志即数据,数据就是日志,他们是一体化的。为什么这么说了,因为Hbase的更新时插入一行,删除也是插入一行,然后打上删除标记,则不就是日志吗?
在Hbase中,有Memory Store,还有Store File,其实每个Memory Store和每个Store File就是对每个列族附加上一个B+树(有点像Oracle的索引组织表,数据和索引是一体化的), 也就是图的下面是列族,上面是B+树,当进行数据的查询时,首先会在内存中memory store的B+树中查找,如果找不到,再到Store File中去找。
如果找的行的数据分散在好几个列族中,那怎么把行的数据找全呢?那就需要找好几个B+树,这样效率就比较低了。所以尽量让每次insert的一行的列族都是稀疏的,只在某一个列族上有值,其他列族没有值,

















 1099
1099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









