






本文由南京大学顾荣、李崇杰翻译整理自Alluxio公司技术博客,由Alluxio公司授权CSDN首发(联合),版权归Alluxio公司所有,未经版权所有者同意请勿转载。
1.介绍
Alluxio是世界上第一个以内存为中心的虚拟的分布式存储系统。它为上层计算框架和底层存储系统构建了桥梁,统一了数据访问的方式,使得数据的访问速度能比现有常规方案高出几个数量级。Hadoop Distributed File System(HDFS)是一个用来存储大规模数据的分布式存储系统。HDFS推广了计算向数据迁移的模式,以及计算和存储共同部署的存储架构。
在这篇文章中,我们重点介绍Alluxio可以给与HDFS共同部署的计算集群的两大好处。
- 性能的高可预测性使得SLA(service-level agreement服务级别协议)很容易满足。例:作业运行时间的变化范围从100秒以上缩短至2秒;
- 高达10倍的性能提升。
我们使用Spark2.0来完成计算作业,并对比2种软件栈下作业的执行性能。第一种软件栈是将Spark作业直接运行在HDFS的数据上,另一种是将Spark作业运行在使用HDFS作为底层存储系统的Alluxio的数据上。
2.为什么使用Alluxio
在一个共享的计算集群中,用户在一段时间内经常会在类似的数据集上运行计算任务。例如,许多数据科学家可能会想尝试从前一周收集的数据中挖掘出一些价值。同时,少部分用户会访问不经常使用的数据集,比如利用前一个月收集的数据生成报告。因此,为了优化计算任务的性能,可以将数据存储在内存中。然而,集群的内存总量是有限的,并不能存储所有的数据,这说明需要一个分布式内存管理系统。目前有一些已经实现的系统可供选择。
Alluxio
使用Alluxio,你可以基于数据的特点来显式地管理数据,例如数据的访问频率。这使得系统可以将热点数据显式地保存在内存中,以加速访问这些热点数据的作业。此外,Alluxio提供了稳定的性能,可以保证整个系统提供的服务质量的稳定性。
操作系统缓存/页缓存
操作系统会自动尝试利用机器的内存来加速磁盘I/O。当重复地在同一数据集上运行任务(该数据集能够完全放入内存中),操作系统缓存会比较高效,能提供和Alluxio相当的性能优化效果。然而,当遇到更大的数据集或者访问不同数据集的任务一起运行时,性能将会有很大的变化,平均情况下要比类似于Alluxio的数据感知系统低效很多。
Spark持久化
Spark本身提供临时持久化数据的选项,不需要使用其他外部系统。然而,这些机制被限制在单个SparkContext中,阻碍了多个用户受益于单个用户持久化在内存中的数据。结果是每个SparkContext都消耗系统资源(内存、磁盘)存储各自的数据,这在共享的环境中十分低效,尤其是当大量的内存被不必要的消耗的情况下。
3.Alluxio在共享环境中的优势
为了模拟使用各种不同冷热数据的多租户环境,我们设置了以下实验:
- 在任何时间点,集群上会运行两个作业:月作业和周作业;
- 每一个作业使用一半的CPU和内存资源;
- 新的作业会在前一个同类型作业完成时立即开始;
- 在周作业的数据上先运行一个简单的计算作业,以给操作系统的缓存以及Alluxio内存存储预热。
因为每个作业都是独立的,使用Spark的持久化策略进行数据共享是不适用的。所以,我们主要比较Alluxio内存存储和操作系统缓存机制的效果。
| 作业名 | 描述 |
|---|---|
| 月IO | 运行在前一个月数据上的I/O密集型作业 |
| 月CPU | 运行在前一个月数据上的CPU密集型作业 |
| 周IO | 运行在前一周数据上的IO密集型作业 |
| 周CPU | 运行在前一周数据上的CPU密集型作业 |
该实验在两个不同的软件栈上进行,其中一个使用Alluxio (即Spark + Alluxio + HDFS),另外一个不使用Alluxio (即Spark + HDFS)。所有的实验都运行在公有云虚拟机实例上。总的数据集大小是集群可用内存的三倍。
场景1

在第一个场景中,周作业和月作业都是IO密集型作业。Alluxio对这两种作业的性能提升都很明显。对于周作业,热数据可以确保完全存储在Alluxio内存中,我们可以以内存级速度读取数据,从而持续地加速上层作业。事实上,我们可以发现此时的性能瓶颈为I/O的作业变成了CPU为性能瓶颈。另外,在不使用Alluxio的情况下,作业执行性能的波动范围较大(见图中用红线标出的最小和最大范围),甚至可能比使用Alluxio的情况慢10倍以上。这是由于操作系统页缓存缓存数据的不可预测性导致的。由于数据量大于内存总容量的缘故,使用Alluxio给月作业带来的性能提升不如周作业明显。尽管我们可以通过Spark静态地划分CPU和内存资源(针对Spark task而言,不要与Alluxio内存混淆),但是我们不能细粒度的控制I/O资源,比如磁盘的访问。在不使用Alluxio的情况下,两种作业的性能都被I/O所限制,当数据不在操作系统缓存中时两种作业都会受限于I/O。使用Alluxio的情况下,月作业可以完全利用磁盘带宽,因为周作业从内存直接读取数据而不需要使用磁盘带宽。
场景2
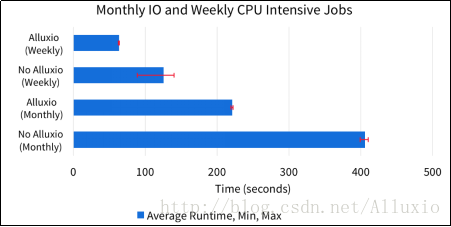
第二个场景中,月作业仍然是I/O密集型的,但是周作业变为CPU密集型的。这种场景下,Alluxio还是同时提高了两种任务的性能。周作业得益于Alluxio带来的内存级速度的I/O,但是性能提升没有之前的IO密集型作业明显。因为,此时的性能主要受机器的CPU吞吐量影响。然而,月作业在使用Alluxio的情况下表现出极大的优势,因为场景1中月作业的性能影响因素在此场景下仍然适用。此外,周作业对操作系统缓存的低效使用导致了更多磁盘资源的竞争,大大降低了月作业的执行性能。
场景3
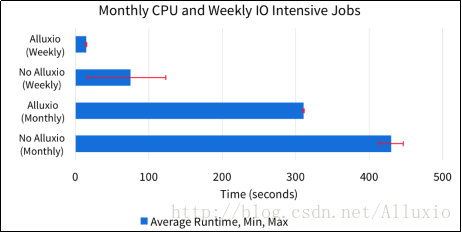
在第三个场景中,月作业是CPU密集型的,周作业是I/O密集型的。Alluxio极大地加速了周作业因为周作业的数据完全在内存中。性能瓶颈为I/O的作业已经被Alluxio加速成性能瓶颈为CPU的作业。我们可以看到CPU密集型的月作业的执行性能也有所提升,因为使用Alluxio避免了周作业与月作业竞争磁盘资源。
场景4

在最后一个场景中,月作业和周作业都是CPU密集型的。在这种情况下,Alluxio带来的性能提升不明显,这是因为两种任务中I/O吞吐量都不是瓶颈。然而,通过持续地管理在内存中的数据,Alluxio使得作业的性能更为稳定。
结论
Alluxio提供了可预测的资源划分和资源使用,使得系统管理员可以对外提供稳定的性能保证。此外,Alluxio可以给共享存储资源的计算集群带来显著的性能收益。使用Alluxio的优势随着集群中需要访问数据的作业数量增多会更加明显。总的来说,当Alluxio使用在计算和存储共同部署的环境中时,可以带来两点关键的性能收益:
- 可预测的稳定性能使得SLA很容易满足;
- 获得最可达10倍的性能提升。















 930
930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









