






本文由南京大学顾荣、李崇杰翻译整理自Alluxio公司技术博客,由Alluxio公司授权CSDN首发(联合),版权归Alluxio公司所有,未经版权所有者同意请勿转载。
1.引言
越来越多的公司和组织(例如百度和伯克利)开始将Alluxio和Spark一起部署从而简化数据管理,提升数据访问性能。Qunar最近将Alluxio部署在他们的生产环境中,从而将Spark streaming作业的平均性能提升了15倍,峰值甚至达到300倍左右。在未使用Alluxio之前,他们发现生产环境中的一些Spark作业会变慢甚至无法完成。而在采用Alluxio后这些作业可以很快地完成。在这篇文章中,我们将介绍如何使用Alluxio帮助Spark变得更高效,介绍多种将Alluxio应用在Spark上的方法。Alluxio可以使Spark执行得更快,使多个Spark job以内存级速度共享相同的数据。具体地,我们将展示如何使用Alluxio高效存储Spark RDD,并在Spark和Alluxio上做一些性能测试。
2. Alluxio 和Spark RDD缓存
Spark用户通常调用Spark RDD cache() API来提高计算性能。cache() API将RDD数据存储在Spark Executor中,下一次调用相同RDD时,RDD数据可以直接从内存载入。然而,RDD数据容量可能会非常大,为数据分配的内存总量会计算得不准确,所以在Spark Executor上存储RDD数据会导致计算所需内存不足。之前的博客提到,去哪儿网在生产环境中遇到了以下问题:Spark job所需的数据经常不在内存中,所以Spark job不能及时完成。另外,如果job崩溃,Spark中的数据将不会被持久化到内存中,下次job恢复,再次访问相同数据,将无法从内存中获取。
该问题的解决方案是将RDD数据存储在Alluxio中,Spark job不需要配置存储数据所需的额外内存,只需配置数据计算所需的内存大小。Alluxio提供了数据存储所需内存,所以RDD数据仍然在内存中。如果Spark job崩溃,数据将仍然存储在Alluxio的内存中,可以被接下来的任务调用。
用户使用Alluxio存储Spark RDD非常简单:将RDD以文件形式存储在Alluxio中。将RDD文件存储有两种方式:saveAsTextFile和saveAsObjectFile。在RDD对应的文件被写入Alluxio后,在Spark中可以使用sc.textFile或者sc.objectFile (从内存中)读取。为了分析理解使用Alluxio存储RDD和使用Spark内置缓存存储RDD在性能上差异,我们进行了如下的一些实验。
实验相关设置如下:
- 硬件配置:单个Worker安装在一个r3.2 Amazon EC2节点上,节点配置:61 GB内存 + 8核CPU。
- 软件版本:Spark2.0.0和Alluxio1.2.0,参数均为缺省配置。
- 运行方式:以standalone模式运行Spark和Alluxio。
在本次实验中,我们使用Spark内置的不同缓存级别存储RDD对比测试使用Alluxio存储RDD,然后收集分析性能测试结果。同时通过改变RDD的大小来展示存储的RDD的规模对性能的影响。
3. 存储RDD
Spark RDD可以使用persist() API存储到Spark缓存中。persist()可以缓存RDD数据到不同的存储媒介。
本次实验使用了以下Spark缓存存储级别(StorageLevel):
- MEMORY_ONLY:在Spark JVM内存中存储Java对象。
- MEMORY_ONLY_SER:在Spark JVM内存中存储序列化后的Java对象。
- DISK_ONLY:将数据存储在本地磁盘。
下面是一段应用persist()API存储RDD的代码示例。
Rdd.persist(MEMORY_ONLY)
Rdd.count()除了persist()API,另一种存储RDD的方式是将RDD写入Alluxio中。常见的API是:
- saveAsTextFile:将RDD以文本文件的形式存储。文件里的一行数据存储为一个元素。
- saveAsObjectFile:将RDD每一个元素通过java序列化的方式存储为文件。
下面是一段将RDD以文件方式存储在Alluxio中的代码示例:
rdd.saveAsTextFile(alluxioPath)
Rdd = sc.textFile(alluxioPath)
Rdd.count()4. 查询存储在Alluxio上的RDDs
RDD被保存后(无论存储在Spark内存还是Alluxio中),应用可以读取RDD以进行后续的计算任务。本次实验利用缓存RDD或者以文件形式存储的RDD运行count()函数,并分别统计运行时间。下图展示了在不同存储方式下操作的完成时间。
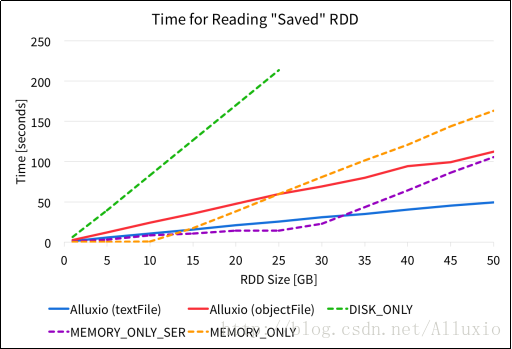
从上图可以看出,读取存储在alluxio中的RDD数据具有比较稳定的执行性能。对于从Spark缓存中读取持久化数据,在数据集规模较小时执行性能具有一定优势,但是随着数据集规模的增长,性能急剧下降。例如,Spark程序在配了61GB内存的节点上调用persist(MEMORY_ONLY)API,当数据集超过10GB时,Spark内存无法全部存放job所需数据,执行时间会下降。
另一方面,相比使用Spark内置缓存,使用Alluxio存储RDD并执行count()函数,其性能在小规模数据上略有劣势。然而,随着数据规模的增长,从Alluxio中读取文件性能更好,因为这种方式耗时几乎始终随着数据规模线性增长。因此,对于一个给定内存大小的节点,Alluxio可以使应用以读取内存的速率处理更多数据。
5. 使用Alluxio共享存储的RDD
使用Alluxio存储RDD的另一大优势是可以在不同Spark应用或作业之间共享存储在Alluxio中的数据。当一个DataFrame文件被写入Alluxio后,它可以被不同的作业、SparkContext、甚至不同的计算框架共享。因此,如果一个存储在Alluxio中的RDD被多个应用频繁地访问,那么所有的应用均可以从Alluxio内存中直接读取数据,并不需要重新计算或者从另外的底层外部数据源中读取数据。
为了验证采用Alluxio共享内存的优势,我们应用相同的配置运行一个简单实验。应用50GB大小的数据集,我们在RDD上执行不同Spark job,并且记录count()操作的耗时。没有使用Alluxio时,Spark应用需要每次都从数据源读取数据(在本次实验中是一个本地SSD)。在使用Alluxio时,数据可以直接从Alluxio内存中读取。下图展示了程序在这两种情况下,运行count()函数完成时间性能对比。
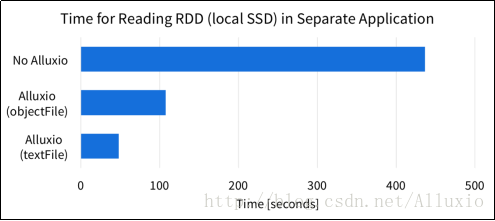
结果显示了Spark程序如果不使用Alluxio,必须从数据源处重新读取RDD,本例中是本地SSD。然而,将Alluxio和Spark一起使用时,数据已经存储在Alluxio内存中,所以Spark可以快速地读取RDD。当Spark从Alluxio中读取RDD时,读取速度可以提升4倍。如果RDD来自访问起来更慢或不稳定的数据源,Alluxio的优势就更加明显了。下图显示了RDD位于某公有云存储时程序的执行时间。
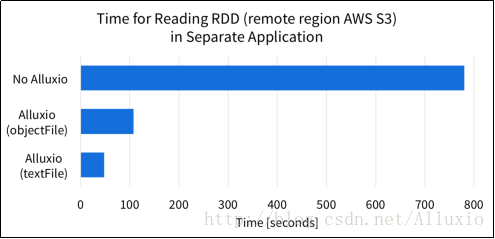
在这种情况下,RDD数据集远离计算程序,读取数据花费更多时间,当应用Alluxio时,数据仍然在Alluxio内存中,所以计算可以快速完成。在这种情况下,应用Alluxio可以加速16倍。
这个实验证明了通过Alluxio共享RDD这一方式,可以在多个Spark应用读取相同数据时提升性能。
6. 总结
Alluxio可以在多个方面帮助Spark变得更高效。这篇文章介绍了如何使用Alluxio存储Spark RDD,并且实验验证了采用Alluxio带来的优势:
- Alluxio可将RDD以文件形式存储,使Spark应用以可预测的高效的方读取数据。
- Alluxio可以将大规模数据集保存在内存中,提高Spark应用的执行速度。
- Alluxio可以使多个Spark应用共享内存数据集,从而提高整个集群性能。
















 775
775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









