







 介绍了Hadoop Ozone作为新一代对象存储系统的设计理念和技术细节,包括其如何组织数据、元数据管理和对象寻址机制等内容。
介绍了Hadoop Ozone作为新一代对象存储系统的设计理念和技术细节,包括其如何组织数据、元数据管理和对象寻址机制等内容。
前言
现在做云存储的公司很多,举2个比较典型的AWS的S3和阿里云.他们都提供了一个叫做对象存储的服务,就是目标数据是从Object中进行读写的,然后可以通过key来获取对应的Object,就是所谓的key-object的存储.这样的好处就在于用户使用起来很方便的,不需要走冗杂的操作流程.但是本文所要阐述的则是HDFS中的对象存储,对于这样的需求,Hadoop作为一套完善的分布式系统,当然也要与时俱进,在HDFS-7240中进行了实现,目前此功能真在开发中,名叫Ozone,内部有很多的概念与业界的都是类似的,例如Bucket,Object等.下面是本人对于Ozone设计文档的一个译文,可能会有翻译不到位的地方,附上原文链接:Ozone-architecture-v1.pdf
目录
介绍
1.1 基本要求
1.2 大小要求高层次设计
2.1 与HDFS共享Datanode Storage存储
2.2 Storage Container存储容器
2.3 Storage Container Identifier存储容器标志符
2.4 Storage Container存储容器服务的调用
2.5 Datanode中的Ozone Handler
2.6 Storage Container Manager存储容器管理器具体实现
3.1 对象键值到存储容器的映射
3.2 范围分区Vs哈希分区
3.3 bucket到存储容器的映射
3.4 Storage Container存储容器的要求
3.5 Storage Container存储容器实现要点
3.6 Pipeline数据一致性未来工作
4.1 Ozone API
4.2 集群层级API
4.3 Storage Volumes层级API
4.4 Bucket层级API
4.5 Object层级API引用
介绍
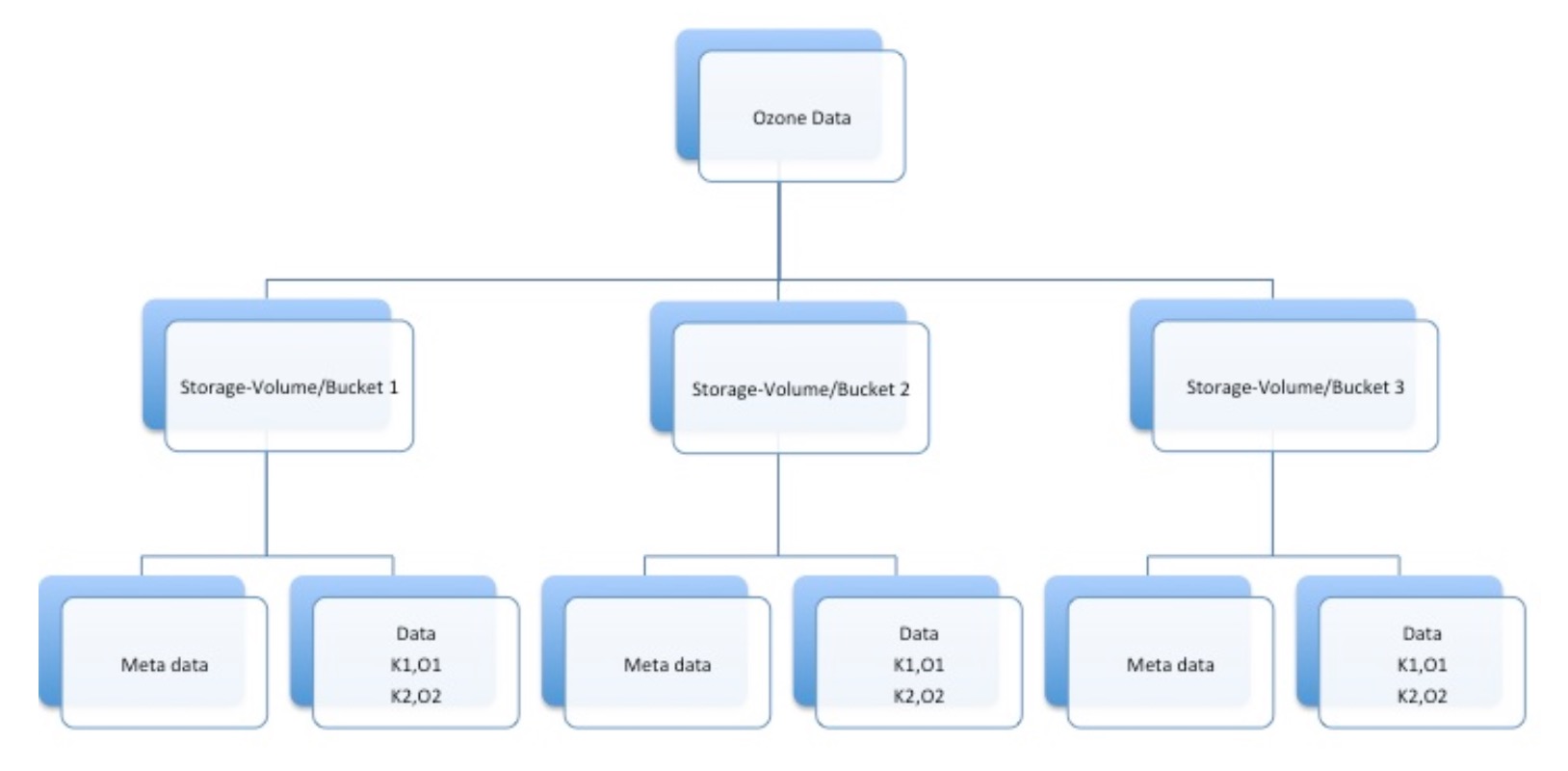
Ozone提供了一个key-object键值-对象存储的服务,类似AWS的S3服务. Key和Object对象是随机的字节数组.单个key的大小期望是小于1k,但是values对象可以从小到几百字节大到几百兆.键值/对象被组织进了bucket的概念中.一个bucket拥有唯一的key集合.Bucket存在于Storage-Volume中,并且在Storage-Volume中拥有唯一的名字.一个storage volume拥有全局唯一的名字.更近一步的说,storage volume对buckets和存储的数据有配额上的限制.在私有云中,它可以被用来创建给用户(例如home目录),工程项目,或者租有者.管理员可以分配一定配额限制的私有storage volume给个体用户或者公有的共享storage volume.在公有云中,多storage volume可以以独立的配额分配在每个云中.
一个bucket被2部分名字的组合唯一标识: storage-volumeName/bucketName.一个对象的名字被storage-volumeName/bucketName/objectKey 3部分所标识.
我们的模式类似于Azure Blob Storage(WASB).他们的bucket在每个帐户中是唯一的.但是,我们用storage volume来取代了这个帐户概念.因此相比之下,S3的bucket在所有帐号中保持唯一.
数据的组织结构可以以下面的图形进行展示.
基本要求
Ozone中基本的操作如下(API方法在文档尾部将会给出):
- 管理员创建Storage Volume.
- 创建/删除 buckets.每个bucket拥有一个独立的URL.Buckets不能被重命名.只有storage volume的所属者或所属组才能创建/删除volume中的bucket.
- 在一个storage volume中列出buckets列表.
- 根据给定的key在bucket中创建/删除object对象.对象的数据或值可以流式的传输到Ozone服务中.当对象被写满的时候将只会允许读操作.同时不保证对象的局部写.
- 列举出bucket的内容
- 创建/更新/删除 buckets的ACL访问控制列表
大小要求
本节列举了少部分的限制值来具体化一些要求.下面是目标版本1的一些指标:
- Storage Volume名字: 3~64字节
- Bucket 名称: 3~64字节
- Key大小: 1KB
- Object大小: 5G
- 系统总buckets数量: 1000w
- 每个bucket中对象数量: 100w
- 每个storage volume中的bucket数: 1000
Ozone元数据包括以下内容:
- Storage Volume层级元数据
- Storage volume所属者
- Storage Volume名称
- Bucket层级元数据
- Bucket所属者: 拥有此bucket中数据的所属用户.
- Bucket ACL访问控制信息
- 全局唯一的Bucket名称
- Bucket Id: 与bucket相关的系统产生的数字型的标识
高层级设计
与HDFS共享Datanode数据存储
DataNode同时为HDFS和Ozone存储数据.Ozone的数据用的是独立的blockPool并拥有独立的blockPool Id.也就是说可以同时存在多种volume命名空间,每个volume有属于自己的block pool.同样的可以同时存在多个独立的Ozone命名空间在所属的block pool下.一个DN可以同时存储多个HDFS和Ozone的block pool.此关系结构如下图所示:
Storage Container容器
一个storage container从概念上来说,指的是用来存储Ozone数据(就是bucket中的数据)和Ozone元数据的一个存储单元.Storage container与HDFS的block一样,共同存储于DataNode上.但是与HDFS不同的一点,Ozone没有一个类似于NameNode的中心节点,相反地,他是一个分离的元数据的存储.这些元数据分布式的存在于各个storage container中.每个storage container以whole的形式存在(类似于HDFS中的block).我们对container副本的成功操作保证了强一致性.Storage container的最大值的大小取决于他的副本复制能力以及从节点故障中恢复的能力.最大值的大小是可配的,但是他至少要大于一个简单对象所允许的最大值.
一个bucket可以拥有百万数量级的对象并且在存储的大小级别上可以达到T级别,这远远大于一个storage container.因此一个bucket会被分为很多partion分区,每片分区会存储在一个container中.(一个storage container可以包含最大值数量的的分区,然而对象只能来自一个bucket.)在我们的初始设计实现中,一个object对象是完全存在于一个单一的container中,这么做后面可能会轻松一些.
Storage container是靠DataNode来实现的(用户可以通过配置来禁用此功能如果用户只需要使用HDFS的block功能).本节定义了storage container的一些语义和要求.Storage container需要存储以下多种类型的数据,每类数据有略微不同的语义:
Bucket元数据
- 个体单元的数据是非常小的-kb级别.每个storage container可以保存上百万bucket的元数据.
- 这点要求能够更新,因为一个bucket的ACL是能够被更新的,并且要能保证操作的原子性.
- 满足基本的Get/Put的API设计已经足够.
- 在container中能执行列表操作以便展示所有的bucket.
Bucket数据
- Storage container需要能够存储小到几百kb大到上百mb的对象数据.
- 对象需要通过对象的key进行访问(所以container存储数据也必须包含存储对象的索引).
- 必须能支持个体对象读写的流式API.
- 数据中的对象不支持追加写以及原地更新.
在后面的小节,我们将阐述DataNode如何实现storage container来达到以上的要求.
Storage Container标识符
每个storage container都被独立的storage container标识符所独立标识.它是一个逻辑上的独立标识(类似于HDFS中的blockId)并且不包含真正意义上container的网络位置.
对象的key会映射到storage container标识符.这个标识符会传入storage container manager管理器去定位包含目标对象container所在的DataNode.类似的,bucket的名称也会映射到storage container标识符,这个container保存有bucket的元数据.在后面的小节中,我们会具体提到这个映射关系是如何实现的.Storage container标识符是64位的,类似于hdfs中的block id.在未来,我们将把它扩展到128位.但是那将会是一个大的改变,因为我们想尽可能的复用hdfs的block管理器相关的代码.
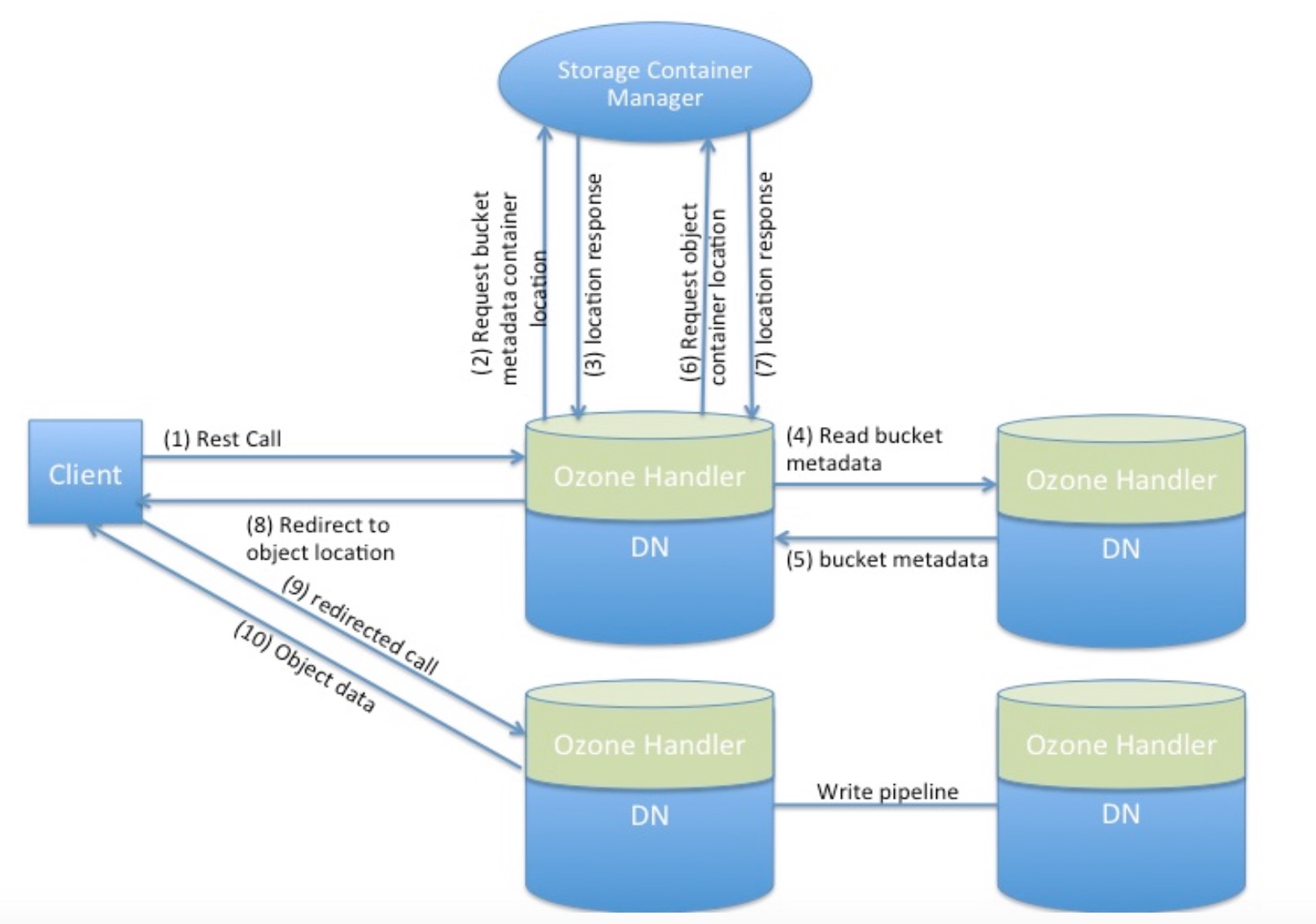
Storage Container Service中的过程调用
下面的图形展示了Ozone中的典型过程调用,其中主要包含了Storage Container Service服务和Ozone Handler处理器:
DataNode中的Ozone Handler
Ozone handler是Ozone中的模块组件,被DataNode所持有并对外提供Ozone服务.Handler包含了一个http server并实现了Ozone REST方式API.Ozone Handler与storage container manager管理器交互来查询container的位置.与DataNode中的storage container交互实现不同的操作.这个功能组件可以被禁用如果用户只想要使用HDFS而不需要Ozone功能.
Storage Container Manager管理器
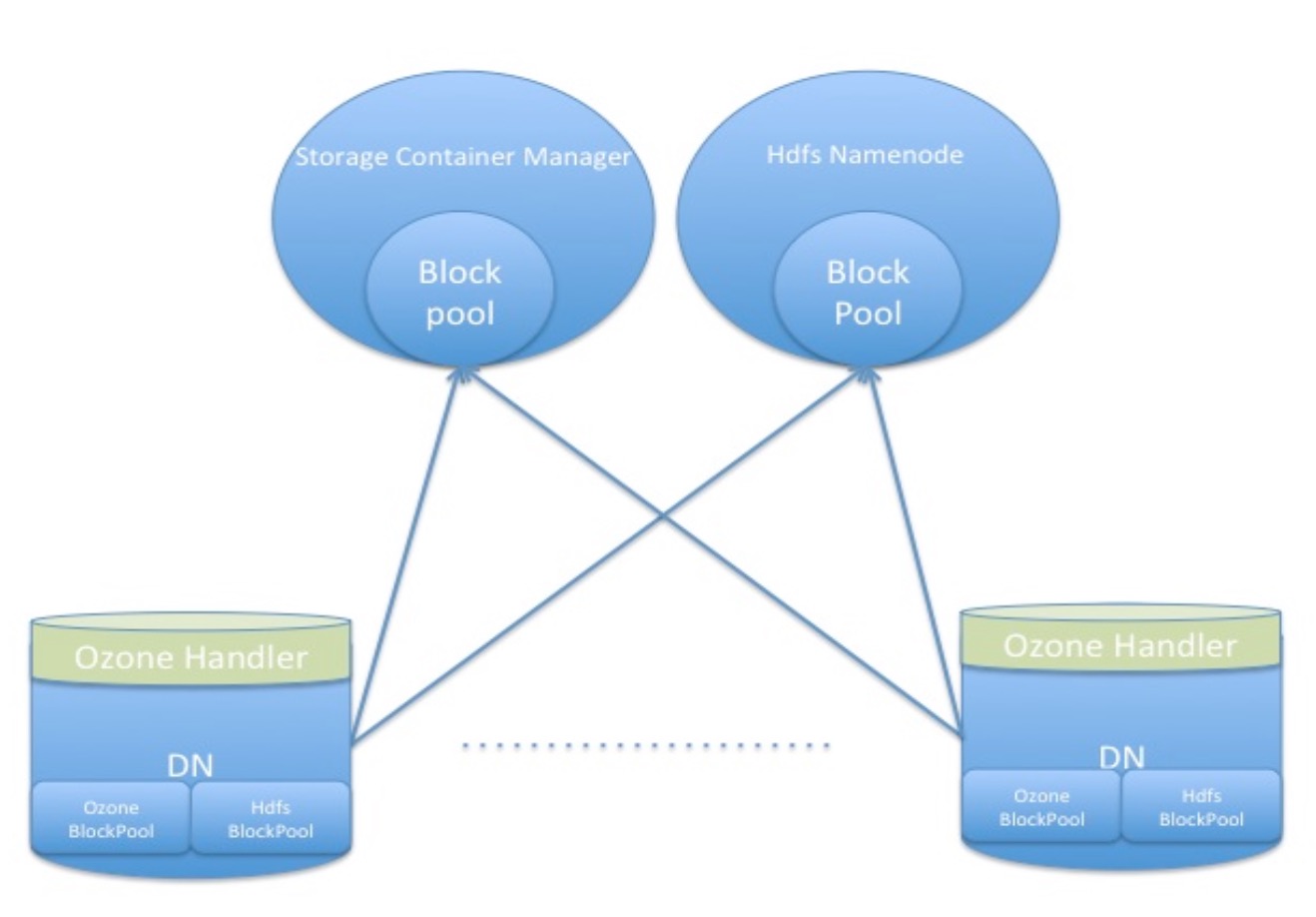
Storage container manager管理器非常类似于HDFS中block manager中的管理功能.Storage container manager管理器从各个DataNode中收集心跳,处理storage container的报告并跟踪每个storage container的位置.他包含了一个storage container映射图,以此提供了前缀匹配的方式去查询storage container.之前提到过DN能够同时存储HDFS和Ozone的数据.Ozone的数据所属的是分离的block pool并且用的是Storage container manager管理器提供的分离的blockPool Id.图形展示效果如下.我们计划尽可能的复用NameNode已有的block管理部分的代码实现来实现container的管理.我们同样可以复用DataNode 中block pool service服务的实现代码.
具体实现
映射object-key到storage container
在我们的设计中,我们计划使用哈希分区的模式来映射key到他所存储的storage container.Key的值是被哈希计算的,同时会带上bucketId的前缀.结果值通过前缀匹配可以映射到storage container.当container逐渐变大,我们会对此进行分割,并用扩展哈希算法重新映射key到对应container的映射关系.Storage container manager管理器会存储这些映射关系到前缀树中以此实现高效的前缀匹配.每个bucket都有属于自己的前缀树.
范围分区 vs 哈希分区
在数据库和对象存储中,范围分区是另外一项比较受欢迎的用来对key进行分区的技术.以下是2个技术的简短的比较.我们偏向于使用哈希分区的方法,因为它相比较能更简单的去实现并且能满足我们的需求.
- 范围分区模式需要范围索引.范围索引同样非常巨大并且需要分布式的存储.这复杂化了分割多个分区的操作,因为他额外需要索引的更新.
- 范围分区在搜索过程中多引进了一种额外的跳跃,当第一次范围索引需要去读.
- 范围分区同样有热点问题.相似名字的key会造成相同范围内的大并发量的访问.
- 然而,范围分区提供了有序访问以及有序列表展示的优势.但是我们认为对于一个对象存储而言,一个有序的访问并不是一个重要的要求.列表有序的展示可以在后面的阶段内用二级索引的方式来实现.我们同样相信对于目前的设计而言是足够灵活的,如果我们在未来想要对此添加范围索引的话.
映射bucket到storage container
Bucket的元数据同样存储在storage container中.Bucket的名字是被用来作为key做哈希计算的.多个bucket的元数据可以存在于storage container中.我们在所有与storage container关联的bucket中设计了一个特殊的bucketId,bucketId前缀中会带上container Id.
Storage Container要求
Storage Container存储在各个DataNode上.对于Storage Container我们有以下的要求:
- Storage Container能够可靠地被复制.
- Storage Container保持严格的一致性.
- Storage Container对于内部存储的对象能提供高效的键值对的查询方式.
- Storage Container必须能够以流式的方式对object进行读写操作.
- Storage Container必须能够支持get/put接口,来存储和更新bucket元数据.
- Storage Container对于内部存储的bucket必须能提供一个原子的更新操作.
- Storage Container能够进行分裂当他们达到一定大小限制的时候.
Storage Container的实现要点
- 我们倾向于尽可能的复用HDFS现有的block pool管理方面的功能代码.因此我们会将StorageContainer作为Block类的扩展类.一个hdfs block由一个标识符,生成时间记录和大小组成.这3个属性同样可以应用到storage container中.
- 为了保证一致性和持久性,storage container实现了少量的原子性和持久化的操作,比如事务.Container对这些操作提供了可靠的保证.在第一阶段中,我们实现以下事务操作:
- Commit: 这个操作促进了对象从被写到最后的确认结束.一旦这个操作成功,这个container就会保证对象是可读的.
- Put: 这个操作适用于小规模的写操作,例如元数据的写动作.
- Delete: 删除对象.
- Container中的每个事务会有一个事务ID,并且必须被持久化.
- 我们计划为storage container实现一个新的data-pipeline,因为他要求一个不同类型的更新和恢复语义操作.在下一小节中我们会给出data-pipeline的设计概述.
- 我们正在考虑利用leveldbjni来作为storage container的原型设计,leveldbjni正好能满足我们storgae container键值对存储的需求.
Data Pipeline一致性
Data-Pipeline管道链流式复制副本数据到container中.Container的副本也有产生记录类似于HDFS的block.每个pipeline副本的标记记录在pipeline创建的时候会被更新,所以任何旧的container会被撤销.HDFS在block恢复的时候额外使用了block length副本长度来判断副本是否已经更新到最新.类似地, storage container用了事务ID来判断container副本是最新的.更多的pipeline设计细节将会上传到对应hdfs jira上.
未来工作
我们并没有在文档中仔细阐述下述的要求,但是我们将会在后面阶段的工作中实现这些功能:
- High availability: 高可用性,Storage container manager管理器需要是高可用的服务.一个解决方案是利用HDFS Journal的QJM机制实现Active/Standby的方式.另外一种方式做成所有Active的服务配上Paxos环的方式.我们会在第二阶段的工作中对这个问题进行社区内的讨论.
- Security: 安全,我们可以利用HDFS的kerberos认证机制
- Cross cool replication: 跨类型副本拷贝,我们将会使用一种对HDFS和Ozone都有利的方式去实现这个功能.
Ozone API
Cluster层级APIs
- PUT StorageVolumes
- API - PUT /admin/volume/{StorageVolume}
- 创建一个storage volume
- 只有管理员才允许调用这个操作
- API - PUT /admin/volume/{StorageVolume}
- HEAD StorageVolume
- API - HEAD /admin/volume/{StorageVolume}
- 检测Storage Volume是否存在
- 只有管理员才能调用这个操作
- API - HEAD /admin/volume/{StorageVolume}
- GET
- 列出集群中所有的Storage Volume.
- DELETE Storage Volumes
- API - DELETE /amin/volume/{StorageVolume}
- 删除一个volume如果他是空的
- API - DELETE /amin/volume/{StorageVolume}
Storage Volume层级APIs
- GET Buckets
- API - GET /
- 利用用户的认证信息登录
- 返回请求发送者所拥有的buckets列表
- Get User Buckets
- API - GET /admin/user/userid
- 利用用户认证信息进行登录, 如果他/她有权限阅读其他用户的信息,返回那个用户所独有的buckets列表信息.
- API - GET /admin/user/userid
Bucket层级API
- LIST objects in a bucket
- API - GET/{bucketName}
- 返回buckets中最多1000个数量的对象key
- API - GET/{bucketName}
- PUT bucket
- API - PUT/{bucketName}
- 为请求发送者创建bucket
- GET/PUT Bucket ACL
- API - /{Bucket}?acl
- 允许用户获取/设置bucket的ACL
- API - PUT/{bucketName}
- HEAD bucket
- API - HEAD/{bucketName}
- 检查bucket是否存在,前提是请求发送者有权限访问此bucket
- DELETE bucket
- API - DELETE/{bucketName}
- 删除bucket如果此bucket为空的话
- API - DELETE/{bucketName}
Object层级APIs
- GET object
- API - GET/{bucketName}/{key}
- 返回给定key所代表的对象值,如果这个值存在
- 在第一阶段暂不支持ACL,因此只有所属用户才能读写自身的bucket.
- API - GET/{bucketName}/{key}
- PUT object
- API - PUT/{bucketName}/{key}
- 在bucket中创建一个对象
- 在第一阶段暂不支持ACL,因此只有所属用户才能读写自身的bucket.
- 不支持局部的上传,只有对象全部上传成功了才被认为是一次成功的操作.
- API - PUT/{bucketName}/{key}
- HEAD object
- API - HEAD/{bucketName}/{key}
- 检测对象是否存在
- 在第一阶段只有bucket的所属用户才能调用此操作
- API - HEAD/{bucketName}/{key}
- DELETE object
- API - DELETE/{bucketName}/{key}
- 删除对象
- API - DELETE/{bucketName}/{key}
引用
1.Extendible Hashing(扩展哈希算法)-
http://en.wikipedia.org/wiki/Extendible_hashing
2.leveldbjni - A Java Native Interface(Java本地接口) to
LevelDB. https://github.com/fusesource/leveldbjn

















 7550
7550





 到【灌水乐园】发言
到【灌水乐园】发言







