 HDFS Federation:原理、优势与配置
HDFS Federation:原理、优势与配置





 本文详细介绍了HDFS Federation的原理、优势及配置方法。通过Federation,可以解决NameNode的单点压力,实现命名空间的扩展,提升性能,并实现资源隔离。配置上,只需新增NameNode,格式化并共享DataNode,即可创建多命名空间的HDFS集群。此外,还讨论了Federation在资源管理和客户端访问上的考量。
本文详细介绍了HDFS Federation的原理、优势及配置方法。通过Federation,可以解决NameNode的单点压力,实现命名空间的扩展,提升性能,并实现资源隔离。配置上,只需新增NameNode,格式化并共享DataNode,即可创建多命名空间的HDFS集群。此外,还讨论了Federation在资源管理和客户端访问上的考量。
前言
在上一篇文章HDFS自定义小文件分析功能中,提到了NameNod内存空间使用过高的问题,紧接着提到了其中一个解决方案,就是HDFS Federation.说来也是挺奇怪的,HDFS的Federation机制其实在Hadoop很早的版本中就就有了,可是从日常使用上来看,了解和真正使用这个功能的人并不多.原因可能在于目前对于绝大多数用户的使用场景,一个NameNode或一对HA的NameNode方式足够应对使用需求了吧.本文将要讲述的主题就是HDFS Federation.这里面还是有很多有用的东西可以讲的.
背景知识
估计有一部分同学可能之前没有听过HDFS Federation的概念,所以接下来我要做一些铺垫的介绍了.先来讲讲Federation这个词,这个单词的中文意思为联邦,联盟.难道HDFS Federation的大致意思是HDFS联盟,多个HDFS集群的意思?其实这里的HDFS Federation更应该是NameNode Federation,这样可能很多人就会看明白了,没错,就是多个NameNode的意思.多个NameNode的情况意味着有多个namespace(命名空间).既然说到了NameNode的命名空间的概念,这里就不得不提现有的HDFS数据管理架构,如下图所示:
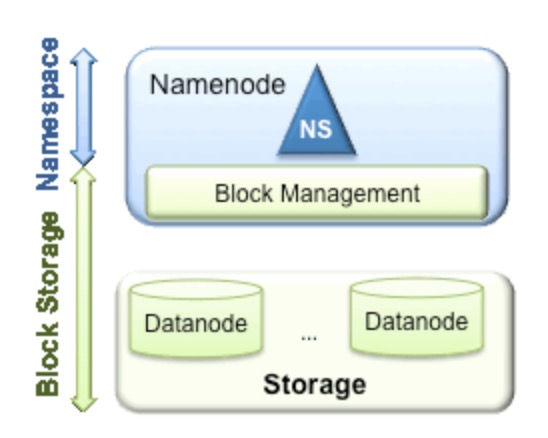
从上图中,我们可以很明显地看出数据管理,数据存储2层分层的结构.也就是说,所有关于存储数据的信息和管理是放在NameNode这边,而真实数据的存储则是在各个DataNode下.而这些隶属于同一个NameNode所管理的数据都是在同一个命名空间下的.而一个namespace对应一个block pool.Block Pool是同一个namespace下的block的集合.当然这是我们最常见的单个namespace的情况,也就是一个NameNode管理集群中所有元数据信息的时候.如果我们遇到了前言部分提到的NameNode内存使用过高的问题,这时候怎么办?元数据空间依然还是在不断增大,一味调高NameNode的jvm大小绝对不是一个持久的办法.这时候就诞生了HDFS Federation的机制.
HDFS Federation的原理结构
HDFS Federation意味着在集群中将会有多个namenode/namespace,这样的方式有什么好处呢?
多namespace的方式可以直接减轻单一NameNode的压力.
一个典型的例子就是上面提到的NameNode内存过高问题,我们完全可以将上面部分大的文件目录移到另外一个NameNode上做管理.更重要的一点在于,这些NameNode是共享集群中所有的DataNode的,它们还是在同一个集群内的.HDFS Federation原理结构图如下:
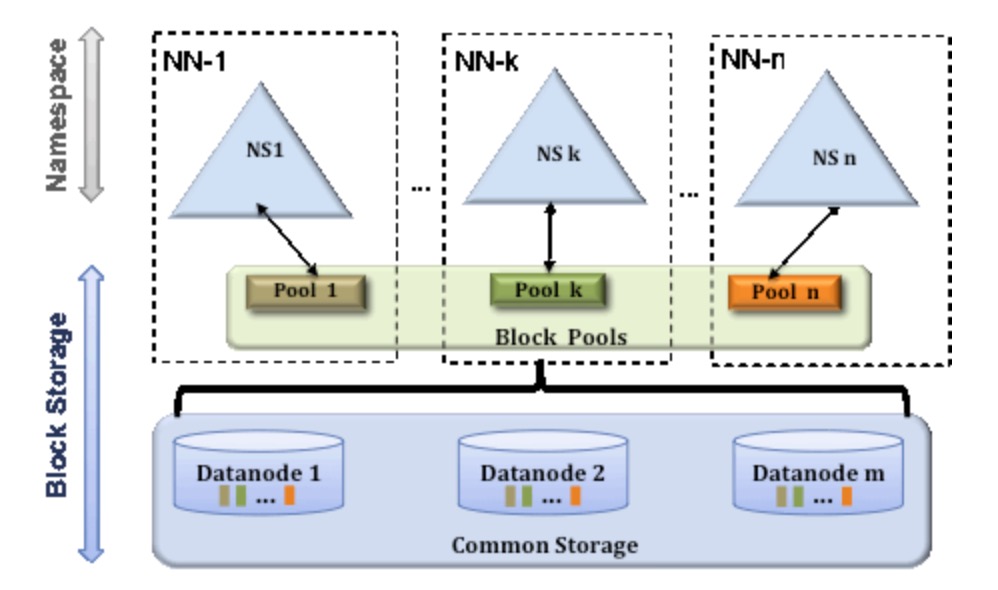
我们可以拿这种图与上一小节的图做对比,我们可以得出这样一个结论:
HDFS Federation是解决NameNode单点问题的水平横向扩展方案.
这时候在DataNode上就不仅仅存储一个Block Pool下的数据了,而是多个(大家可以在DataNode的datadir所在目录里面查看BP-xx.xx.xx.xx打头的目录).
在HDFS Federation的情况下,只有元数据的管理与存放被分隔开了,但真实数据的存储还是共用的,这与viewFs还是不一样的.之前看别的文章在讲述HDFS Federation的时候直接拿viewFs来讲,个人觉得二者还是有些许的不同的,用一句话
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章






















 到【灌水乐园】发言
到【灌水乐园】发言







