







从这篇博客开始,慢慢一起学习Map集合
什么是Map?
Map和List不同,
在List中,我们记得主要是线性表,List中又可以细分为基于数组实现(ArrayList,Vector, ..),基于链表实现(LinkedList, …)。并且主要是List只有value,即只有一个值。
而在Map中 ,存储的是一个键值对 组合,即key-value。基本操作都是作用于这个组合。
看Map接口的实现:
public interface Map<K,V>而对于构造Map的方式又有多种,本文主要介绍TreeMap,基于红黑树 的Map实现方式。
TreeMap的基本特征
先看定义:
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable1):有序性
NavigableMap是一个扩展SortedMap的集合,因而TreeMap也是有序的,注意这里的有序性和ArrayList里面的顺序性不同
好比10个小朋友站队,
在ArrayList里面,依次进入,我不能保证在里面是按照高矮排序的,但是一定是顺序的,也就是如果张三在李四前面进,
王五在李四后面进,那么最终队列中,李四前后就一定是张三和王五(当然方位关系,也可为王五和张三)。
而在TreeMap里面,由于结构不同,所以就不是线性表这样一条线,但是通过iterator遍历的时候(通过身高确定的comparator),就能够保证最终按照身高高矮顺序输出。
所以二者不同。
2):元素值空值问题
由上特点分析,TreeMap是有序的,而在里面其实是通过Comparator来比较的,这样才会有序嘛,并且在创建一个TreeMap的时候,可以传入Comparator辅助排序,或者用默认的Comparator进行判定大小(强行用父类compareTo进行比较的)。这样的意图是什么呢,也就是你可以将键设为空值(null),前提是你要自己传一个Comparator,考虑到null的情况。当然值也是能为null的,正常存正常输出。
先看获取值的源码:
final Entry<K,V> getEntry(Object key) {
// Offload comparator-based version for sake of performance
if (comparator != null)
return getEntryUsingComparator(key);
//默认情况下,不允许key为null
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
Entry<K,V> p = root;
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
}
//当用了自己的Comparator的时候
final Entry<K,V> getEntryUsingComparator(Object key) {
@SuppressWarnings("unchecked")
K k = (K) key;
Comparator<? super K> cpr = comparator;
if (cpr != null) {
Entry<K,V> p = root;
while (p != null) {
int cmp = cpr.compare(k, p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
}
return null;
}3):不允许重复
当插入一个新值的时候,会沿着二叉树一直向下找,知道找到合适位置,如果找到key相等的话,就会产生替换操作,所以是不允许重复的,具体原理在下文将put操作会分析。
但是也有一个特例,类似于上面分析可以加null作为键,TreeMap里面都是用comparator来实现比较的,所以当你传入的元素在comparable里面懂了手脚,比如相等也返回1的话,就可以加入重复值了。
4):操作的时间复杂度
在jdk描述中,指出在get,put,remove等操作方法中,都具有log(n)的时间复杂度,即查找、插入和删除在平均和最坏情况下都是O(log n)。在下文具体分析中可知悉。
5):非线程安全
TreeMap非线程安全,使用时注意同步或者使用包装类进行同步。
synchronizedSortedMap Collections.synchronizedSortedMapTreeMap的原理
TreeMap是基于二叉树实现的,这里不了解二叉树的可以看看网上的一些文章,而在二叉树里面又分为多种类型的树,有一种树叫做AVL,这里可以了解下:AVL 。而在AVL树的具体实现中,又有一种典型的实现方法,这就是红黑树了红黑树 。
而在Java中TreeMap,就是基于这种红黑树实现的。
或许说道这里,还是有很多读者会很蒙,不太理解TreeMap是啥,下面介绍下红黑树的基本特征,最后会给出简单易懂的TreeMap原理。
红黑树
二叉查找树
由于红黑树本质上就是一棵二叉查找树,所以在了解红黑树之前,咱们先来看下二叉查找树。
二叉查找树(Binary Search Tree),也称有序二叉树(ordered binary tree),排序二叉树(sorted binary tree),是指一棵空树或者具有下列性质的二叉树:
-若任意结点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
-若任意结点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
-任意结点的左、右子树也分别为二叉查找树。
-没有键值相等的结点(no duplicate nodes)。
因为,一棵由n个结点,随机构造的二叉查找树的高度为lgn,所以顺理成章,一般操作的执行时间为O(lgn)。
但二叉树若退化成了一棵具有n个结点的线性链后,则此些操作最坏情况运行时间为O(n),也就是编程斜着的一根。后面我们会看到一种基于二叉查找树-红黑树,它通过一些性质使得树相对平衡,使得最终查找、插入、删除的时间复杂度最坏情况下依然为O(lgn)。
红黑树
而红黑树,也是一棵二叉树。
但它是如何保证一棵n个结点的红黑树的高度始终保持在h = logn的呢?这就引出了红黑树的5条性质:
1)每个结点要么是红的,要么是黑的。
2)根结点是黑的。
3)每个叶结点(叶结点即指树尾端NIL指针或NULL结点)是黑的。
4)如果一个结点是红的,那么它的俩个儿子都是黑的。
5)对于任一结点而言,其到叶结点树尾端NIL指针的每一条路径都包含相同数目的黑结点。
也正是这5条性质保证了这棵红黑树高度为log(n),所以保证了查找、插入、删除的时间复杂度最坏为O(log n)。
什么时候会用到这5条新值呢?就是当你对树的结构进行了改变(插入,删除)时,就需要调整来保证这5条性质所以改变
后还是一棵红黑树。
先看一张图了解下:(就是平衡二叉树,加上红黑颜色节点限制)
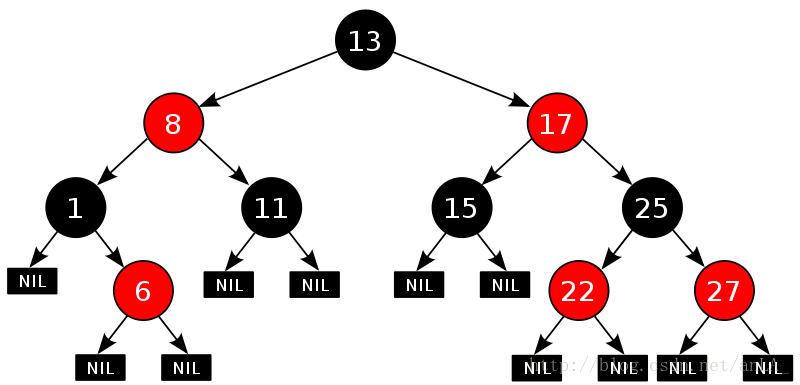
树的旋转知识
主要包括左旋和右旋,在平衡二叉树中,用于调整二叉树的最大高度差不超过1。
左旋:
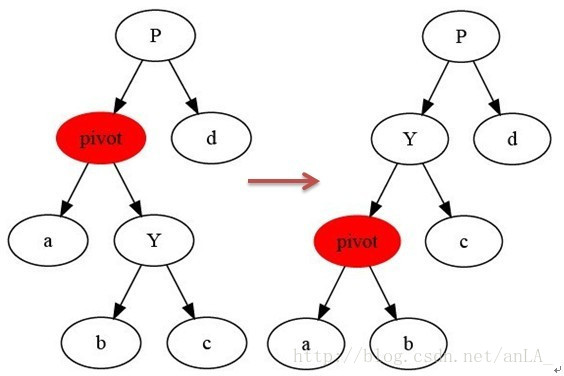
右旋:
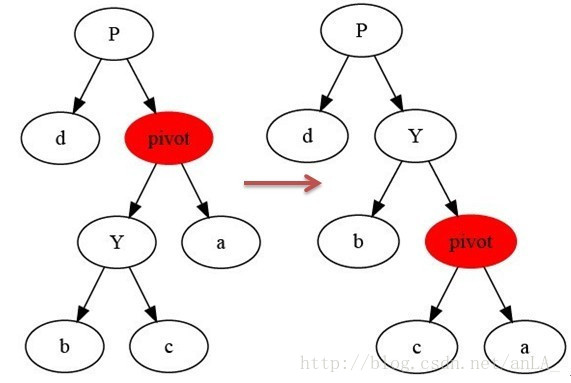
插入及调整
接下来就是红黑树的插入过程,
首先是要确定新加入的节点适合放到哪个位置,步骤就是从根节点向下遍历,左小右大。
当找到之后,就将值插入,但是插入过程后,树的结构和相关性质就会发生变化导致不再符合红黑树的特征,此时就需要调整
经过调整步骤后,树的结构就再一次符合了红黑树的特征了,并且值也插进去了。
这里就不再详细讲红黑树插入算法,本文主要集中篇幅将Java中TreeMap,当然理解了红黑树后,也就可以轻松理解TreeMap了,深入了解可访问
julycoding
删除及调整
和插入步骤一样,不细讲
先找到节点,再删除节点,调整。
总括
红黑树就是一棵平衡二叉树,它的红黑结构保证了它的树的平衡性,保证了插入、删除、查找的效率即log(n),所以每当插入节点之后,再进行调整,以保证树的红黑结构。
TreeMap源码剖析
这里把TreeMap的具体动作方法进行介绍。
传入一个有序集合进行构造
public TreeMap(SortedMap<K, ? extends V> m) {
comparator = m.comparator();
try {
//从有序集合里面建立一个treemap
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
/**
* 从有序集合中获得数据并插入。
* 注意是有序的
*/
private void buildFromSorted(int size, Iterator<?> it,
java.io.ObjectInputStream str,
V defaultVal)
throws java.io.IOException, ClassNotFoundException {
this.size = size;
root = buildFromSorted(0, 0, size-1, computeRedLevel(size),
it, str, defaultVal);
}
/**
* 插入操作
*
* level :当前节点应该插入的层
* lo:子树的第一个节点
* hi:子树的最后一个节点
* @param 表明该层该节点必须为红色
*/
@SuppressWarnings("unchecked")
private final Entry<K,V> buildFromSorted(int level, int lo, int hi,
int redLevel,
Iterator<?> it,
java.io.ObjectInputStream str,
V defaultVal)
throws java.io.IOException, ClassNotFoundException {
//判断是否有错误
if (hi < lo) return null;
int mid = (lo + hi) >>> 1;
Entry<K,V> left = null;
//一直往下递归找到左子节点
if (lo < mid)
left = buildFromSorted(level+1, lo, mid - 1, redLevel,
it, str, defaultVal);
//找到了,设置值的过程。
K key;
V value;
if (it != null) {
if (defaultVal==null) {
Map.Entry<?,?> entry = (Map.Entry<?,?>)it.next();
key = (K)entry.getKey();
value = (V)entry.getValue();
} else {
key = (K)it.next();
value = defaultVal;
}
} else { // use stream
key = (K) str.readObject();
value = (defaultVal != null ? defaultVal : (V) str.readObject());
}
Entry<K,V> middle = new Entry<>(key, value, null);
// 设置完之后,就开始设置color以及将节点和待插入位置的父子节点连接起来。
if (level == redLevel)
middle.color = RED;
if (left != null) {
middle.left = left;
left.parent = middle;
}
if (mid < hi) {
//递归的方式,去获得下一个右下字节点
Entry<K,V> right = buildFromSorted(level+1, mid+1, hi, redLevel,
it, str, defaultVal);
middle.right = right;
right.parent = middle;
}
return middle;
}上面代码即通过传入一个有序的集合,来构造一个TreeMap,由于是有序集合,所以肯定是从二叉树的两头开始构造的。
getEntry方法
即通过一个key,获取key属于的那个节点。
/**
* 从实体中寻找key,默认是没有有comparator的。
* 就使用默认的compareTo来进行比较。
*
* 由此可知,key不能为null。
*/
final Entry<K,V> getEntry(Object key) {
// Offload comparator-based version for sake of performance
if (comparator != null)
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
Entry<K,V> p = root;
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
}getEntry方法只涉及二叉树的查找,所以不涉及调整,即从根节点开始一直向下查找。这段相关代码在上面将键是否为null时列举出来过,就不多讲了。
在二叉树结构的TreeMap中,并不是每次都能找到值,所以在TreeMap中,还提供了很多get方法,例如:
final Entry
/**
* 天花板,所以在上面,所以比k大的最小
* 找到一个,比key大的,最小的节点,可以等于k,获取TreeMap中不小于key的最小的节点;
若不存在(即TreeMap中所有节点的键都比key大),就返回null
* @param key
* @return
*/
final Entry<K,V> getCeilingEntry(K key) {
Entry<K,V> p = root;
while (p != null) {
int cmp = compare(key, p.key);
// 情况一:若“p的key” > key。
// 若 p 存在左孩子,则设 p=“p的左孩子”;
// 否则,返回p
if (cmp < 0) {
if (p.left != null)
p = p.left;
else
return p;
// 情况二:若“p的key” < key。
} else if (cmp > 0) {
// 若 p 存在右孩子,则设 p=“p的右孩子”
if (p.right != null) {
p = p.right;
} else {
// 若 p 不存在右孩子,则找出 p 的后继节点,并返回
// 注意:这里返回的 “p的后继节点”有2种可能性:第一,null;第二,TreeMap中大于key的最小的节点。
// 理解这一点的核心是,getCeilingEntry是从root开始遍历的。
// 若getCeilingEntry能走到这一步,那么,它之前“已经遍历过的节点的key”都 > key。
// 能理解上面所说的,那么就很容易明白,为什么“p的后继节点”又2种可能性了。
Entry<K,V> parent = p.parent;
Entry<K,V> ch = p;
while (parent != null && ch == parent.right) {
ch = parent;
parent = parent.parent;
}
return parent;
}
// 情况三:若“p的key” = key。
} else
return p;
}
return null;
} put方法
put方法步骤,先向下找最适合本(key,value)对的地方,然后插入,最后调整
/**
* 将一对键值对k,v插入到treemap中,如果k已经存在,则会发生替换,value将替换oldvalue
*/
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
//检查是否为null
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// 左右两条线,向下的查找
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
//找到了最佳的位置
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
//插入后的调整
fixAfterInsertion(e);
size++;
modCount++;
return null;
}delete方法
相比较与put方法来说,delete方法并不用再进行寻找节点,因为已经给了你这个节点了,当然有些方法如果只提供key的话,就还需要找到这个节点。
/**
* 删除p,然后重新调整平衡
*/
private void deleteEntry(Entry<K,V> p) {
modCount++;
size--;
// p有两个孩子节点
if (p.left != null && p.right != null) {
Entry<K,V> s = successor(p);
p.key = s.key;
p.value = s.value;
p = s;
} // p has 2 children
// 选取替代将要删除节点位置节点
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null) {
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
p.left = p.right = p.parent = null;
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) { // return if we are the only node.
root = null;
} else {
if (p.color == BLACK)
//删除后的调整
fixAfterDeletion(p);
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}TreeMap里面的Iterator
首先,TreeMap里面的Iterator也是fail-fast的。这里要注意一点,在Map里面的集合中,遍历操作只能通过Iterator来实现,因为Map里面不是线性表,所以你自然不能用类似于ArrayList等for循环走一遍就遍历到所有操作。
TreeMap里面有多个不同实现的Iterator
static class TreeMapSpliterator<K,V>:在TreeMap的Iterator中作为下面两个Iterator的父类,实现公共的Spliterater方法。
static final class KeySpliterator<K,V>:key的分割迭代器。
static final class DescendingKeySpliterator<K,V>:倒序的key的分割迭代器。
本文图片以及红黑树学习引用于:
julycoding















 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









