






这篇文章是从网上找到的,非常非常好,特别适合入门的人,里面有实际的一个挖掘例子,非常实用。推荐给大家。
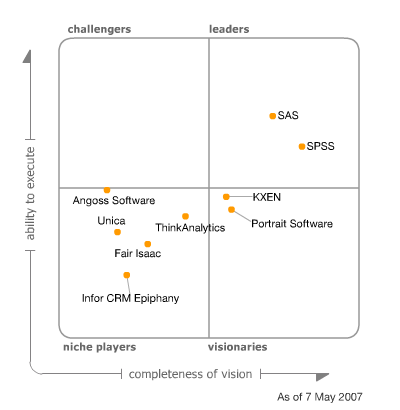
SPSS Clementine是Spss公司收购ISL获得的数据挖掘工具。在Gartner的客户数据挖掘工具评估中,仅有两家厂商被列为领导者:SAS和SPSS。SAS获得了最高ability to execute评分,代表着SAS在市场执行、推广、认知方面有最佳表现;而SPSS获得了最高的completeness of vision,表明SPSS在技术创新方面遥遥领先。
客户端基本界面
SPSS Clementine(在此简称clementine)在安装好后会自动启用服务,服务端的管理需要使用SPSS Predictive Enterprise Manager,在服务端clementine没有复杂的管理工具,一般的数据挖掘人员通过客户端完成所有工作。下面就是clementine客户端的界面。
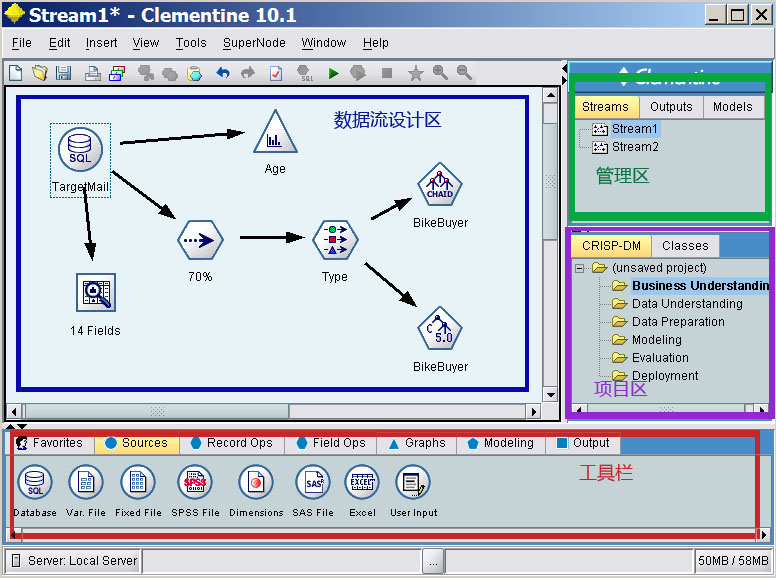
一看到上面这个界面,我相信只要是使用过SSIS+SSAS部署数据挖掘模型的,应该已经明白了六、七分。是否以跃跃欲试了呢,别急,精彩的还在后面 ^_’
项目区
顾名思义,是对项目的管理,提供了两种视图。其中CRISP-DM (Cross Industry Standard Process for Data Mining,数据挖掘跨行业标准流程)是由SPSS、DaimlerChrysler(戴姆勒克莱斯勒,汽车公司)、NCR(就是那个拥有Teradata的公司)共同提出的。Clementine里通过组织CRISP-DM的六个步骤完成项目。在项目中可以加入流、节点、输出、模型等。
工具栏
工具栏总包括了ETL、数据分析、挖掘模型工具,工具可以加入到数据流设计区中,跟SSIS中的数据流非常相似。Clementine中有6类工具。
源工具(Sources)
相当SSIS数据流中的源组件啦,clementine支持的数据源有数据库、平面文件、Excel、维度数据、SAS数据、用户输入等。
记录操作(Record Ops)和字段操作(Field Ops)
相当于SSIS数据流的转换组件,Record Ops是对数据行转换,Field Ops是对列转换,有些类型SSIS的异步输出转换和同步输出转换(关于SSIS异步和同步输出的概念,详见拙作:http://www.cnblogs.com/esestt/archive/2007/06/03/769411.html)。
图形(Graphs)
用于数据可视化分析。
输出(Output)
Clementine的输出不仅仅是ETL过程中的load过程,它的输出包括了对数据的统计分析报告输出。

※在ver 11,Output中的ETL数据目的工具被分到了Export的工具栏中。

模型(Model)
Clementine中包括了丰富的数据挖掘模型。

数据流设计区
这个没什么好说的,看图就知道了,有向的箭头指明了数据的流向。Clementine项目中可以有多个数据流设计区,就像在PhotoShop中可以同时开启多个设计图一样。
比如说,我这里有两个数据流:Stream1和Stream2。通过在管理区的Streams栏中点击切换不同的数量流。
管理区
管理区包括Streams、Outputs、Models三栏。Streams上面已经说过了,是管理数据流的。
Outputs
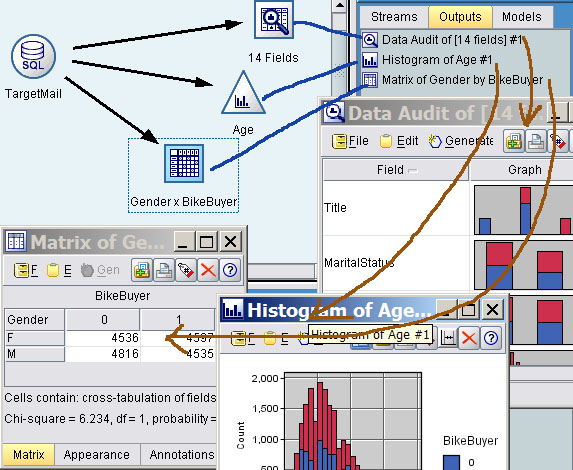
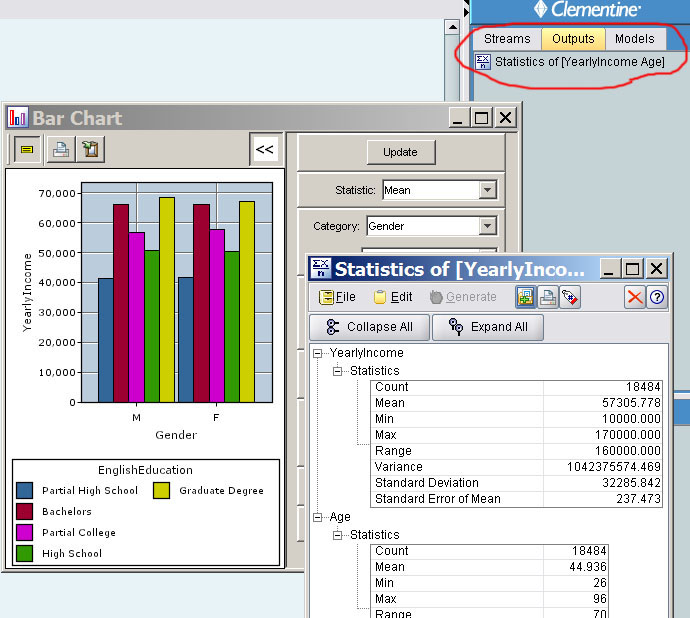
不要跟工具栏中的输出搞混,这里的Outputs是图形、输出这类工具产生的分析结果。例如,下面的数据源连接到矩阵、数据审查、直方图工具,在执行数据流后,这个工具产生了三个输出。在管理区的Outputs栏中双击这些输出,可看到输出的图形或报表。
Models
经过训练的模型会出现在这一栏中,这就像是真表(Truth Table)的概念那样,训练过的模型可以加入的数据流中用于预测和打分。另外,模型还可以导出为支持PMML协议的XML文件,但是PMML没有给定所有模型的规范,很多厂商都在PMML的基础上对模型内容进行了扩展,Clementine除了可以导出扩展的SPSS SmartScore,还可以导出标准的PMML 3.1。
下面使用Adventure Works数据库中的Target Mail作例子,通过建立分类树和神经网络模型,决策树用来预测哪些人会响应促销,神经网络用来预测年收入。
Target Mail数据在SQL Server样本数据库AdventureWorksDW中的dbo.vTargetMail视图,关于Target Mail详见:
http://technet.microsoft.com/zh-cn/library/ms124623.aspx#DataMining
或者我之前的随笔:
http://www.cnblogs.com/esestt/archive/2007/06/06/773705.html
1. 定义数据源
将一个Datebase源组件加入到数据流设计区,双击组件,设置数据源为dbo.vTargetMail视图。
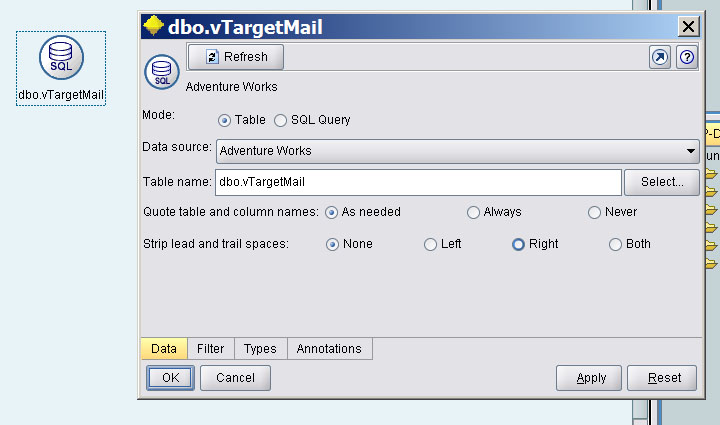
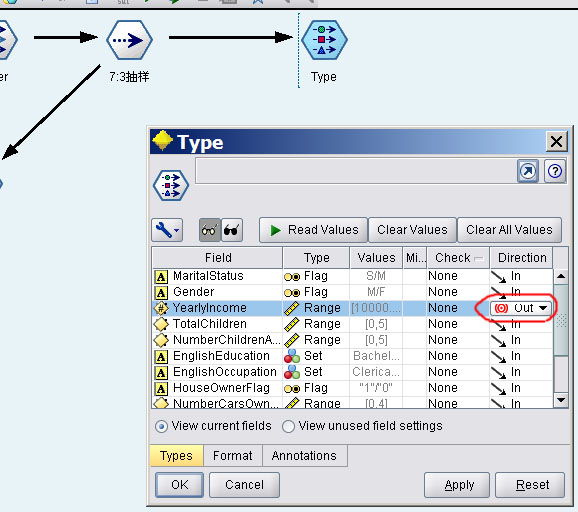
在Types栏中点“Read Values”,会自动读取数据个字段的Type、Values等信息。

Values是字段包含的值,比如在数据集中NumberCardsOwned字段的值是从0到4的数,HouseOwnerFlag只有1和0两种值。Type是依据Values判断字段的类型,Flag类型只包含两种值,类似于boolean;Set是指包含有限个值,类似于enumeration;Ragnge是连续性数值,类似于float。通过了解字段的类型和值,我们可以确定哪些字段能用来作为预测因子,像AddressLine、Phone、DateFirstPurchase等字段是无用的,因为这些字段的值是无序和无意义的。
Direction表明字段的用法,“In”在SQL Server中叫做“Input”,“Out”在SQL Server中叫做“PredictOnly”,“Both”在SQL Server中叫做“Predict”,“Partition”用于对数据分组。
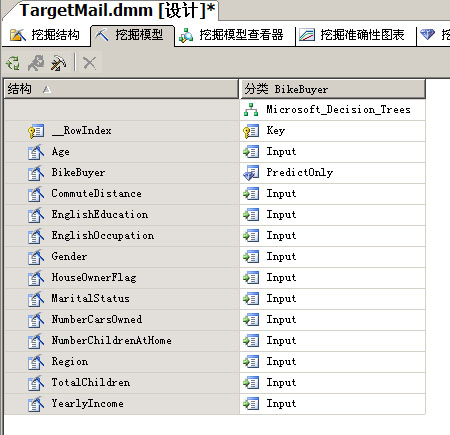
2. 理解数据
在建模之前,我们需要了解数据集中都有哪些字段,这些字段如何分布,它们之间是否隐含着相关性等信息。只有了解这些信息后才能决定使用哪些字段,应用何种挖掘算法和算法参数。
在除了在建立数据源时Clementine能告诉我们值类型外,还能使用输出和图形组件对数据进行探索。
例如先将一个统计组件和一个条形图组件拖入数据流设计区,跟数据源组件连在一起,配置好这些组件后,点上方绿色的箭头。
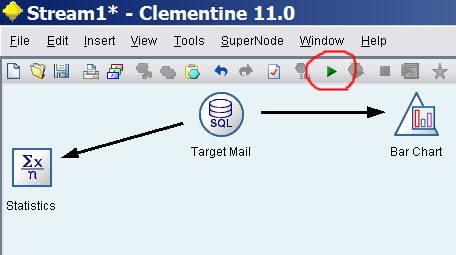
等一会,然后这两个组件就会输出统计报告和条形图,这些输出会保存在管理区中(因为条形图是高级可视化组件,其输出不会出现在管理区),以后只要在管理区双击输出就可以看打开报告。
3. 准备数据
将之前的输出和图形工具从数据流涉及区中删除。
将Field Ops中的Filter组件加入数据流,在Filter中可以去除不需要的字段。
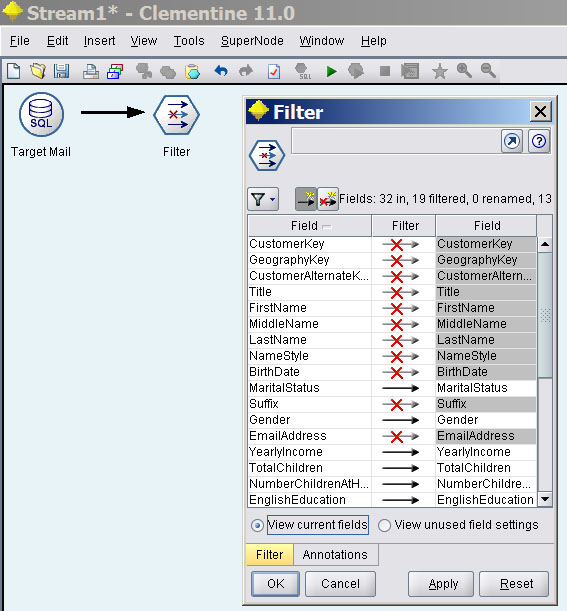
我们只需要使用MaritalStatus、Gender、YearlyIncome、TatalChildren、NumberChildrenAtHome、EnglishEducation、EnglishOccupation、HouseOwnerFlag、NumberCarsOwned、CommuteDistance、Region、Age、BikeBuyer这些字段。
加入Sample组件做随机抽样,从源数据中抽取70%的数据作为训练集,剩下30%作为检验集。
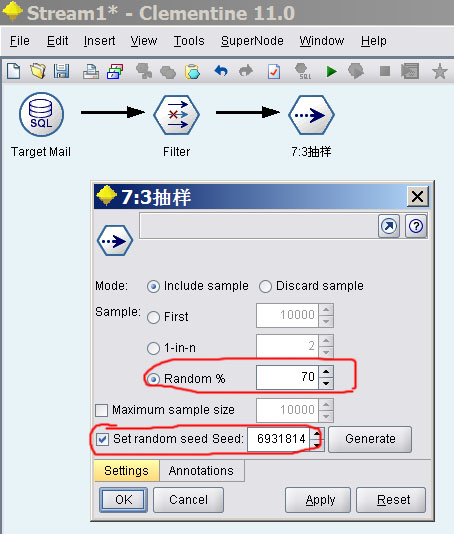
注意为种子指定一个值,学过统计和计算机的应该知道只要种子不变,计算机产生的伪随机序列是不变的。
因为要使用两个挖掘模型,模型的输入和预测字段是不同的,需要加入两个Type组件,将数据分流。
决策树模型用于预测甚麽人会响应促销而购买自行车,要将BikeBuyer字段作为预测列。
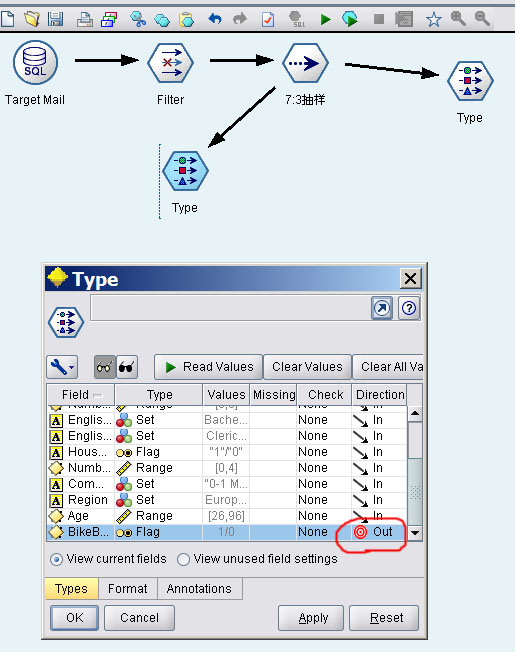
神经网络用于预测年收入,需要将YearlyIncome设置为预测字段。
有时候用于预测的输入字段太多,会耗费大量训练时间,可以使用Feature Selection组件筛选对预测字段影响较大的字段。
从Modeling中将Feature Selection字段拖出来,连接到神经网络模型的组件后面,然后点击上方的Execute Selection。
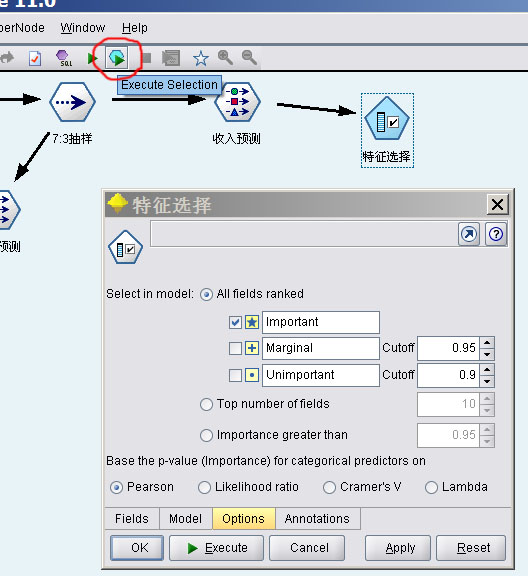
Feature Selection模型训练后在管理区出现模型,右击模型,选Browse可查看模型内容。模型从12个字段中选出了11个字段,认为这11个字段对年收入的影响比较大,所以我们只要用这11个字段作为输入列即可。

将模型从管理区拖入数据流设计区,替换原来的Feature Selection组件。
4. 建模
加入Nearal Net和CHAID模型组件,在CHAID组件设置中,将Mode项设为”Launch interactive session”。然后点上方的绿色箭头执行整个数据流。
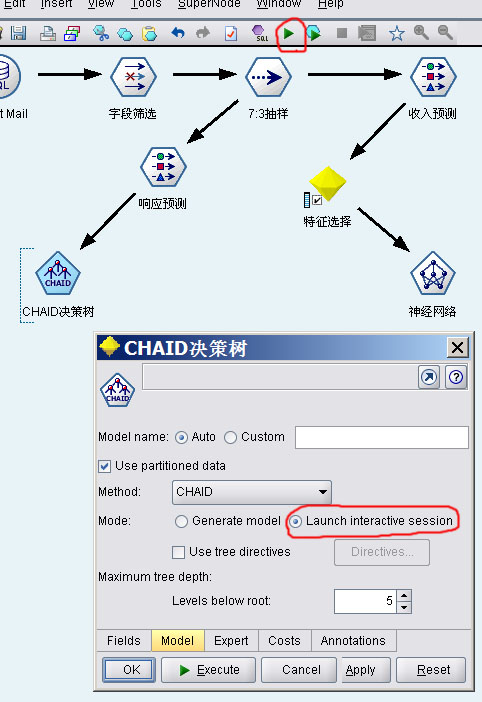
Clementine在训练CHAID树时,会开启交互式会话窗口,在交互会话中可以控制树生长和对树剪枝,避免过拟合。如果确定模型后点上方黄色的图标。
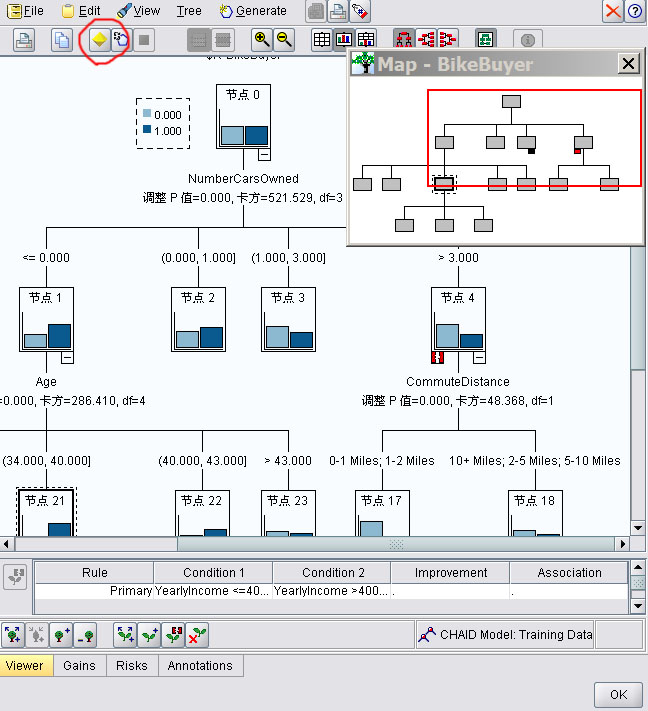
完成后,在管理区又多了两个模型。把它们拖入数据流设计区,开始评估模型。
5. 模型评估
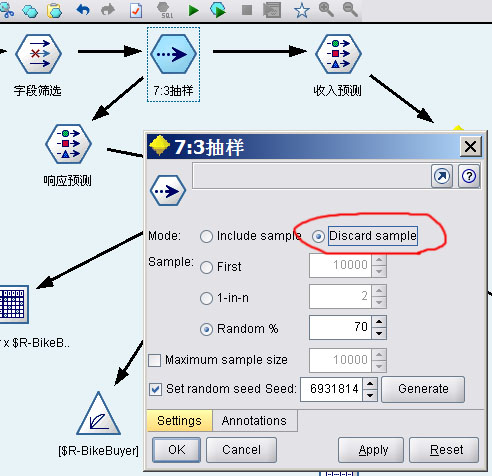
修改抽样组件,将Mode改成“Discard Sample”,意思是抛弃之前用于训练模型的那70%数据,将剩下30%数据用于检验。注意种子不要更改。
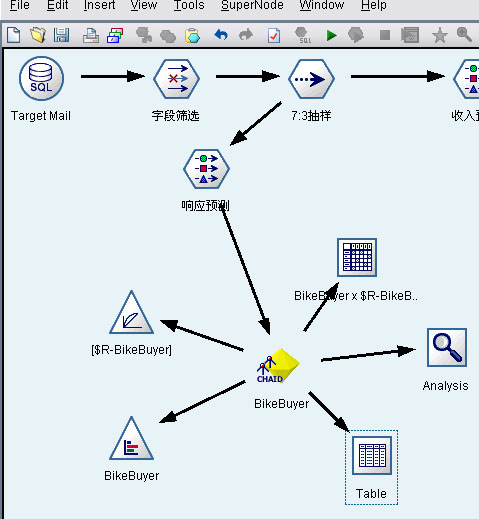
我这里只检验CHAID决策树模型。将各种组件跟CHAID模型关联。
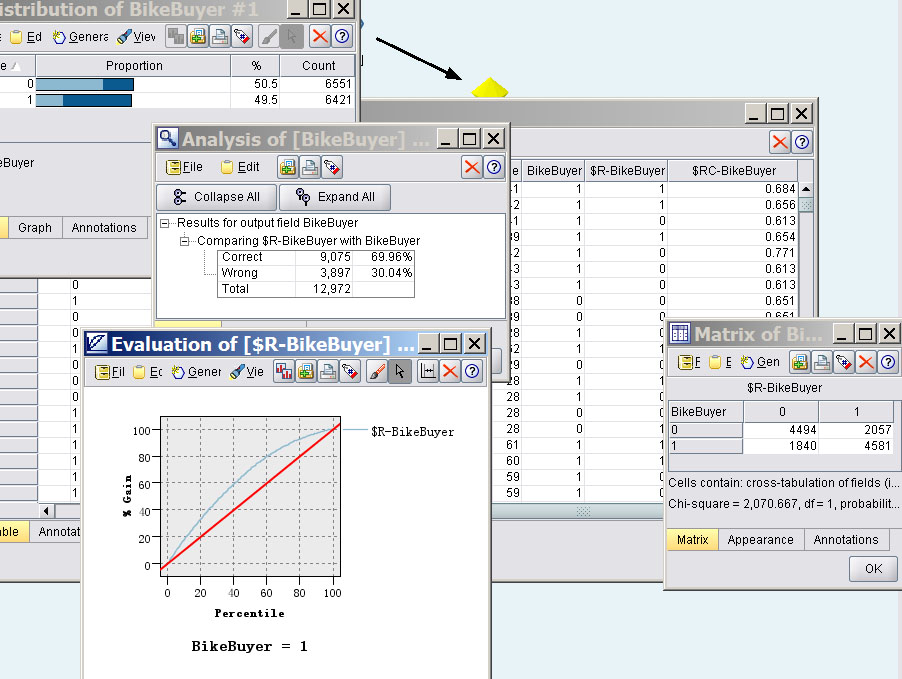
执行后,得到提升图、预测准确率表……
6. 部署模型
Export组件都可以使用Publish发布数据流,这里会产生两个文件,一个是pim文件,一个是par文件。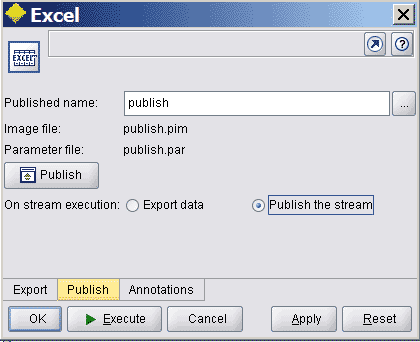
pim文件保存流的所有信息,par文件保存参数。有了这两个文件就可以使用clemrun.exe来执行流,clemrun.exe是Clementine Solution Publisher的执行程序。Clementine Solution Publisher是需要单独授权的。在SSIS中pim和par类似于一个dtsx文件,clemrun.exe就类似于dtexec.exe。
如果要在其他程序中使用模型,可以使用Clementine执行库(CLEMRTL),相比起Microsoft的ole db for dm,SPSS的提供的API在开发上还不是很好用。
了解SPSS Clementine的基本应用后,再对比微软的SSAS,各自的优缺点就非常明显了。微软的SSAS是Service Oriented的数据挖掘工具,微软联合SAS、Hyperion等公司定义了用于数据挖掘的web服务标准——XMLA,微软还提供OLE DB for DM接口和MDX。所以SSAS的优势是管理、部署、开发、应用耦合方便。
但SQL Server 2005使用Visual Studio 2005作为客户端开发工具,Visual Studio的SSAS项目只能作为模型设计和部署工具而已,根本不能独立实现完整的Crisp-DM流程。尽管MS Excel也可以作为SSAS的客户端实现数据挖掘,不过Excel显然不是为专业数据挖掘人员设计的。
PS:既然说到Visual Studio,我又忍不住要发牢骚。大家都知道Visual Studio Team System是一套非常棒的团队开发工具,它为团队中不同的角色提供不同的开发模板,并且还有一个服务端组件,通过这套工具实现了团队协作、项目管理、版本控制等功能。SQL Server 2005相比2000的变化之一就是将开发客户端整合到了Visual Studio中,但是这种整合做得并不彻底。比如说,使用SSIS开发是往往要一个人完成一个独立的包,比起DataStage基于角色提供了四种客户端,VS很难实现元数据、项目管理、并行开发……;现在对比Clementine也是,Clementine最吸引人的地方就是其提供了强大的客户端。当然,Visual Studio本身是很好的工具,只不过是微软没有好好利用而已,期望未来的SQL Server 2K8和Visual Studio 2K8能进一步改进。
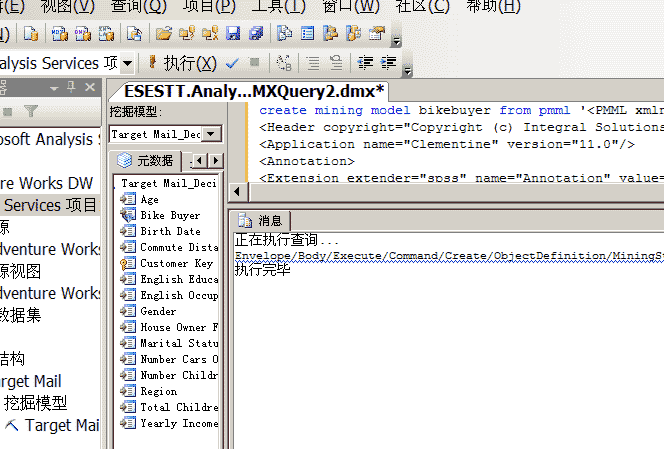
所以我们不由得想到如果能在SPSS Clementine中实现Crisp-DM过程,但是将模型部署到SSAS就好了。
首先OLE DB for DM包括了Model_PMML结构行集,可以使用DMX语句“Create Mining Model From PMML ”将SPSS Clementine导出的PMML模型加入SSAS。
如果我记得没错的话,SQL Server 2005 最初发表版本中Analysis Services是PMML 2.1标准,而Clementine 11是PMML 3.1的,两者的兼容性不知怎样,我试着将一个PMML文件加入SSAS,结果提示错误。
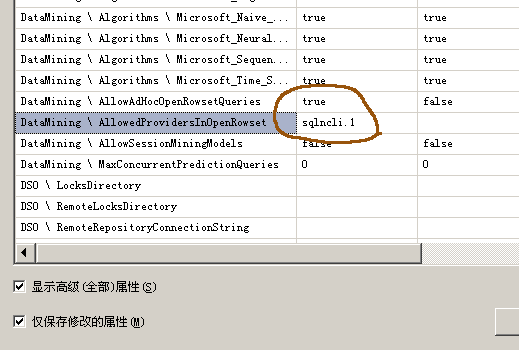
另外,在SPSS Clementine中可以整合SSAS,通过使用SSAS的算法,将模型部署到SSAS。具体的做法是:
在SSAS实例中修改两个属性值。
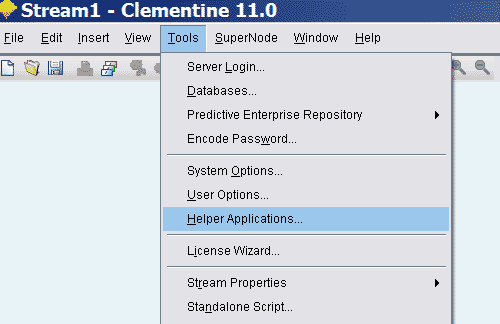
在Clementine菜单栏选Tools -> Helper Applications。
然后启用SSAS整合,需要选择SSAS数据库和SQL Server RMDBS,RMDBS是用来存储临时数据的,如果在Clementine的流中使用了SAS数据源,但SSAS不支持SAS数据文件,那么Clementine需要将数据源存入临时数据表中以便SSAS能够使用。
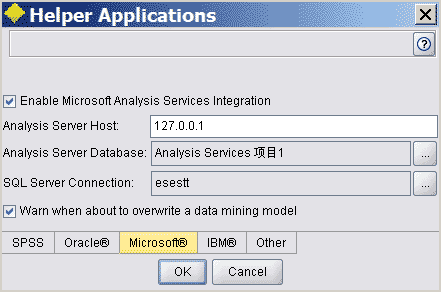
启用整合后,就可以在工具栏中看到多出了一类Datebase Modeling组件,这些都是SSAS的数据挖掘算法,接下来的就不用说了……

可惜的是SSAS企业版中就带有9中算法,另外还有大量第三方的插件,但Clementine 11.0中只提供了7种SSAS挖掘模型。














 2081
2081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









