




 本文详细解析了Spark在Standalone模式下,Client、Master和Worker之间的通信机制,重点介绍了基于akka的Actor模型如何实现模块间的RPC。Spark的Client提交作业到Master,Master管理Worker并启动Driver和Executor,Worker负责资源管理和心跳汇报。通过源码分析Client、Master和Worker的角色及交互流程。
本文详细解析了Spark在Standalone模式下,Client、Master和Worker之间的通信机制,重点介绍了基于akka的Actor模型如何实现模块间的RPC。Spark的Client提交作业到Master,Master管理Worker并启动Driver和Executor,Worker负责资源管理和心跳汇报。通过源码分析Client、Master和Worker的角色及交互流程。
Spark的Cluster Manager可以有几种部署模式:
- Standlone
- Mesos
- YARN
- EC2
- Local
在向集群提交计算任务后,系统的运算模型就是Driver Program定义的SparkContext向APP Master提交,有APP Master进行计算资源的调度并最终完成计算。具体阐述可以阅读《Spark:大数据的电花火石! 》。
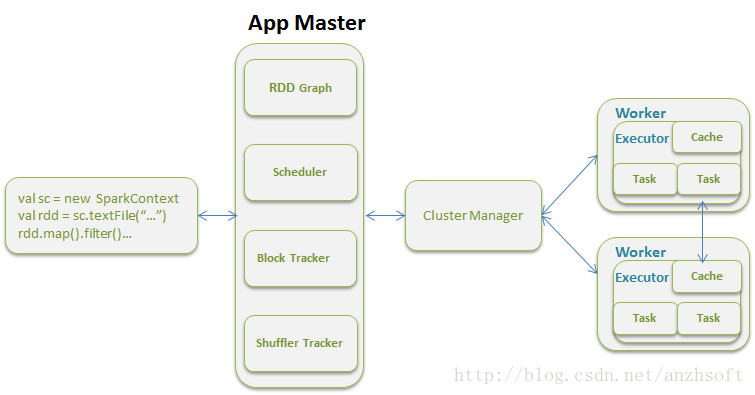
那么Standalone模式下,Client,Master和Worker是如何进行通信,注册并开启服务的呢?
1. node之间的RPC - akka
模块间通信有很多成熟的实现,现在很多成熟的Framework已经早已经让我们摆脱原始的Socket编程了。简单归类,可以归纳为基于消息的传递和基于资源共享的同步机制。
基于消息的传递的机制应用比较广泛的有Message Queue。Message Queue, 是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消 息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。其中较为成熟的MQ产品有IBM WEBSPHERE MQ和RabbitMQ(AMQP的开源实现,现在由Pivotal维护)。
还有不得不提的是ZeroMQ,一个致力于进入Linux内核的基于Socket的编程框架。官方的说法: “ZeroMQ是一个简单好用的传输层,像框架一样的一个socket library,它使得Socket编程更加简单、简洁和性能更高。是一个消息处理队列库,可在多个线程、内核和主机盒之间弹性伸缩。ZMQ的明确目标是“成为标准网络协议栈的一部分,之后进入Linux内核”。
Spark在很多模块之间的通信选择是Scala原生支持的akka,一个用 Scala 编写的库,用于简化编写容错的、高可伸缩性的 Java 和 Scala 的 Actor 模型应用。akka有以下5个特性:
- 易于构建并行和分布式应用 (Simple Concurrency & Distribution): Akka在设计时采用了异步通讯和分布式架构,并对上层进行抽象,如Actors、Futures ,STM等。
- 可靠性(Resilient by Design): 系统具备自愈能力,在本地/远程都有监护。
- 高性能(High Performance):在单机中每秒可发送50,000,000个消息。内存占用小,1GB内存中可保存2,500,000个actors。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3241
3241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









