







 本文介绍了Linux下网络I/O的五种模型:阻塞式、非阻塞式、I/O复用、信号驱动和异步I/O。前四种为同步模型,区别在于API和调用方式,而异步I/O是唯一由内核完成读写的模型。通过对比,读者可以更好地理解各种模型的工作原理。
本文介绍了Linux下网络I/O的五种模型:阻塞式、非阻塞式、I/O复用、信号驱动和异步I/O。前四种为同步模型,区别在于API和调用方式,而异步I/O是唯一由内核完成读写的模型。通过对比,读者可以更好地理解各种模型的工作原理。
1. Linux下网络I/O模型
对于Linux系统,Richard Stevens在<Unix 网络编程:卷一>中提到了5种网络I/O模型(下面的图也来自于这本书),分别是:1. 阻塞式I/O模型
2. 非阻塞I/O模型
3. I/O复用模型
4. 信号驱动I/O模型
5. 异步I/O模型
其中前4种模型是都是同步I/O模型,有的只是API和API调用方式有所区别,只有最后一种是异步I/O模型。这里区分的标准是I/O读写是否由内核,还是由用户进程来完成。
2. 阻塞式I/O模型
对于阻塞式I/O模型,用户层的收发进程或线程会一直阻塞,直到数据拷贝完成。具体见下图: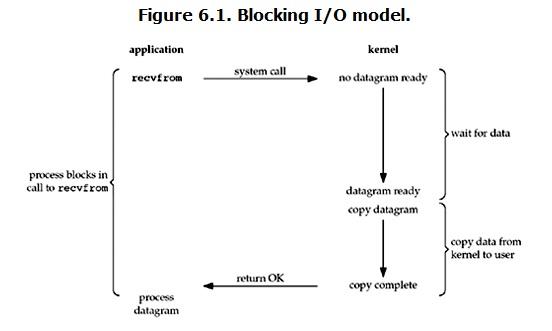
使用阻塞式I/O,server端的流程如下:
socket
|
bind
|
listen
|
accept
|
read/write
|
close客户端流程如下:
socket
|
connect
|
write/read
|
close使用阻塞模式的套接字,开发网络程序比较简单,容易实现。在套接字数量较少的情况下,可以考虑使用阻塞模型来开发。特别是在通讯双方,一问一答的形式下,阻塞模型实现最为简单。
如果需要在通讯的双方实现全双工,也就是每一方都能够同时收发数据,使用阻塞式套接字,意味着程序为每个连接必须存在两个线程。如果线程之间还需要同步,在大量套接字的情况下,阻塞式Socket模型难以维护,难以扩展。
3. 非阻塞I/O模型
对于非阻塞I/O模型,用户需要通过进程反复调用I/O函数(多次系统调用,并马上返回)。阻塞模式套接字的不足表现为,在大量建立好的套接字线程之间进行通信时比较困难。当使用“生产者-消费者”模型开发网络程序时,为每个套接字都分别分配一个读线程、一个处理数据线程和一个用于同步的事件,那么这样无疑加大系统的开销。其最大的缺点是当希望同时处理大量套接字时,将无从下手,扩展性很差。 具体见下图: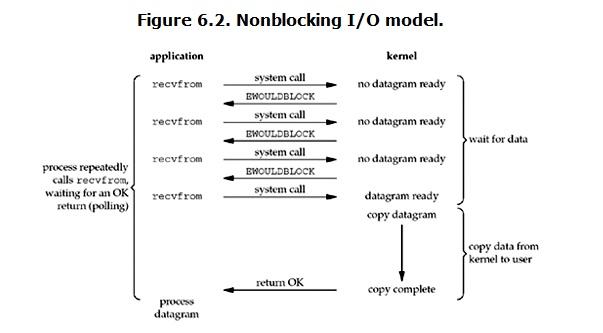
从上图中可以看出,这是一
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









