







 本文详细介绍了Python中的排序算法,包括递归、时间复杂度分析、列表查找和排序算法。重点讲解了冒泡排序、选择排序、插入排序、快速排序、堆排序和归并排序的原理和时间复杂度,并探讨了它们在不同场景下的应用和优缺点。
本文详细介绍了Python中的排序算法,包括递归、时间复杂度分析、列表查找和排序算法。重点讲解了冒泡排序、选择排序、插入排序、快速排序、堆排序和归并排序的原理和时间复杂度,并探讨了它们在不同场景下的应用和优缺点。
Python排序算法总结
递归
在正式讲算法之前,先介绍一下递归。递归是一种解决问题的思路。
特点
- 调用自身
- 必须有一个明确的结束条件,比如
if... - 递归的两个阶段:
- 递推(压栈):到某个阶段,该阶段返回一个值(没有返回值,默认返回None)
- 回溯(出栈):从那个阶段回溯
- 每进入更深一次递归时,问题规模减少
- 递归效率不高(保存系统堆栈,跳进去,还要再跳出来)
应用场景
知道结束的条件,但不确定循环次数。
示例1
观察以下函数,如果x=3,哪些是递归,输出结果是什么
def func1(x):
print(x)
func1(x-1)
# func1 没有结束条件,pass
def func2(x):
if x>0:
print(x)
func2(x+1)
# func2 结束条件永远不成立,pass
def foo(x):
if x>0:
print(x)
foo(x-1)
# foo 结果:3 2 1
def bar(x):
if x>0:
bar(x-1)
print(x)
# bar 结果:1 2 3上面的几个函数,foo 和 bar 的输出结果是相反的,我们来分析一下它们的执行流程:
foo函数
- 调用foo(3),入栈,stack=[foo(3)]
- if 3>0 成立
- 打印当前x值为3
- 调用 foo(2),入栈,stack=[foo(3), foo(2)]
- if 2>0 成立
- 打印当前x值为2
- 调用 foo(1),入栈,stack=[foo(3), foo(2), foo(1)]
- if 1>0 成立
- 打印当前x值为1
- 调用 foo(0),入栈,stack=[foo(3), foo[2], foo(1), foo(0)]
- if 0>0,条件不成立,下面代码不再执行。
- foo(0)执行完毕,出栈,stack=[foo(3), foo[2], foo(1)]
- foo(1) 执行完毕,出栈,stack=[foo(3), foo[2]]
- foo(2) 执行完毕,出栈,stack=[foo(3)]
- foo(3)执行完毕,出栈,栈空,stack=[ ]
图示:
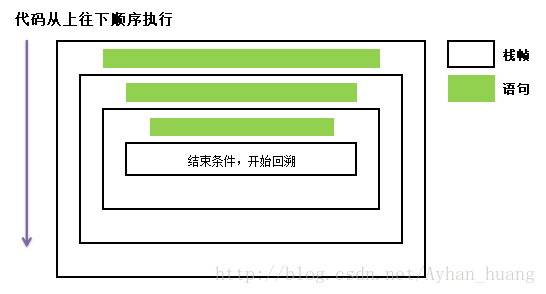
bar函数
- 调用bar(3),入栈,stack=[bar(3)]
- if 3>0 成立
- 调用 bar(2),入栈,stack=[bar(3), bar(2)]
- if 2>0 成立
- 调用 bar(1),入栈,stack=[bar(3), bar(2), bar(1)]
- if 1>0 成立
- 调用 bar(0),入栈,stack=[foo(3), foo[2], foo(1), foo(0)]
- if 0>0,条件不成立,下面代码不再执行。
- foo(0)执行完毕,出栈,stack=[bar(3), bar[2], bar(1)]
- 打印当前x值为1
- foo(1) 执行完毕,出栈,stack=[foo(3), foo[2]]
- 打印当前x值为2
- foo(2) 执行完毕,出栈,stack=[foo(3)]
- 打印当前x值为3
- foo(3)执行完毕,出栈,栈空,stack=[ ]
图示:
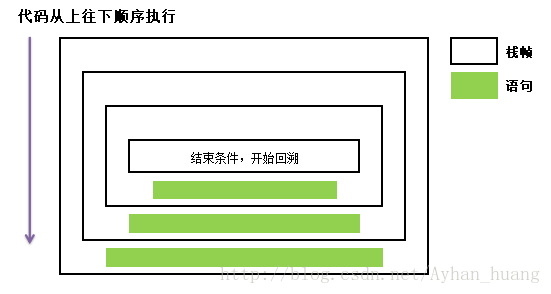
小结
观察bar和foo的执行,都是要”跳进去“,然后”跳出来“,bar进去的时候打印,foo是出来的时候打印,因此它们的输出相反。正式因为还要跳出来,导出递归效率不高,尽管如此,有些问题必须用递归思想思想才能解决。
其实如果不跳出来,递归的速度也不慢。这个涉及尾递归,在此不讨论。
示例2
用递归打印下面这句话:

观察跳进去的时候打印,跳出来的时候也打印,实现如下
def little_fish(x):
print('抱着',end='')
if x == 0:
print('我的小鲤鱼',end='')
else:
little_fish(x-1)
print('的我',end='')
print('吓得我抱起了')
little_fish(2)
"""
吓得我抱起了
抱着抱着抱着我的小鲤鱼的我的我的我
"""示例3
汉诺塔问题,将所有的盘子,从a柱移到c柱,保持小的在上面,大的在下面,问怎么移?
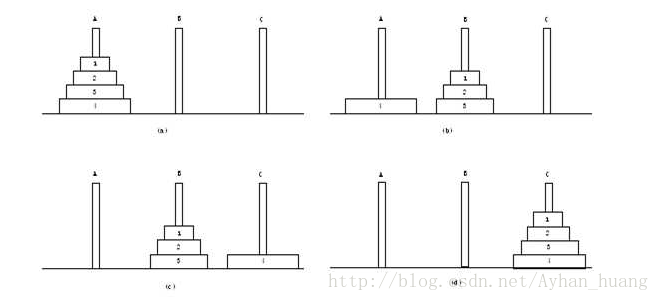
def hanoi(x, a, b, c): # 所有的盘子从 a 移到 c
if x>0:
hanoi(x-1, a, c, b) # step1:除了下面最大的,剩余的盘子 从 a 移到 b
print('%s->%s'%(a, c)) # step2:最大的盘子从 a 移到 c
hanoi(x-1, b, a, c) # step3: 把剩余的盘子 从 b 移到 c
hanoi(2, 'a', 'b', 'c')
""" 2个的情况,不论有多少个,最终都是这个模式
a->b
a->c
b->c
"""
hanoi(3, 'a', 'b', 'c')
""" 3个的情况
a->c
a->b
c->b
a->c
b->a
b->c
a->c
"""时间复杂度
看代码,猜快慢
下面四组代码,哪组运行时间最短?
print('Hello World')for i in range(n):
print('Hello World')for i in range(n):
for j in range(n):
print('Hello World')for i in range(n):
for j in range(n):
for k in range(n):
print('Hello World')直觉告诉我们,肯定是第一组。那么用什么方式来体现代码(算法)运行的快慢呢?时间复杂度
我们来类比一下生活中的场景:
- 眨一下眼:一瞬间/几毫秒
- 口算“29+68”:几秒
- 烧一壶水:几分钟
- 睡一觉:几小时
- 完成一个项目:几天/几星期/几个月
- 飞船从地球飞出太阳系:几年
也就是说,时间复杂度是一个估算的结果,用它来描述算法的快慢。用描述上限的数学符号 O() 来表示算法在最坏情况下的运行时间。
渐进分析
1)对于一些输入,第一个算法可能比第二个快,对于另外一些输入呢,第二个又比第一个好。
2)也有可能对于一些输入,第一个算法在一个机器上比第二个算法好,但是在另一台机器上第二个又比第一个好。
渐近分析是一个大问题,它就是在算法分析中处理上面的问题的。在渐近分析中,我们用输入的大小来评估算法的性能(我们不测量具体的运行时间)。我们计算的是随着输入大小的增加,算法所需要的时间(或者空间)。例如,我们考虑一个有序数组的搜索问题(搜索一个指定项)。
一个方法就是线性查询(递增顺序是线性的),另一个方法就是二分查询(递增顺序是对数级的)。为了能够很好滴理解渐近分析是怎样在算法分析中解决上面提到的问题,我们假设让线性查找在一个快的机器上跑,而让二分查询在一个慢的机器上跑。对于输入数组的大小比较小的时候,那么快的计算机花费的时间可能较少。但是,当输入的数组大小增长到一定程度的时候,二分查询的花费时间毫无疑问要比线性查询花费的时间要少,尽管二分查询是在比较挫的机器上跑的。原因是对递增数组进行二分查询对于输入的大小是对数级的,而线性查询则是线性级的。所以在特定的输入大小之后,机器的本身是可以忽略的。
在确定时间复杂度度时,使用渐近分析的方式:我们不关注常数因子和低阶项,比如有如下表达式:
T(n)=168n3+65n2+n+10000
根据数学原理,当一个函数(如这里的T(n))的n变得非常大以至于趋于无穷时,函数值的大小主要是由函数的最高阶项来决定的。T(n)的最高阶
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2905
2905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









