




dictmatch基本数据结构及算法
dictmatch其实是实现了最简单的Trie树的算法,而且并没有进行穿线改进,因此其是需要回朔的。但是其使用2个表来表示Trie树,并对其占用空间大的问题进行了很大的优化,特点是在建树的时候比较慢,但在查询的时候非常快。而且其使用的hash算法也值得一讲。
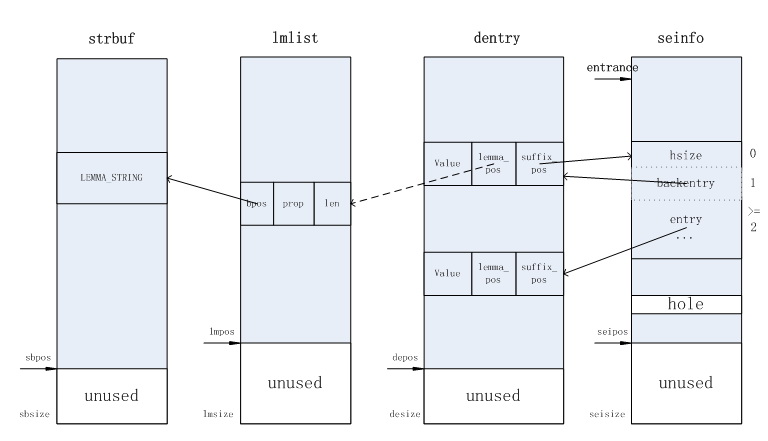
字典数据结构:
typedef struct _DM_DICT
{
char* strbuf; // buffer for store word result;
u_int sbsize;
u_int sbpos; // the next position in word buf
dm_entry_t* dentry; // the dict entry list
u_int desize;
u_int depos; // the first unused pos in de list
u_int* seinfo; // the suffix entry list
u_int seisize;
u_int seipos;
dm_inlemma_t* lmlist; // the lemma list
u_int lmsize;
u_int lmpos; // the first unused pos in lemma list
u_int entrance;
}dm_dict_t;
//lemma structure for dict
typedef struct _DM_INLEMMA
{
u_int len;
u_int prop;
u_int bpos;
}dm_inlemma_t;
typedef struct _DM_ENTRY
{
u_int value;
u_int lemma_pos;
u_int suffix_pos;
}dm_entry_t;
其中,dentry可以认为存放树的每个节点,seinfo可以认为存放每个节点的子树的指针列表(即后继块),lmlist存放完成匹配对应的某模式,而strbuf记录所有模式的字符串内容。
每个表的空间都预先开好,以xxxsize为大小。而xxxpos指针之前是已用空间,之后是未使用空间。
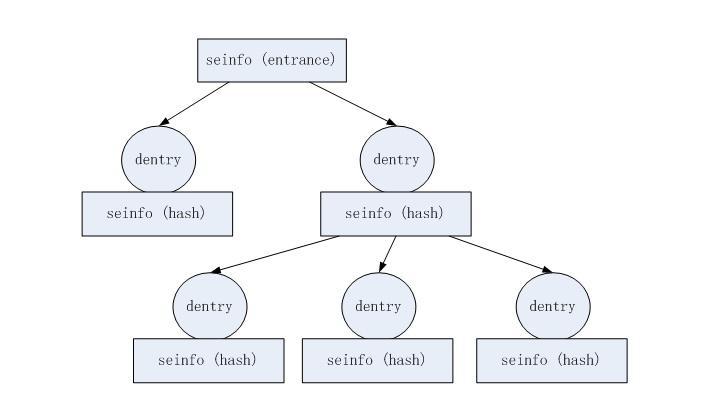
seinfo中,每个后继块首字节放的是该后继块的hash表大小,第二个字节指向其属主dentry节点,第三个字节开始是存放子树指针的hash表。因此,每个后继块的大小为hsize+2。
entrance指向了虚根节点所引出的每棵树的指针列表,也就是整个Trie树的入口。
图示:
此数据结构优点:
结构简单,利于存入和读取二进制文件,节约内存,内存分配次数较少,搜索的时候寻找子节点最快
此数据结构缺点:
不够直观,需要复杂的手动维护,建树时间较长
建树算法:(lemma指得就是一个模式)
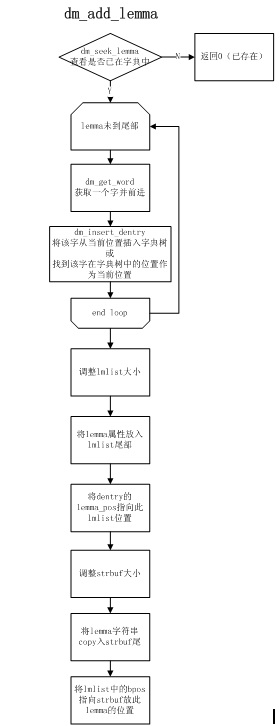
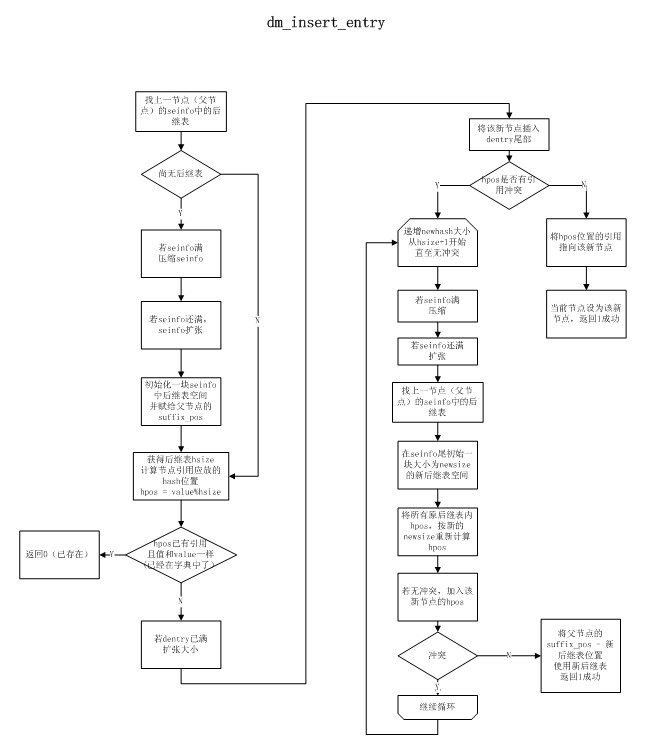
搜索模式匹配
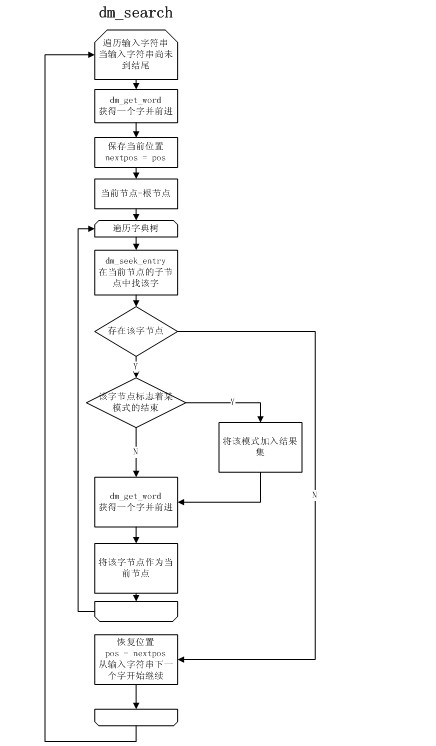
【百度分享】dictmatch及多模算法串讲 -- dictmatch基本数据结构及算法
最新推荐文章于 2023-06-19 09:29:51 发布
 本文介绍了一种基于Trie树的高效字符串匹配算法——dictmatch。该算法通过使用两个表来表示Trie树并优化存储空间,使得在查询时速度极快。文中详细解释了其数据结构特点、建树算法及搜索模式匹配过程。
本文介绍了一种基于Trie树的高效字符串匹配算法——dictmatch。该算法通过使用两个表来表示Trie树并优化存储空间,使得在查询时速度极快。文中详细解释了其数据结构特点、建树算法及搜索模式匹配过程。

















 4396
4396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









