







串行实现
根据线性代数的基本知识,m × l 的矩阵A,乘以一个大小为 l × n 的矩阵B,将得到一个 m × n 的矩阵C=A×B,其中
下图是用图示来表示的这种计算规则:
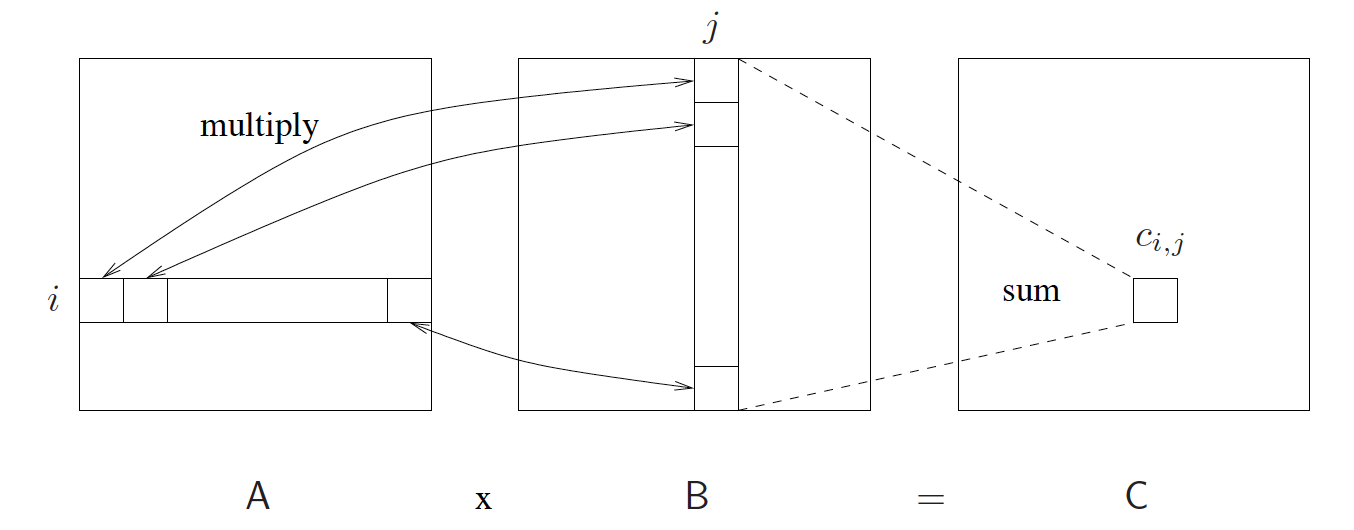
为了方便讨论,我们可以不是普遍性地假设有所矩阵的大小都是 n × n 的,下面就是串行实现的矩阵乘法的代码:
int A[n][n], B[n][n], C[n][n];
...
for(i=0;i<n;i++){
for(j=0;j<n;j++){
C[i][j]=0;
for(k=0;k<n;k++)
C[i][j]+=A[i][k]*B[k][j];
}
}
易见,这个算法的计算复杂度为O(n^3)。
基本并行实现的讨论
正如前面所讲的,矩阵相乘过程中,结果矩阵C中的每个元素都是可以独立计算的,即彼此之间并无依赖性。所以如果采用更多的处理器,将会显著地提高矩阵相乘的计算效率。
对于大小为n × n 的矩阵,加入我们有n个处理器,那么结果矩阵中的每一行,都可以用一个处理器来负责计算。此时,总共的并行计算步数为 O(n^2)。你可以理解为在串行实现的代码中,最外层的循环 for(i=0;i<n;i++) 被分别由n个处理器来并行的执行,而每个处理需要完成的任务仅仅是内部的两层循环。
如果采用n^2个处理器,那么就相当于结果矩阵中的每个元素都由一个处理器来负责计算。此时,总共的并行计算步数为 O(n)。你可以理解为在串行实现的代码中,最外面的两层循环 被分解到n^2个处理器来并行的执行,而每个处理需要完成的任务仅仅是内部的一层循环,即for(k=0;k<n;k++)。
更进一步,如果有n^3个处理器,那么即使最内层的循环for(k=0;k<n;k++)也有n个处理器在并行的负责。但是最终的求和运算,我们需要一个类似reduction的操作,因此最终的计算复杂度就是O(log n)。
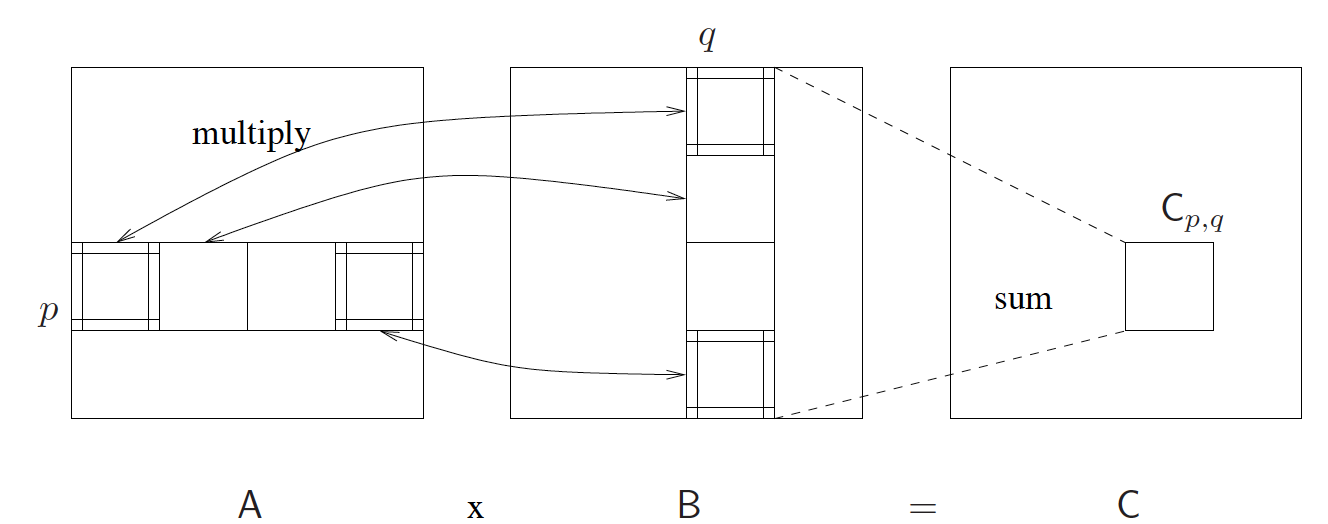
当然,你一定会想到的是,实际中,通常并不可能有像矩阵元素那么多的处理器资源。这时我们该怎么做。对于一个大小为n × n 的大矩阵A,我们其实可以把它切分成s^2个子矩阵Ap,q,每个子矩阵的大小为 m × m,其中 m = n / s,即0 <= p, q < s。对于两个大矩阵A和B,现在我们有:
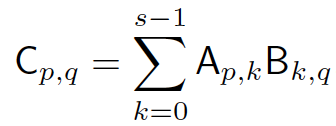
用图示表示则有:
Cannon算法
著名的Cannnon算法使用一个由s^2个处理器组成的二维网孔结构(mesh),而且这个mesh还是周边带环绕的(The processors are connected as a torus)。处理器Processor (i,j) (我们用它来表示位于位置(i,j)处的处理器)最开始时存有子矩阵Ai,j和Bi,j。随着算法的进行,这些子矩阵会向左或向上位移。如下图所示:
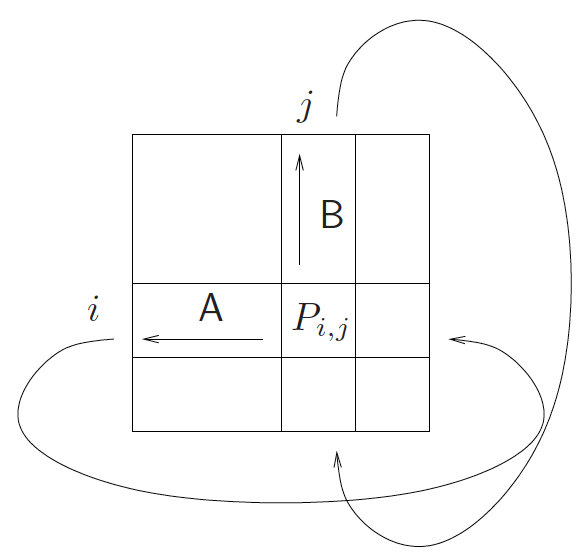
这个算法的根本出发点是在处理器阵列中,要合理分布两个待乘的矩阵元素。由乘积公式可知,要在处理单元 P(i,j)中计算乘积元素C(i,j),必须在该单元中准备好矩阵元素A(i,s)和B(s,j)。但是如果我们像下图那样分布矩阵元素,我们在计算C(i,j)时所需的元素显然是不足够的,但是可以通过向上循环位移B的元素,并向左循环位移A的元素,来获取合适的成对的矩阵元素。
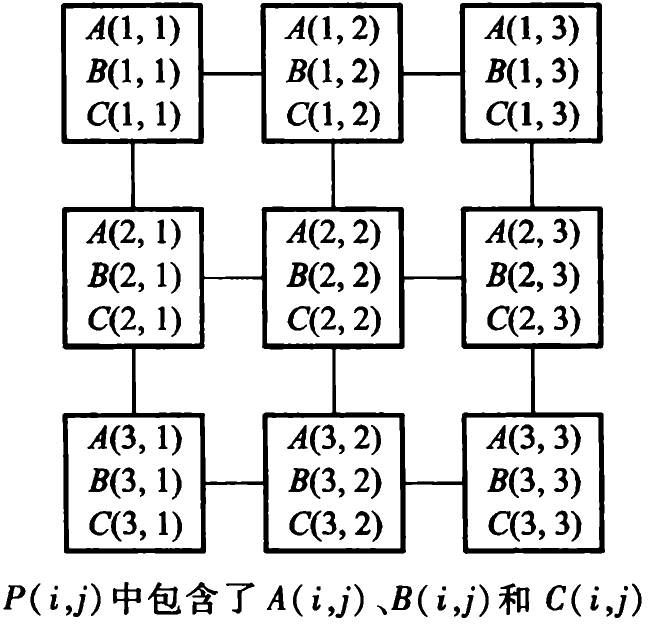
Cannnon算法的具体流程:

下面是矩阵位移的一个示例,其中s=3;

显然,算法的复杂度 t(n)=O(n), p(n) = n^2,w(n) = O(n^3),所以是成本最佳的。
---------------------------------------------
参考文献与推荐阅读材料
【1】陈国良,并行算法的设计与分析(第3版),高等教育出版社,2009
【2】矩阵计算并行算法(百度文库地址:http://wenku.baidu.com/view/d64ba9b4b14e852458fb57fc.html)
(本文完)


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











