







HBase过滤器简介
HBase过滤器(filter)提供非常强大的特性帮助用户提高其处理表中数据的效率。
HBase中两种主要的数据读取函数是get()和scan(),他们都支持直接访问数据和通过指定起止行键访问数据的功能。
Get和Scan两个类都支持过滤器,理由是因为这类对象提供的API不能对行健、列名和列值进行过滤,但是通过过滤器可以直接这个目的。
过滤器最基本的接口是Filter,所有的过滤器都在服务器端生效,叫做谓词下推(predicate push down)。这样可以保证所有过滤掉的数据不会被传送到客户端。
下图描述了过滤器怎样在客户端配置,怎样在网络传输中被序列化,怎样在服务器中执行。
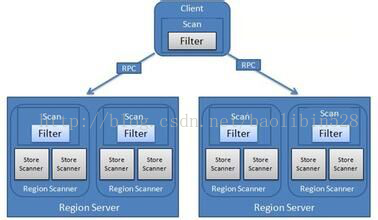
1、客户端创建Scan过滤器;
2、发送过滤器数据的序列化Scan;
3、RegionServer使用过滤器对Scan进行序列化。
总结:过滤器在客户端创建,通过RPC传送到服务器端,然后在服务器端进行过滤操作。
1、过滤器层次结构:
在过滤器层次结构中的最底层的是Filter接口和FilterBase抽象类,它们实现了过滤器的空壳和骨架。
其中有一组特殊的过滤器,它们继承自CompareFilter,需要用户同时提供至少两个特定的参数。
2、比较运算符:
继承自CompareFilter的过滤器比基类FilterBase多了一个comoare()方法,需要传入参数定义比较操作的过程。
HBase过滤器的比较操作符:
LESS <
LESS_OR_EQUAL <=
EQUAL =
NOT_EQUAL <>
GREATER_OR_EQUAL >=
GREATER >
NO_OP no operation
当过滤器被应用时,比较运算符可以决定什么被包含,什么被排除。这样可以帮助用户筛选数据的一段子集或一些特定的数据。
3、比较器:
CompareFilter所需要的第二类类型就是比较器,提供多种方法比较不同键值。比较器都继承自WritableByteArrayComparable,WritableByteArrayComparable实现了Writable和Comparable。
HBase对基于CompareFilter的过滤器提供的比较器

后3种比较器只能和EQUAL和NOT_EQUAL运算符搭配使用。
基于字符串的比较器,如RegexStringComparator和SubstringComparator,比基于字节的比较器更慢,更消耗资源。因为每次比较时它们都需要将给定的值转化为String.
截取字符串子串和正则式的处理也需要花费额外的时间。
过滤器本来的目的是为了筛掉无用的信息,所有基于CompareFilter的过滤处理过程是返回匹配的值。
比较器具体实现看这篇文章:http://blog.csdn.net/baolibin528/article/details/46045823
过滤器处理一行数据的逻辑流程:
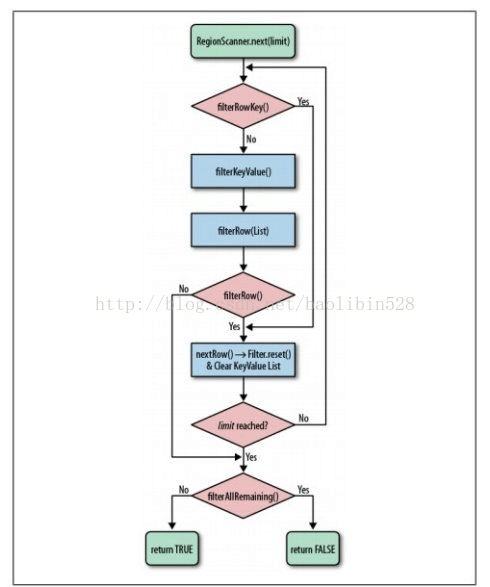
过滤器属性和它们之间的兼容性:
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









