




 本文介绍了神经网络的基础概念,包括sigmoid函数、M-P神经元模型、感知器模型及其局限性,以及多隐层前馈神经网络的工作原理。此外,还详细解释了BP算法在神经网络参数优化中的应用,包括标准BP算法和累积BP算法的区别。
本文介绍了神经网络的基础概念,包括sigmoid函数、M-P神经元模型、感知器模型及其局限性,以及多隐层前馈神经网络的工作原理。此外,还详细解释了BP算法在神经网络参数优化中的应用,包括标准BP算法和累积BP算法的区别。
神经网络
sigmoid函数
sigmoid函数是一种常见的挤压函数,其将较大范围的输入挤压到(0,1)区间内,其函数的表达式与形状如下图所示:
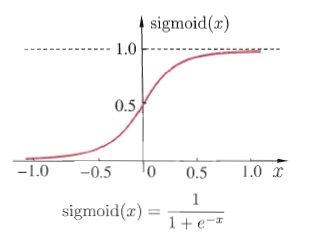
该函数常被用于分类模型,因为其具有很好的一个特性f′(x)=f(x)(1−f(x))。这个函数也会被用于下面的神经网络模型中做激活函数。
M-P神经元模型
生物的神经网络系统中,最简单最基本的结构是神经元。每个神经元都是接受其他多个神经元传入的信号,然后将这些信号汇总成总信号,对比总信号与阈值,如果超过阈值,则产生兴奋信号并输出出去,如果低于阈值,则处于抑制状态。McCulloch在1943年将该过程抽象成如下图所示的简单模型:
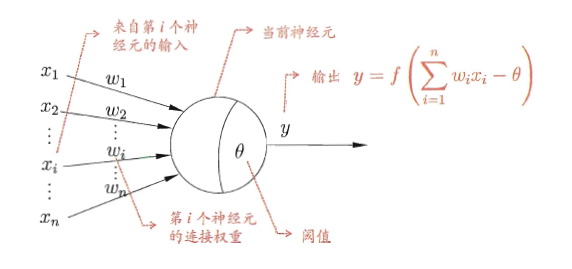
该模型称为“M-P神经元模型”。通过上图我们可以知道,当前神经元的输入是来自其他n个神经元的带权值的输出,而激活函数f()是一个如下图所示的阶跃函数
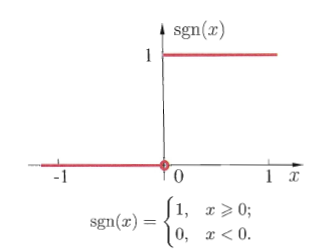
我们可以看到当总的输入小于阈值的时候,神经元处于抑制状态,输出为0,而当总输入大于阈值,则神经元被激活为兴奋状态,输出1。但是我们发现该函数是不连续且不光滑的,使用起来会很不方便,因此在实际应用中常常使用sigmoid函数代替阶跃函数做神经元的激活函数。
感知器模型
感知器模型,是一种最简单的神经网络模型结构,其网络结构包括输入层与输出层两层,如下图所示:
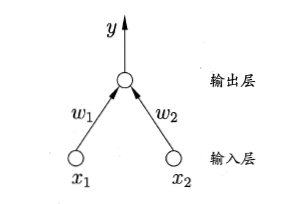
其为具有两个输入神经元,一个输出神经元的感知器模型。我们知道该模型是可以做与或非运算的。这是因为如果我们要做与或非运算,那么对于输入x1,x2来说,其取值只能是0或1,而我们的输出y=f(∑2i=1ωixi−θ),如果要做与运算,那令阈值ω1=1,ω2=1,θ=2,则只有在x1=1,x2=1的时候才能激活输出层神经元,输出1,其余情况均输出0。同样,如果做或运算,那令阈值ω1=1,ω2=1,θ=1,则只要有一个输入xi=1,即可激活输出神经元,输出1,如果对x1做非运算,那么可以令阈值ω1=−0.6,ω2=0,θ=−0.5,则如果x1=1,x2=0,总输入为−0.6,小于阈值,输出0,如果x1=0,x2=0,总输入为0,大于阈值,输出1。这里的激活函数为阶跃函数。这个通过下面的三幅图也可以看得出来
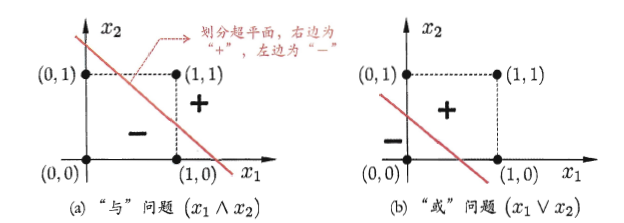
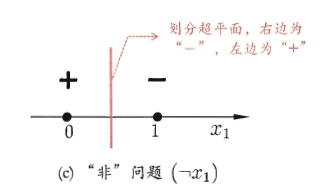
但是我们可以发现,对于只有输入层与输出层的感知机模型,∑2i=1ωixi−θ是线性的,其只能对线性数据进行划分,对于如下图的异或模型,其实无法准确划分的。
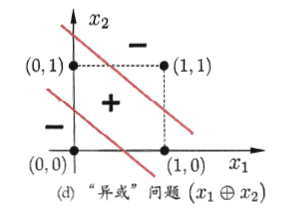
因为任何一条线都无法将(1,0),(0,1)划为一类,(0,0),(1,1)划为一类。但如果是像图(a)中那样的两层网络(这里的两层指的是隐层与输出层,因为只有这两层中的节点是有激活函数的),在隐层有两个节点,那么此时就可以得到两条线性函数,再在输出节点汇总之后,将会得到由两条直线围成的一个面,如图(b)所示,这时就可以成功的将异或问题解决。
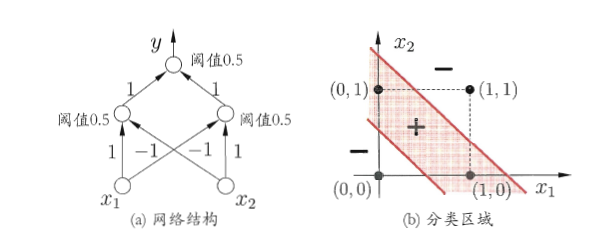
因此我们可以看到,随着网络深度的增加,每一层节点个数的增加,都可以加强网络的表达能力,网络的复杂度越高,其表示能力就越强,也就可以表达更复杂的模型。
通过上面你的示例,我们也可以看到,对网络的学习其实主要是对网络中各个节点之间的连接权值和阈值的学习,即寻找最优的连接权值和阈值从而使得该模型可以达到最优(一般是局部最优)。下面主要介绍多隐层前馈神经网络模型参数的学习方法。
多隐层前馈神经网络
对于多隐层前馈神经网络,其网络中相邻两层是全连接,而层内是没有连接的,跨层之间也没有连接,如下图所示:
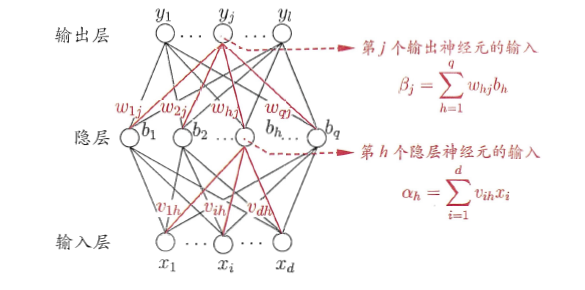
这里是一个单隐层的前馈神经网络,可以看到该网络的参数主要是输入层与隐层之间的连接权值ωhj,隐层的阈值θ,隐层与输出层之间的连接权值vih,输出层的阈值rh。这里假设输出层的节点个数为l个,隐层的节点个数为
假设隐层与输出层的激活函数均为sigmoid函数,该网络的输出为Yˆ=(yˆ1,...,yˆj,...,yˆl),那么其第j个节点的输入为
这里我们将隐层第h个节点与输出层第
我们可以看到,对于标准BP算法,其每输入一个样本值的时候,就会对参数进行一次更新,当我们的样本量非常大的时候,这种学习方式会耗费大量的时间成本,速度非常的慢,而且对不同的样本进行更新的时候很可能会出现效果抵消的问题。那么我们想如果可以将所有的样本都输入一次后,再对参数进行更新,即将所有的样本的误差都计算一遍,并将这些误差累积,依据累积的误差来对参数进行更新,这样就会快很多。这种方法是可行的,以这种思想为基础的BP算法称为累积BP算法。累积BP算法的更新频率会低很多,但是该算法在下降到一定程度之后,其再下降的速度就会慢很多。因此对于大部分的算法,其都是首先使用累积梯度下降更新参数,在下降到一定程度之后,再用标准BP算法进行更新。
但是使用BP算法,常常会遇到过拟合的问题,对于过拟合问题,通常采用早停和正则化的两种方式来缓解。其中早停方法比较简单,其就是讲数据集分为训练集和验证集两部分,当训练集的误差降低但验证集的误差升高的时候,就结束训练。而正则化方法则是在计算误差的时候加上一个正则项μ,该正则项用于衡量模型的复杂度,如下所示:
梯度发散问题
通过上面我们对梯度变化量的分析可以看到δωhj=ηyˆj(1−yˆj)(yˆj−yj)bh,同理可知,
注:图片均来自周志华老师的机器学习书的第五章神经网络,如有侵权,请联系我删除,谢谢。

















 1320
1320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









