







这篇博客在上一篇的基础上,继续深入学习爬虫的技巧。上一篇博客中通过从网页上抓取一张简单的图片简单了解了urllib.request中的模块的用法,今天在学习一个有道词典的例子。
这个例子主要是实现我们在Python中实现有道词典的功能,还是通过抓取有道词典的翻译的核心代码来实现。
首先我们先打开有道词典的网页来踩踩点。
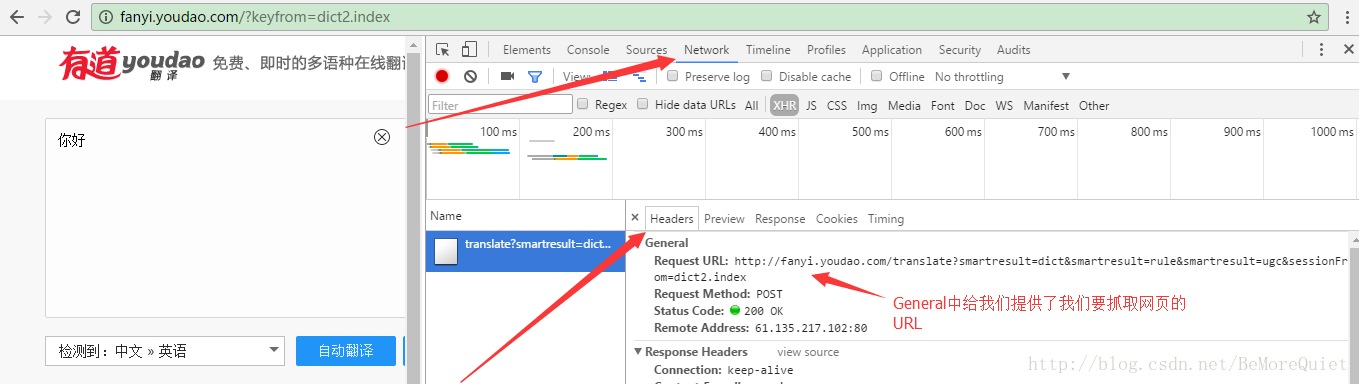
有了url之后还不行,我们这次不是抓取图片,而是要向网页中发送数据,所以要找到网页提交的表单。
继续往下看,便找到了我们的表单数据
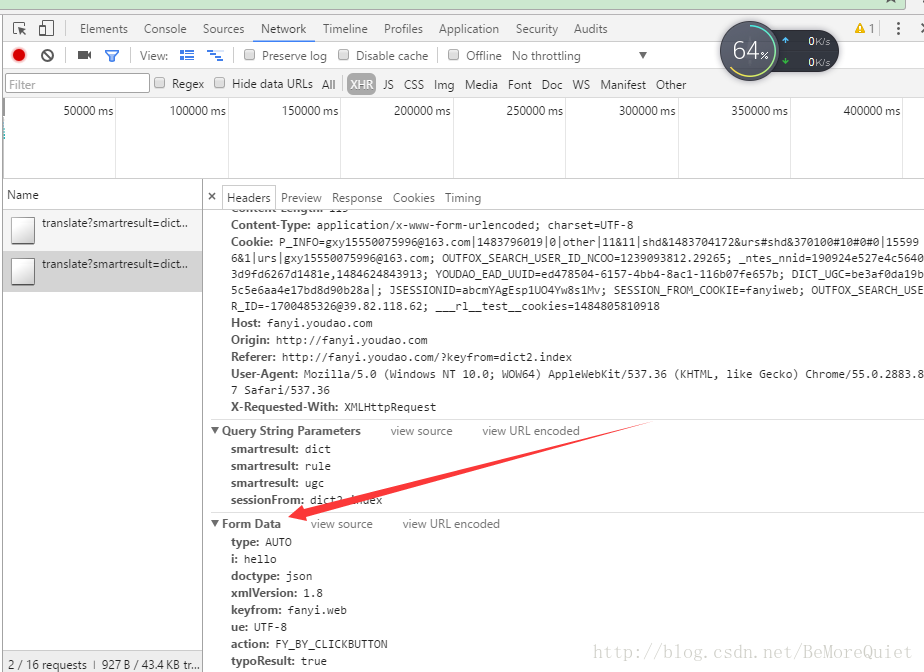
这样之后,我们的踩点工才完成了,下面开始代码的编写。在编写代码之前,我们再说一下urlopen这个函数:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 299
299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









