







软件开发中常用的缓存算法主要有:FIFO-先进先出算法,LRU-最近最久未使用,LFU-最近最少使用。实际项目中缓存算法对这些都有涉及。
一、理论:
1.FIFO(First Input First Output):
特点:先进先出,符合公平性,实现简单。
数据结构:使用对列
淘汰原则:如果一个数据最先进入缓存中,则应该最早淘汰掉。也就是说,当缓存满的时候,应当把最先进入缓存的数据给淘汰掉。
2.LRU(Least Recently Used):
特点:按照时间长短,最不经常使用的缓存数据,先淘汰。
数据结构:链表和hashmap
淘汰原则:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。
3.LFU(Least Frequently Used):
特点:按照访问次数,最近最少使用的缓存数据,先淘汰。
数据结构:数组、hashmap、堆
淘汰原则:如果一个数据在最近一段时间内使用次数很少,那么在将来一段时间内被使用的可能性也很小。
二、实际项目中使用(java项目为例):
1.ehcache框架:
Ehcache配置参数(具体参数含义请查找资料):
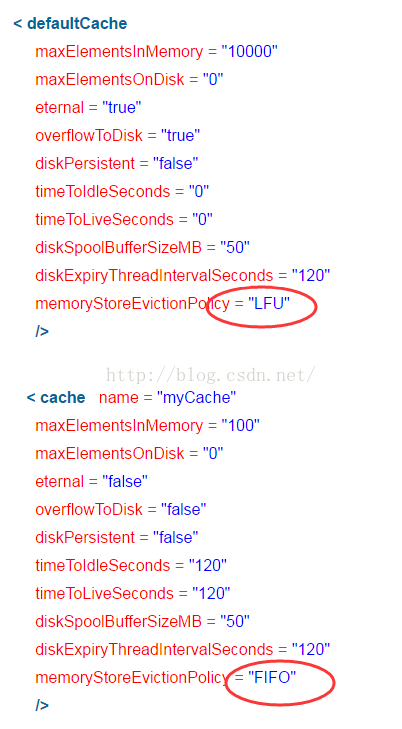
缓存的3 种清空策略 :
FIFO :first in first out (先进先出).LFU : Least Frequently Used (最不经常使用).意思是一直以来最少被使用的。缓存的元素有一个hit 属性,hit 值最小的将会被清出缓存。
LRU :Least Recently Used(最近最少使用). (ehcache 默认值).缓存的元素有一个时间戳,当缓存容量满了,而又需要腾出地方来缓存新的元素的时候,那么现有缓存元素中时间戳离当前时间最远的元素将被清出缓存。
2.Redis缓存回收策略配置:

(一)、最大缓存设置
示例:maxmemory 15000mb单位:mb,gb。
默认为0,没有指定最大缓存,如果有新的数据添加,超过最大内存,则会使redis崩溃,所以一点要设置。
设置maxmemory之后,配合的要设置缓存数据回收策略。
(二)、回收策略算法设置
当maxmemory限制到达的时候,Redis将采取的准确行为是由maxmemory-policy配置指令配置的。以下策略可用:
(1)、noeviction:当到达内存限制时返回错误。当客户端尝试执行命令时会导致更多内存占用(大多数写命令,除了DEL和一些例外)。
(2)、allkeys-lru:回收最近最少使用(LRU)的键,为新数据腾出空间。
(3)、volatile-lru:回收最近最少使用(LRU)的键,但是只回收有设置过期的键,为新数据腾出空间。
(4)、allkeys-random:回收随机的键,为新数据腾出空间。
(5)、volatile-random:回收随机的键,但是只回收有设置过期的键,为新数据腾出空间。
(6)、volatile-ttl:回收有设置过期的键,尝试先回收离TTL最短时间的键,为新数据腾出空间。
使用策略规则:
(1)、如果数据呈现幂律分布,也就是一部分数据访问频率高,一部分数据访问频率低,则使用allkeys-lru。
(2)、如果数据呈现平等分布,也就是所有的数据访问频率都相同,则使用allkeys-random。
redis回收算法,实际不是严谨的LRU算法,而是抽样回收数据,这样算是为了减少消耗内存使用,但是抽样回收的缓存和全部数据回收缓存差异非常小,或者根本就没有。
(三)、生产使用
(1)、先预测好系统所需要的内存高峰,部署相对应内存的缓存服务器。(2)、设置maxmemory和相对应的回收策略算法,设置最好为物理内存的3/4,或者比例更小,因为redis复制数据等其他服务时,也是需要缓存的。以防缓存数据过大致使redis崩溃,造成系统出错不可用。牺牲一部分缓存数据,保存整体系统可用性。
3.Memcached缓存策略:
(一).memcached缓存原理:
Memcached有两个核心组件组成:服务端(ms)和客户端(mc)。首先mc拿到ms列表,并对key做hash转化,根据hash值确定kv对所存的ms
位置。然后在一个memcached的查询中,mc先通过计算key的hash值来确定kv对所处在的ms位置。当ms确定后,客户端就会发送一个查询请求
给对应的ms,让它来查找确切的数据。因为ms之间并没有护卫备份,也就不需要互相通信,所以效率较高。

(二)、缓存策略:
Memcached会优先使用已超时的记录空间,但即使如此,也会发生追加新纪录时空间不足的情况。此时就要使用名为Least Recently Used (LRU)机制来分配空间。这就是删除最少使用的记录的机制。因此当memcached的内存空间不足时获取到新空间时,就从最近未使用的记录中搜索,并将空间分配给新的记录。
(三)、客户端代码示例:
spring集成memcache示例:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="memcachedPool" class="com.danga.MemCached.SockIOPool"
factory-method="getInstance" init-method="initialize">
<constructor-arg>
<value>neeaMemcachedPool</value>
</constructor-arg>
<property name="servers">
<list>
<value>127.0.0.1:11211</value>
</list>
</property>
<property name="initConn">
<value>20</value>
</property>
<property name="minConn">
<value>10</value>
</property>
<property name="maxConn">
<value>50</value>
</property>
<property name="nagle">
<value>false</value>
</property>
<property name="socketTO">
<value>3000</value>
</property>
</bean>
<bean id="memcachedClient" class="com.danga.MemCached.MemCachedClient">
<constructor-arg>
<value>neeaMemcachedPool</value>
</constructor-arg>
</bean>
</beans>测试用例:
public class MemcachedSpringTest {
private MemCachedClient cachedClient;
@Before
public void init() {
ApplicationContext context = new ClassPathXmlApplicationContext("com/luo/config/beans.xml");
cachedClient = (MemCachedClient)context.getBean("memcachedClient");
}
@Test
public void testMemcachedSpring() {
UserBean user = new UserBean("luo", "hi");
cachedClient.set("user", user);
UserBean cachedBean = (UserBean)user;
Assert.assertEquals(user, cachedBean);
}
} 注意点:
memcached是在服务器端的内存中缓存对象的,没有持久化到硬盘,是一个纯内存式的分布式缓存服务系统;















 1326
1326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









