









在Python中,对文本文件进行操作时,一不小心就会遇到编码问题
出错示例:
1.UnicodeEncodeError: ‘gbk’ codec can’t encode character.
2.UnicodeEncodeError: ‘gb2312’ codec can’t encode character.
3.UnicodeEncodeError: ‘UTF-8’ codec can’t encode character
为了避免再遇到此类问题,现在来探究下gb2312,gbk与gb18030间的关系
基础知识:
1. 编码集关系: gb2312﹤gbk﹤gb18030
2. gb2312字符: 哈哈哈我去你大爷的
3. gbk字符: 妳爺愛情國家
4. gb18030字符: āōáóǎēǒǎɑ
结论一
在Windows中,以gb2312 gbk gb18030编码存储的文件,会被映射到gb2312
就是说, 以gbk/gb2312保存的文本,程序读取该文本时, 仍会认为编码是gb2312
验证:
编写程序, 依次创建gb2312 gbk gb18030 utf-8编码的文本, 然后尝试依次写入gb2312字符 gbk字符 gb18030字符, 最后依次检测其编码
import chardet
# 创建各种编码文本
for encoding in ['gb2312', 'gbk', 'gb18030', 'utf-8']:
txtName = '测试'+encoding+'.txt'
with open(txtName, 'w', encoding=encoding) as text:
try:
text.write('哈哈哈我去你大爷的')
except:
print(encoding+'无法写入 哈哈哈我去你大爷的')
try:
text.write('妳爺愛情國家')
except:
print(encoding+'无法写入 妳爺愛情國家')
try:
text.write('āōáóǎēǒǎɑ')
except:
print(encoding+'无法写入 āōáóǎēǒǎɑ')
print()
# 检测其编码
for encoding in ['gb2312', 'gbk', 'gb18030', 'utf-8']:
txtName = '测试'+encoding+'.txt'
with open(txtName, 'rb') as test:
content = test.read()
encoding = chardet.detect(content)
print(txtName+'检测结果: ')
print('编码: {},可信度: {}\n'.format(encoding['encoding'], encoding['confidence']))结果:

查看文本:
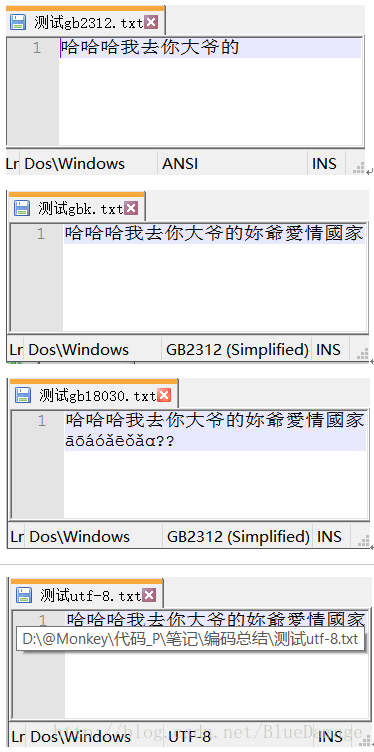
gb2312仅能保存gb2312的文字
chardet检测结果: gb2312
notepad++显示结果: ANSI(GBK)
gbk 可以保存gb2312及gbk的文字
chardet检测结果: gb2312
notepad++显示结果: gb2312
gb18030可以保存gb2312,gbk及gb18030的文字
chardet检测结果: gb2312
notepad++显示结果: gb2312
utf-8 可以保存所有编码的文字
chardet检测结果: utf-8
notepad++显示结果: utf-8
总结
gbk和gb18030都被映射到了gb2312
结论二
在程序中应以文本中字符最大的编码集打开该文本,否则会造成乱码/打开失败.
验证:
编写程序, 依次创建gb2312gbk gb18030 utf-8编码的文本, 然后尝试依次写入gb2312字符 gbk字符 gb18030字符, 最后依次检测其编码
import chardet
# 遍历四个测试文本
for c in ['gb2312', 'gbk', 'gb18030', 'utf-8']:
textName = '测试'+c+'.txt'
print('\n测试文本: '+textName)
with open(textName, 'rb') as test:
content = test.read()
encoding = chardet.detect(content)
print('\t猜测: 编码-{},可信度-{}'.format(encoding['encoding'], encoding['confidence']))
# 依次以4种编码去打开文本
for encoding in ['gb2312', 'gbk', 'gb18030', 'utf-8']:
with open(textName, 'r', encoding=encoding) as test:
try:
content = test.read()
print('\t成功: {}'.format(encoding))
print('\t内容: '+content)
except:
print('\t失败: {}'.format(encoding))
print('\t内容: ')结果:

总结:
- 仅含有gb2312,可用gb2312, gbk和gb18030打开
- 含有gb2312和gbk,可用gbk和gb18030打开
- 含有gb2312, gbk和gb18030,仅能用gb18030打开
- gb编码文本不能用utf-8打开, utf-8编码文本不能用gb编码文本打开














 1035
1035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









