







第一步:下载解压
http://mirror.bit.edu.cn/apache/zookeeper/
下载拷贝到linux系统其中一台机器(master),执行解压
tar-zxvf zookeeper-3.4.6.tar.gz
第二步:修改zookeeper配置文件
修改配置文件conf/zoo.cfg,内容如下所示:
ticktime=2000
datadir=/opt/Java/zookeeper-3.4.6/data/zookeeper
clientport=2181
initlimit=5
synclimit=2
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
server.4=slave3:2888:3888
第三步:远程复制分发安装文件
上面已经在一台机器master上配置完成zookeeper,现在可以将该配置好的安装文件远程拷贝到集群中的各个结点对应的目录下:
cd /opt/Java/
scp -r zookeeper-3.4.6/hadoop@slave1:/opt/Java/
scp -r zookeeper-3.4.6/hadoop@slave2:/opt/Java/
scp -r zookeeper-3.4.6/hadoop@slave3:/opt/Java/
第四步:设置myid及环境变量
在我们配置的datadir指定的目录下面,创建一个myid文件,里面内容为一个数字,用来标识当前主机,conf/zoo.cfg文件中配置的server.x中x为什么数字,则myid文件中就输入这个数字,例如:
hadoop@master$ echo "1" > /opt/Java/zookeeper-3.4.6/data/zookeeper/myid
hadoop@slave1$ echo "2" > /opt/Java/zookeeper-3.4.6/data/zookeeper/myid
hadoop@slave2$ echo "3" > /opt/Java/zookeeper-3.4.6/data/zookeeper/myid
hadoop@slave3$ echo "4" > /opt/Java/zookeeper-3.4.6/data/zookeeper/myid
在每台机器配置zookeeper环境变量:
exportZOOKEEPER_HOME=/opt/Java/zookeeper-3.4.6
exportPATH=$PATH:$ZOOKEEPER_HOME/bin
按照上述进行配置即可。
第五步:启动zookeeper集群
在zookeeper集群的每个结点上,启动zookeeper:
hadoop@master$: zkserver.sh start
hadoop@slave1$: zkserver.sh start
hadoop@slave2$: zkserver.sh start
hadoop@slave3$: zkserver.sh start
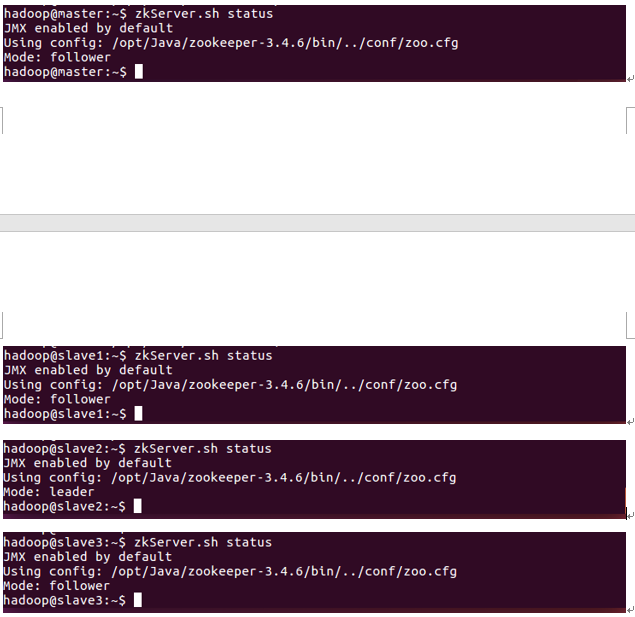
第六步:安装验证
可以通过zookeeper的脚本来查看启动状态,包括集群中各个结点的角色(或是leader,或是follower),如下所示,是在zookeeper集群中的每个结点上查询的结果:














 5111
5111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









