







HBase的Compaction操作一般都是表粒度的,该操作会将合并HStore下的storefile文件,具体应该合并哪些storefile文件则是由compaction的筛选算法决定的。
解析compact源码时可以看到待合并的文件集合是包装在CompactContext中,compact请求会包装成requestCompact,经层层调用后,在CompactSplitThread的requestCompactionInternal中完成compactContext的构造并提交线程池去执行。
从requestCompactionInternal中开始跟读代码,可以看到CompactionContext的构造以HStore为粒度,在HStore的requestCompaction中完成,把与compact文件筛选相关的逻辑列出如下:
public CompactionContext requestCompaction(int priority, CompactionRequest baseRequest)
throws IOException {
CompactionContext compacion = storeEngine.createCompaction();
CompactionRequest request = null;
this.lock.readLock().lock();
try {
synchronized (filesCompacting) {
//处理coprocessor;
if (!compaction.hasSelection()) {
try {
compaction.select(this.filesCompacting, isUserCompaction, mayUseOffPeak
forceMajor && filesCompacting.isEmpty());
} catch (IOException e) {
.......
}
}
request = compaction.getRequest();
final Collection<StoreFile> selectedFiles = request.getFiles();
if (selectedFiles.isEmpty()) {
return null;
}
addToCompactingFiles(selectedFiles);
} finally {
this.lock.readLock().unlock();
}
}
return compaction;
}介绍这两个算法前,首先说明每个storefile文件中都定义了一个sequence id,用于标识该文件的“新旧”,越新创建出来的storefile,其sequence id值越大,反之亦然。
所谓的compaction筛选算法可以建模为以下的一个问题:
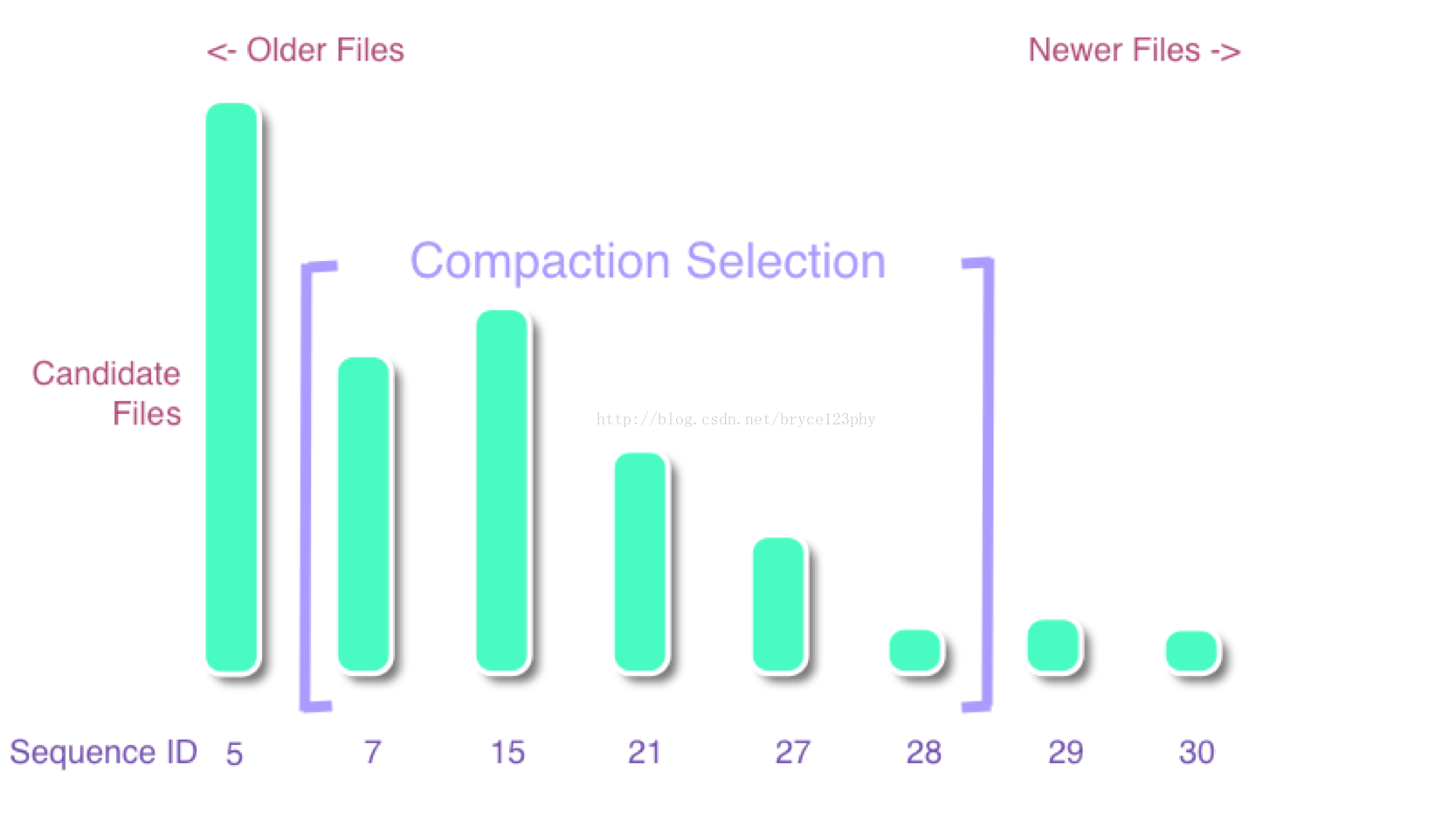
图中的每个数字表示了文件的sequence id,数字越大,则文件越新,很有可能刚刚flush而成,意味着文件size也可能越小。这样的文件是compact时优先选择,因此store下的storefile文件会依据sequence从小到大排序,依次标记为f[0]、f[1]。。。。f[n-1],筛选策略就是要确定一个连续范围[start, end]内的storefile
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









