







我们一起来讨论讨论java内存模型。理解内存模型对多线程编程无疑是有好处的。
本文包括以下几个部分:
java代码是如何跑起来的
java代码如何运行
我们写的java代码,自己看得懂,然而虚拟机是看不懂的,更不用说直接在机器上跑起来了。要让java代码按照我们的意图跑起来的话,需要以下几个过程。

java代码会经过javac编译器编译,转化成class文件,也就是常说的字节码。然后再经过jvm把字节码转化成机器可以识别的机器码,才能跑起来。
为什么要转化为字节码,而不是直接转化为机器码呢?这是为了实现跨平台,同一份机器码,在不同cpu架构的机器上跑,出来的结果可能大相径庭。如果直接转化成机器码,那么可能程序在x86的机器上跑是正常的,但是在x64的机器上确出现了很诡异的结果。
而字节码,是可以被java虚拟机所识别的。众所周知,java跨平台的原因,就在于java虚拟机在这其中起到的作用。虚拟机作为一个中间桥梁,把字节码转化为可以在特定机器上执行的二进制机器码。
虚拟机的解释器和编译器
那么,虚拟机是怎么把字节码转化成机器码的呢?主流的虚拟机,一般都有两种方法来做。
- 解释器
- 编译器
需要注意的是,这里的编译器和前面提到的javac编译器不同,稍候会进一步说明。
第一种是解释器,解释执行。字节码被一行一行的翻译成机器码,然后直接在机器上执行。
第二种是编译器,以方法为单位,把方法编译成机器可以识别的机器码,然后执行。
二者有什么不同呢?
1.解释器以行为单位,解释完就直接执行,速度更快。编译器以方法为单位进行编译,速度相对解释器要慢。
2.解释器解释完字节码,转化成的机器码,并没有保留下来。而编译器把方法转化成机器码后,会缓存下来。后面如果再次需要使用到,直接拿之前编译好的机器码即可。
这里的编译器是JIT(Just-In-Time)即时编译器,和前面的javac编译器有以下几点不同。
1.javac的输入是java源代码,输出是class文件,即字节码。JIT的输入是字节码,输出是机器可以执行的二进制机器码。
2.javac是静态编译器,而JIT是动态编译器,JIT在程序运行的时候动态编译
3.编译范围不一样。javac把所有的java代码直接编译成字节码,而JIT只编译一部分的字节码,并非把所有的字节码都转化成机器码。
为什么需要JIT
可能有同学会有疑问,既然有了解释器,为什么还要整一个JIT编译器呢。直接像js引擎一样,解释执行js不可以吗?是可以,但是有了JIT会更好。
解释器有1个不足:解释器解释字节码得到的机器码没有缓存,如果一个同样的方法被调用了很多次,那么意味着同样的字节码要被重复解释很多次,这一点无疑会降低运行的效率。
既然如此,那直接把解释器解释的所有机器码都缓存下来,不就得了吗。但是如果一个程序特别庞大,这样做无疑非常浪费资源。所以,我们需要JIT来配合解释器。JIT可以把常用的字节码,编译成机器码,并缓存下来,以后再调用时,直接使用缓存的机器码,提高运行效率。
当然,JIT也有缺点。因为JIT编译字节码以方法为单位,同时还会做一些优化,速度比解释器的解释要慢,所以,如果所有的字节码都先经过JIT编译以后,再执行,那么程序启动会变得很慢。
所以,解释器和JIT一般都是并存的。启动的字节码一般都由解释器来解释执行,确保启动速度。JIT对一些常用的代码编译优化并缓存,提供程序运行效率。
JIT编译什么
上面说JIT把常用的字节码编译成机器码,如何来判断常用字节码。
基于计数器的热点探测
JIT编译是以方法为单位的。每个方法都会关联一个计数器,当方法被调用时,计数器会加1。当一个方法的调用次数达到一定的阈值时,我们认为这个方法是一个常用的方法,我们需要去编译它,以免多次重复解释执行降低效率。
这种方法的优点是统计精确,能够动态且精准知道,哪些方法是常用的。缺点是,每个方法都需要关联计数器,开销较大。
基于采样的热点探测
这种方法会确定一个采样周期,每个周期都会检测在调用栈的栈顶是哪个方法在被调用,并记录下来。然后统计出常用的方法。
这种方法,相较于基于计数器的热点探测,优点在于开销小,不需要给每个方法都关联一个计数器。但是缺点在于统计并不精确,有时候还可能误统计,比如线程被阻塞了,几个周期内检测到的栈顶方法都是同一个方法,但很显然,这个方法只是因为被阻塞了,而不一定是常用的方法。
为什么多线程的代码可能出现诡异的结果
如果我们的多线程代码,没有正确使用各种同步或者并行的语义,很有可能会出现各种意想不到的结果。更有甚者,即使当前的代码在这台机器上跑出了预期的结果,当放在另一台机器上运行时,却发现结果完全不是自己想要的了。这样的事情时有发生,让人怀疑人生有木有!
多线程产生不可预期的结果,其实基本都是因为编译器和处理器对代码进行优化而产生的副作用。优化自然是为了提高性能,但有可能优化过了头。我们一起来看看几种导致多线程意外结果的原因。先说明下,既然本文探讨的是java内存模型,自然这里的多线程也是指的java版的多线程。
呀,还有一点很重要,需要先给个大前提。不论是编译器,还是处理器,优化代码逻辑,都有一个原则:
必须不能改变单线程环境下的语义
这是优化的底线,先了解这一点有助于我们理解下面的几种优化,为什么是允许的。
指令重排
jvm可能会重排我们的代码逻辑,以jvm认为这不会影响正确的结果为前提,并且以提高性能为目标。
然而这恰恰可能导致多线程环境下,产生超出预期的结果。
一起来看看下面这个例子。
class Reordering {
int foo = 0;
int bar = 0;
void method() {
foo += 1;
bar += 1;
foo += 2;
}
}假如现在有两个线程和一个Reordering对象,线程1调用了这个Reordering对象的method方法,而线程2在观察这个Reordering对象的foo变量和bar变量的值。两个线程同时跑了起来。
直观上,线程2看到的变量情况,应该会有4种可能。

- 当线程2在程序点1的地方观察,应该得到
foo=0,bar=0 - 当线程2在程序点2的地方观察,应该得到
foo=1,bar=0 - 当线程2在程序点3的地方观察,应该得到
foo=1,bar=1 - 当线程2在程序点4的地方观察,应该得到
foo=3,bar=1
我们预期会有上面4种情况发生。但实际跑的时候,却发现出现了foo=3, bar=0 的情况。
这就尴尬了,理论上,bar+=1 是先于foo+=2 的,而foo=3 只能是经过foo += 2 之后才会得到,也就是说, 当foo=3 的时候,bar += 1 已经执行过了,那么为什么当 foo=3 的时候, bar=0 呢?
问题就处在了jvm和处理器对指令的优化上,这里的优化具体来说,是指令重排。
方法method()里面的3条语句都是形如 变量 += 常量 ,我们以 foo += 1 来看下cpu是如何处理这条语句的。
在此之前,我们需要先了解下cpu的cache。
学过计算机组成原理的同学应该知道,cpu访问内存需要经过总线传递数据,速度较慢,cpu如果每次存取数据都要和内存交互,无疑会降低cpu的运转效率。cpu访问寄存器的速度是非常快的,但是又不可能只依赖于寄存器,因为寄存器的空间太小了。
因此,每块cpu芯片上都设置了缓存cache,访问cache的速度要高于访问内存的速度,因此,如果我们需要取内存中的数据,可以先加载到cache中,如果做了相应的修改,再把新的数据同步回内存。具体的缓存命中(cache hit)和缓存未命中(cache miss)不是本文的重点,有兴趣的同学自己了解下~
言归正传。我们来看下foo += 1 是如何被cpu执行的(这里不涉及具体的cpu指令,只是一种容易理解的方式来说明)。
分三步走。
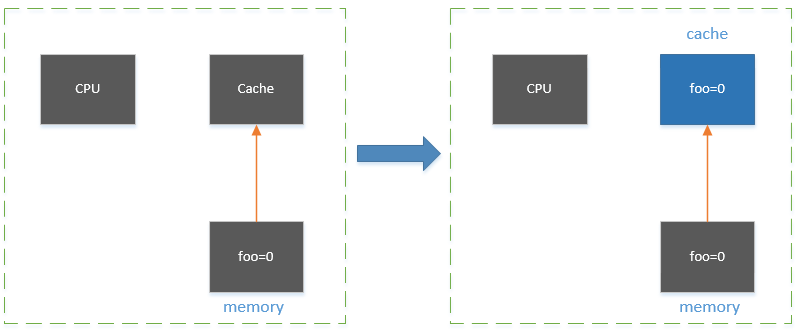
首先从内存中取foo变量加载到cache。
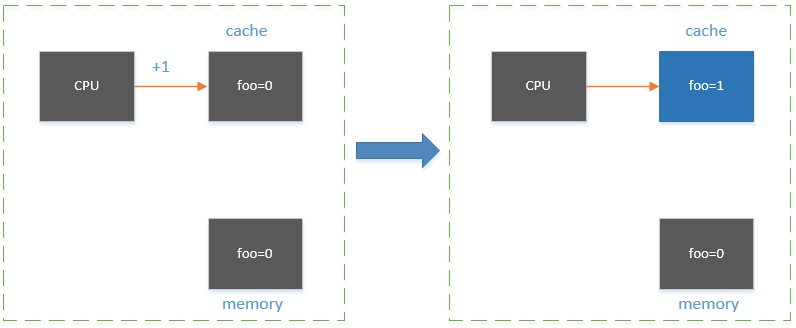
然后,cpu取cache中的foo,并执行加1的操作。此时cache中的foo的值是1,而内存中的foo的值还是0。
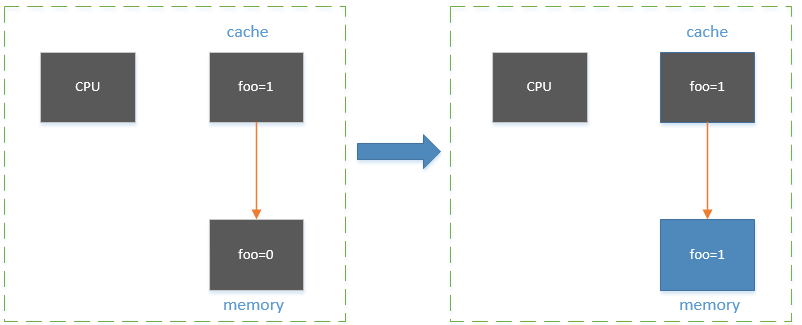
最后,cache把foo=1 同步回到内存中。至此,foo += 1 就算完成了。
所以,方法method()执行,理论上是需要9步操作的。
foo += 1
- cpu加载foo到cache
- cache的foo加1
- cache的foo同步到内存
bar += 1
- cpu加载bar到cache
- cache的bar加1
- cache的bar同步到内存
foo += 2
- cpu加载foo到cache
- cache的foo加2
- cache的foo同步到内存
小伙伴可能会发现,foo被加载到cache中发生了2次,被同步到内存也发生了2次,如果把foo += 1 和foo += 2 放在一起处理,可以减少加载和同步的次数。
- cpu加载foo到cache
- cache的foo加1
- cache的foo加2
- cache的foo同步到内存
此时,代码逻辑就变成了
void method {
foo += 1;
foo += 2;
bar += 1;
}事实上,jvm和cpu就是这么干的,甚至会把foo += 1 和foo +=2 合并到一起,
void method {
foo += 3;
bar += 1;
}乍一看,这似乎是对的,因为不论是原来的代码顺序,还是指令重排后,二者的结果都是 foo=3 bar=1。单线程环境下的确如此。但是多线程就不一样了。

当另一个线程在上图的程序点试图去读取foo和bar的值时,发现bar=0 的时候,出现了foo=3 的情况,如我们前面提到的,这个结果不在我们的预期之内。
这说明,单线程下正确的语义,不代表多线程环境下也是正确的
去掉无效的语句
看下面这段程序
class Caching {
boolean flag = true;
int count = 0;
void thread1() {
while (flag) {
count++;
}
}
void thread2() {
flag = false;
}
}假设现在有2个线程,线程1执行thread1方法,线程2执行thread2方法。
我们来纸上谈谈兵。
线程1会不断轮询flag的值,flag初始化为true,所以count会不断自增。
线程2把flag改成false。
线程1发现flag变成了false,退出循环。
实际情况呢?
jvm在thread1执行过程中,发现在该执行路径中(thread1()),并没有任何修改flag的地方。所以,JIT把这段代码优化了一下
void thread1() {
while(true) {
count++;
}
}jvm在thread2执行过程中,发现在该执行路径中(thread2()),并没有任何读取flag的地方,所以,JIT把这段代码也优化了下
void thread2() {
// flag = false;
}你没看错,flag=false 被忽略了,因为在thread2方法里面,没有任何去读取flag的地方,所以flag=false 在jvm看来是没有必要同步到内存的。
这就会导致thread1()不断的执行,从而和我们想要的效果不一样了。
不同的平台
在不同架构的机器上跑,也可能会出现难以解释的现象。
看下面一段程序
class Atomic {
long foo = 0L;
void thread1() {
foo = 0xFFFF0000;
}
void thread2() {
foo = 0x0000FFFF;
}
}同样,我们假设线程1调用thread1方法,线程2调用thread2方法。
理论上讲,如果线程1先执行,线程2后执行,那么foo = 0x0000FFFF, 如果线程2先执行,线程1后执行,那么foo = 0xFFFF0000 。
如果是在64位的机器上,这个结论是正确的。
但如果是32位的机器,就不一定了。有可能出现0x00000000,也可能出现0xFFFFFFFF。
我们以出现0xFFFFFFFF的结果为例子讨论。
在32位的机器上,cpu存取一个数据是以32位为单位取的。foo是一个64位的变量,会被分成两次存取。
如前面所说,cpu会先从内存中取数据到cache,然后cache设置变量的值,最后再把值同步回内存。
当同步值到内存中时,因为是分两次同步,所以线程1和线程2可能下面的情形。
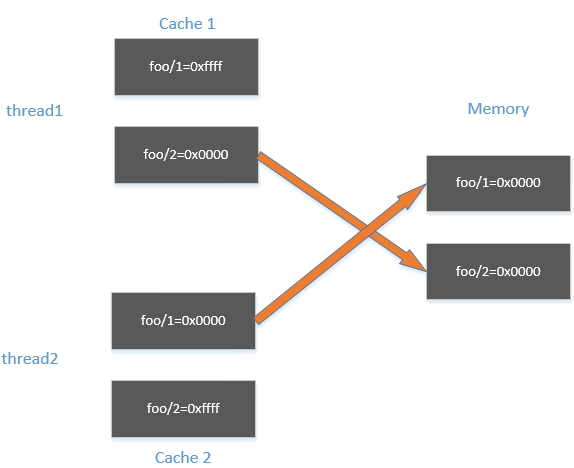
thread1把foo的低32位同步回内存,thread2把foo的高32位同步回内存,此时内存的值是0x00000000
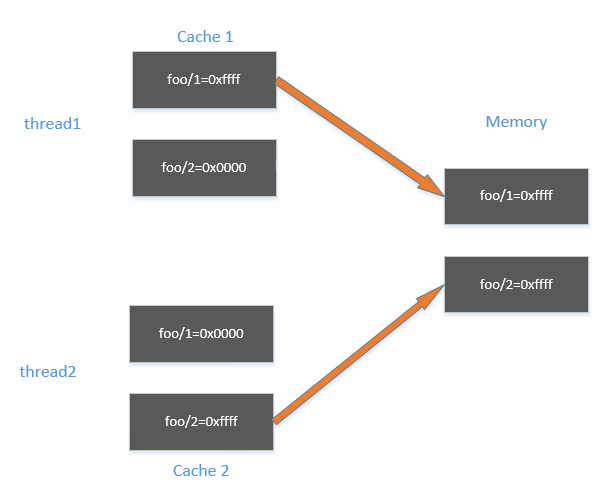
然后,thread1把foo的高32位同步回内存,thread2把foo的低32位同步回内存,此时就出现了内存中foo=0xffffffff 的情况了。
下面来总结下不同平台对于指令乱序的容忍度。如果大家以后出现一个程序在一种cpu架构的机器上跑是正常的,但是在另外一种cpu架构的机器上跑出现了奇怪的结果,可以考虑是否是因为这方面引起的原因。
http://dreamrunner.org/blog/2014/06/28/qian-tan-memory-reordering/#memory-ordering-at-processor-time
| . | ARM | POWERPC | SPARC TSO | X86 | AMD64 |
|---|---|---|---|---|---|
| load-load | yes | yes | no | no | no |
| load-store | yes | yes | no | no | no |
| store-store | yes | yes | no | no | no |
| store-load | yes | yes | yes | yes | yes |
和内存交互的指令可以分为两大类,load指令(也就是从内存读取),store指令(也就是写入内存),所以,两条指令的顺序一共有4种可能:
- load-load,前一条是读取指令,后一条也是读取指令
- load-store,前一条是读取指令,后一条是写入指令
- store-store,前一条是写入指令,后一条也是写入指令
- store-load,前一条是写入指令,后一条是读取指令
需要注意,这里的指令顺序,指的是在同一个线程中的指令顺序,而不是两个或者多个不同线程的指令顺序。怎么理解呢?想一下,处理器重排指令顺序,就是为了让cpu可以更高效地处理,而cpu不可能同时处理两个或多个线程,每个线程同时运行,其实是由不同的cpu来处理。
上表中的load-load,load-store,store-store,store-load,指的是指令原来的顺序,yes表示在对应的cpu架构上,允许重排指令,no表示。
以load-load为例,假如有两个指令如下
load a
load b那么,在ARM和POWERPC处理器上,有可能出现指令重排,变成
load b
load a而SPARC TSO,X86,AMD64的处理器都不允许load-load重排。
从严格度来讲,ARM和POWERPC是最宽松的,四种指令顺序,都允许重排指令来优化性能。而SPARC TSO,X86,AMD64都比较严格,仅仅在store-load的指令顺序下,才允许处理器重排指令以优化性能。
所以,有时候会出现这样一种情况,我们的程序在x86的机器上跑的好好的,拿到ARM上面跑就莫名其妙了,很有可能就是ARM做了过度的优化导致的。
为什么ARM和POWERPC,相比于其他架构,做了更多可能的优化呢?其实这和市场定位有很大的关系,比如ARM,主要应用在手机和PDA等设备,而X86则更多应用在PC上,这使得二者的定位截然不同,其中非常重要的一点考量就是耗电量。手机之于PC,前者使用的时候一般是不插电,而PC则一般是插电使用,这使得ARM必须更多考虑如何省电,而对程序做更多的优化,很重要的原因就是提高性能,降低功耗。
java内存模型
了解了多线程出现data race的各种可能原因后,下面开始引入java内存模型
一句话概括
什么是java内存模型,通俗的说,就是(我的个人理解,如果有误,请大家一定指出)
java内存模型是一个规范,如果jvm是一个遵循了java内存模型的实现,并且我们的程序也正确使用了各种同步机制,那么多线程环境下,我们从内存中读取一个变量,其值是确定的。
每个处理器上的写缓冲区,仅仅对它的处理器可见。对其他的处理器不可见。
模型简介
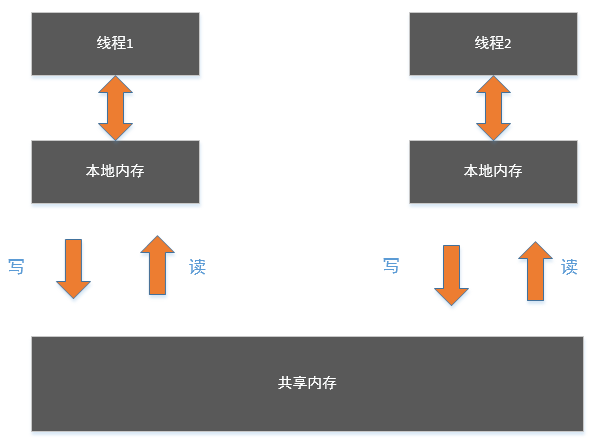
在java内存模型中,内存被分成了2种类型。
- 本地内存:每个线程都有一个本地内存,存储线程需要操作的一些数据。
- 共享内存:不同的线程之间共享主内存(也可以叫共享内存,更直观一点)。
线程之间不能互相访问各自的本地内存,即线程1不能访问线程2的本地内存,线程2也不能访问线程1的本地内存。
线程之间要通信,只能通过共享内存来传递消息。比如线程1要发消息给线程2,必须先把消息写入到共享内存,然后线程2到共享内存取出消息。
这里的内存模型只是一个抽象的概念,并非对应了真正的物理内存。但是真正内存上的存取是符合这个模型的。比如处理器的cache就可以比作是本地内存,而物理内存就可以看做多个cpu执行多线程时的共享内存。
内存屏障
之前提到因为编译器和处理器可能做的各种优化,而导致多线程语义出现不可预期,为了解决这个问题,java内存模型提出了4种内存屏障。
load-load barrier
load-store barrier
store-store barrier
store-load barrier
load-load barrier :
sequence: Load 1 load-load-barrier Load2
ensures that Load1’s data are loaded before data accessed by Load2 and all subsequent load instructions are loaded.
load-load可以确保程序语义不被重排序,比如下面的例子
System.out.print(a);
/** load-load barrier **/
System.out.print(b);那么,一定能保证,编译器不会对这两条语句进行重排。
load-store barrier:
sequence: Load 1 load-store-barrier Load 2
ensures that Load1’s data are loaded before all data associated with Store2 and subsequent store instructions are flushed.
load-store可以确保程序语义不被重排序,比如下面的例子
System.out.print(a);
/** load-store barrier **/
b = 1;那么,一定能保证,编译器不会对这两条语句进行重排。
store-store barrier
sequence: Load1 store-store-barrier Load2
ensures that Store1’s data are visible to other processors (i.e., flushed to memory) before the data associated with Store2 and all subsequent store instructions.
store-store稍有不同。它有两个方面的作用。
第一,store-store一样可以确保程序语义不被重排,比如下面的例子
a = 1;
/** store-store barrier **/
b = 2;那么,一定能保证,编译器不会对这两条语句进行重排。
store-store的另一个功能是,前者的store一定能对其他线程可见。
换句话将,当执行完a = 1,正常情况下,并不一定会马上同步到共享内存,因此,其他线程此时如果获取a的值,有可能还是旧的。但是store-store barrier可以确保,a=1执行完后会马上同步到共享内存,其他线程从共享内存获取的一定是新的值。
store-load barrier
sequence: Store1 store-store-barrier Store2
ensures that Store1’s data are made visible to other processors (i.e., flushed to main memory) before data accessed by Load2 and all subsequent load instructions are loaded. StoreLoad barriers protect against a subsequent load incorrectly using Store1’s data value rather than that from a more recent store to the same location performed by a different processor.
轮到store-load barrier,突然字就变多了,没错,store-load的确与众不同。
store-load比store-store还要强大。
首先,store-load一样可以确保程序的语义不被重排,比如下面的例子
a = 1;
/** store-load barrier **/
System.out.print(a);那么,一定能保证,编译器一定不会重排这两条语句。
store-load的第二个功能是,前者的写入操作会同步到共享内存,对其他线程马上可见。
也就是说,a = 1会马上同步到共享内存,其他的线程此时获取到的a一定是最新的值。
store-load的第三个功能是,在store-load屏障后面的读入,一定会从共享内存中去读取,而不是直接取本地内存的缓存。
这意味着,一旦插入了store-load屏障,那么屏障执行之后,线程会让自己的本地缓存失效,读取操作一定会到共享内存去取最新值。
对四种内存屏障做个小总结:
四种内存屏障都能够保证程序语义的正确,编译器不会重排逻辑
load-load和load-store只能保证程序语义正确,无法确保内存可见性。也就是说,load操作虽然执行了,但实际上可能取的是缓存的值,而不是重新到共享内存取。store操作虽然执行了 ,但实际上,可能还没有马上同步到共享内存中。
store-store和store-load都可以确保程序语义正确,也都可以确保屏障前的store操作能够马上同步到共享内存。但是store-store屏障后面的load操作,不能确保一定会都共享内存取最新值,可能还是读的缓存。而store-load屏障后面的load操作,一定能够确保是去共享内存取的最新值。
从性能的角度讲,store-load是最耗性能的,但是在确保正确性方面,store-load做的最好。
同步机制
这里我们介绍几种同步机制,这些是上层开发实际会用到的几种同步。
从修饰类型来看,可以分为3种:
修饰字段的同步机制
修饰方法的同步机制
修饰代码块
关于修饰字段的同步机制,我们一起来讨论下面二者
volatile
final
关于修饰方法和代码块的同步机制,我们来讨论
- synchronized
下面就开始吧~
volatile
看如下一个例子
class DataRace {
bool ready = false;
int foo = 0;
void thread1() {
while (!ready);
assert foo == 42;
}
void thread2() {
foo = 42;
ready = true;
}
}线程1调用thread1方法,线程2调用thread2方法。我们想要的结果是,当线程2把执行完ready = true后,线程1检测到ready为true了,然后检测foo == 42成功。
按道理应该是这样。因为foo = 42 在 ready = true前面,所以,当ready = true,foo == 42肯定成立。
在x86的机器上,这个说法说得通。但是在ARM上就有问题了。
还记得前面提到的不同平台的指令重排吗,ARM上允许store-store重排,所以,完全有可能ready = true,在foo = 42前面执行了。
然后当thread1检测到ready = true的时候,foo可能还没设置成42
| thread2 | thread1
| |
| ready = true |
| | while(!ready);
| | assert foo == 42; // fail
| foo = 42; | 如上图所示,assert foo == 42 的时候,foo = 42 还没执行导致assert fail。
如果ready变量用volatile修饰,就截然不同了。
class DataRace {
volatile boolean ready = false;
int foo = 0;
void thread1() {
while(!ready);
assert foo == 42;
}
void thread2() {
foo = 42;
ready = true;
}
}volatile修饰在成员变量上,能具有如下作用:
在volatile变量的写操作后面会插入一个store屏障,保证volatile的写操作会立即同步到共享内存,使其他线程对该写操作可见
在volatile变量的读操作前面会插入一个load屏障,保证volatile的读操作会从共享内存取最新的数据,而不是直接读取的缓存。
在volatile变量的写操作前面的程序语句不允许和volatile变量的写操作重排指令。
在volatile变量的读操作后面的程序语句不允许和volatile变量的读操作重排指令。
volatile变量写操作前面的写操作一定会在执行完store屏障前,同步到共享内存。
volatile变量读操作后面的读操作一定会从共享内存取最新数据。
从例子看,对volatile变量的写操作是ready = true ,对volatile变量的读操作是while(!ready) ,所以得出:
foo = 42会马上刷新到共享内存,对应第1条。在thread2执行了
foo=42后,thread1的while(!ready)会从共享内存取出最新的ready,对应第2条。foo = 42不允许和ready = true重排,对应第3条。while(!ready)不允许和assert foo == 42重排,对应第4条。foo = 42会在执行完store屏障前,更新最新值到共享内存,对应第5条。assert foo == 42会重新到共享内存取最新值,对应第6条。
所以,新的执行流程是
| thread2 | thread1
| |
| foo = 42; |
| ready = 1; |
|--------------------------------------------
| | while(!ready);
| | assert foo == 42; // success对了,还记得前面我们聊过,如果一个变量是64位的,在32位的机器上跑,有可能出现错误结果,原因是分成2个32位的分开存储导致的。如果用volatile来修饰,那么这种情况是不存在的。
但是这并不意味着,volatile具有原子性。比如
volatile int i =0;
i++;i++ 其实是分三步走的,先读取,再自增,最后写入。volatile不能保证这三步操作具有原子性,依然可能出现data race。volatile只保证读取是取最新值,写入能立即同步到共享内存。
synchronized
前面的例子,除了用volatile来解决,还可以synchronized修饰方法或者代码块。
class DataRace {
boolean ready = false;
int foo = 0;
synchronized void thread1() {
while(!ready) ;
assert foo == 42;
}
synchronized void thread2() {
foo = 42;
ready = true;
}
}synchronized是如何保证结果的正确性呢?
synchronized会被拆分成两个指令
<enter lock><exit lock>
<enter lock> 就是获取了锁,同一时刻,只能有一个线程能够获得lock。
<exit lock> 就是释放锁,拥有lock的线程只有在释放锁以后,其他线程才有机会获得锁。
也就是说,synchronized对应的锁是互斥锁。
当synchronzed修饰在非静态方法时,lock就是实例本身,即this ,所以可以写成这样
void thread1() {
<enter this>
while(!ready);
assert foo == 42;
<exit this>
}
void thread2() {
<enter this>
foo = 42;
ready = true;
<exit this>
}synchronzed可以保证以下几点:
同一时刻,只能有一个线程获取lock。
线程在获得lock后,所有的写入操作,会在释放lock前,全部同步到共享内存。
线程在获得lock后,所有的读取操作,都会从共享内存读取最新值,而不是从缓存直接获取。
第1条保证了线程1和线程2的代码不可能同时执行;
第2条保证了foo=42 和ready = true 都会在线程2释放lock之前,全部同步到共享内存,使得更新对线程1可见。
第3条保证了while(!ready) 和assert foo == 42 都会从共享内存获取最新值。
假设线程2先获得lock,如图
| thread2 | thread1
| |
| <enter this> |
| foo = 42; |
| ready = true; |
| <exit this> |
|---------------------------------------------
| | <enter this>
| | while(!ready);
| | assert foo == 42; // success
| | <exit this>注意,synchronized并不能保证在块内的语句不被重排。也就是说,thread2的foo = 42 和ready = true 可能重排,thread1的while(!ready) 和foo == 42 可能重排。
线程启动同步
来看下面的例子
class ThreadLife {
int foo = 0;
void thread1() {
foo = 42;
new Thread(new Runnable() {
public void run() {
assert foo == 42;
}
}).start();
}
}线程1会调用thread1方法,在里面会启动一个新的线程(假设为线程2),那么,线程2的foo == 42 是否一定能保证成功呢?
答案是肯定的。
线程1调用new Thread(runnable).start()启动线程2,线程2启动时会在一开始放入一个<start> 指令。并且有以下保证:
线程1的thread.start()方法一定在线程2的
<start>之前执行(否则怎么启动呢)。线程1的thread.start()方法前面的写入操作一定会同步到共享内存
线程2在启动时,会从共享内存中获取线程1的变量,拷贝到线程2的本地内存。
以上保证了线程2中的foo是共享内存中的最新值,如下
| thread1 | thread2
| |
| foo = 42; |
| thread.start() |
|-----------------------------------------
| | <start>
| | assert foo == 42; // successfinal关键字
其实,final也有自己的多线程语义的,这一点倒是让我感到有点意外。看下面的例子。
class UnsafePublication {
int foo;
UnsafePublication() {
foo = 42;
}
static UnsafePublication instance;
static void thread1() {
instance = new UnsafePublication();
}
static void thread2() {
if (instance != null) {
assert instance.foo == 42;
}
}
}这一段程序并没有用到final呀?这是一段有问题的程序。假设线程1调用thread1生成一个instance对象,线程2调用thread2(),判断如果instance非空,就assert instance.foo == 42 。
我们看构造函数里面,初始化foo = 42 ,而如果instance != null ,说明已经调用构造函数了,那assert foo == 42 肯定成功的。真是这样吗?其实,有可能出现assert fail的情况。
构造一个对象,其实是拆分成了2步:
首先,分配内存空间给对象(allocate)
然后,才调用构造函数(init)
所以,线程1 new一个instance可以拆分成
static void thread1() {
instance = <allocate UnsafePublication>;
instance.<init>();
}问题就出在这里。分配内存空间给对象,和调用构造函数不是原子性的。这意味着,线程2可能已经看见了线程1为instance分配了内存空间,即instance != null ,但是线程1其实还没有调用构造函数。那么,此时assert foo == 42 就失败了。
解决方式?final出马。
把final成员修饰成final:final int foo = 0;
一个final成员,如果是在构造函数里面初始化的,那么会在构造函数的末尾插入一个<freeze>指令
UnsafePublication() {
foo = 42;
<freeze>
}freeze指令能够保证,对象分配和final成员的初始化,同时对其他线程可见。
这并不是说,对象的内存分配和final成员的初始化,会马上对其他线程可见。而是指即使我们已经为对象创建了内存空间了,即allocate 已经完成,但是只要final成员还没有初始化,那么,对象的allocate就对其他线程不可见,即instance == null ,只有当final成员初始化了,allocate 才对其他线程可见。
所以,如果instance不为null,一定能保证foo = 42。
|thread1 | thread2
| instance = <allocate>; |
| instance.foo = 42; |
| <freeze instance.foo> |
|-----------------------------|---------------------
| | if (instance != null){
| | assert instance.foo == 42; // success
| | }jni
编译器会重排java调用和jni调用吗?不会。
看下面例子。
class Externalization {
int foo = 0;
void method() {
foo = 42;
jni();
}
native void jni();
// jni里面判断foo: assert == 42;
}JIT是无法读取native代码的,所以无法去优化它,jni里面的内存管理也无法用gc来代劳。在JIT不了解JNI代码都做了什么事情的情况下,如果重排java调用和jni调用,是非常危险的,违背了单线程语义正确性的原则。
所以,有人说jni调用效率并不高,有一部分原因,应该就是因为JIT无法优化jni调用的原因吧。
所以,这里的assert == 42是成功的。
Thread Divergence Action
看如下例子
class ThreadDivergence {
int foo = 42;
void thread1() {
while(true);
foo = 0;
}
void thread2() {
assert foo == 42;
}
}线程1调用thread1方法,线程2调用thread2方法,线程1有foo = 0,那么线程2可能出现assert fail吗?不会的。
看看thread1()。
while(true); 是一个Thread Divergence Action。至于什么是Thread Divergence Action,看了定义其实我不太理解意思(sorry),这里就不瞎BB误导大家了。
但是可以肯定的2点:
while(true);这个无线循环是一个Thread Divergence Action。JIT不会重排Thread Divergence Action语句。
也就是说,while(true); 和foo = 0 不会发生重排。这个很好理解,因为while(true); 是一个无限循环,永远也不会执行foo = 0,如果把foo = 0 放到while(true) 前面,程序语义就改变了,这是不允许的。
本篇文章到这里就结束了。如果您看到了这,非常感谢您的时间和耐心~~
如果本文有理解偏颇或者错误的地方,请留言指正,谢谢~~

















 409
409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









