







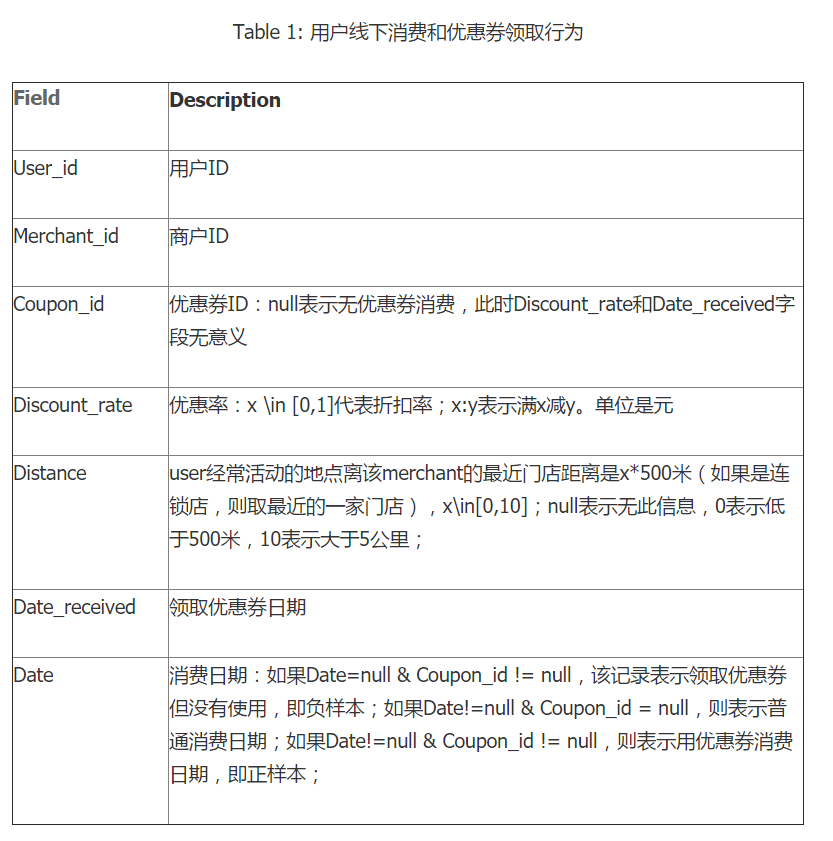
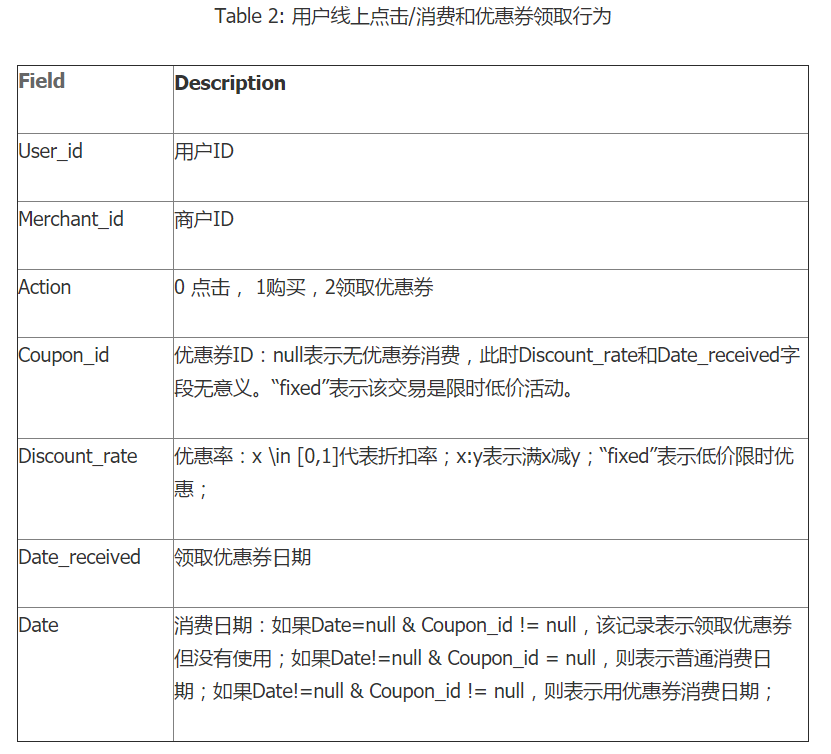
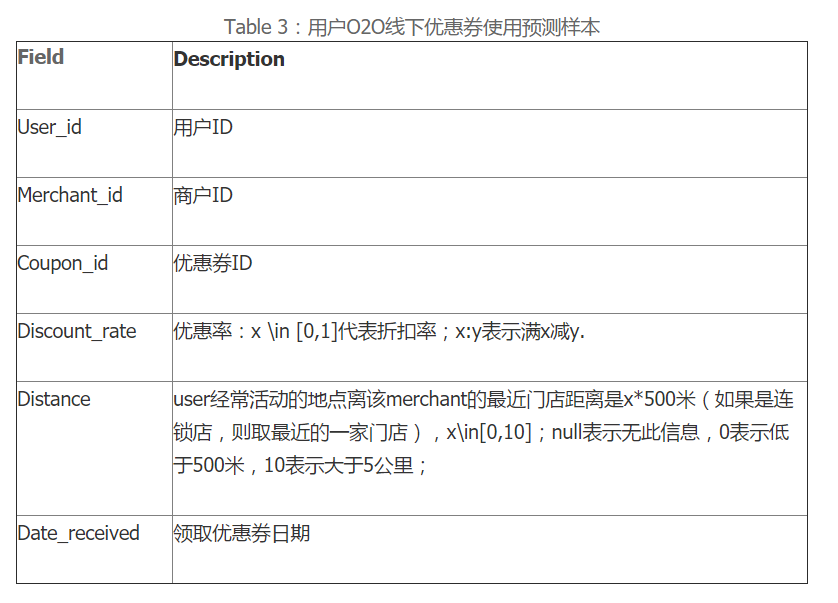
1. 赛题简介
以优惠券盘活老用户或吸引新客户进店消费是O2O的一种重要营销方式。然而随机投放的优惠券对多数用户造成无意义的干扰。对商家而言,滥发的优惠券可能降低品牌声誉,同时难以估算营销成本。 个性化投放是提高优惠券核销率的重要技术,它可以让具有一定偏好的消费者得到真正的实惠,同时赋予商家更强的营销能力。
本次大赛为参赛选手提供了O2O场景相关的丰富数据,希望参赛选手通过分析建模,精准预测用户是否会在规定时间内使用相应优惠券。
2. 数据
本赛题提供用户在2016年1月1日至2016年6月30日之间真实线上线下消费行为,预测用户在2016年7月领取优惠券后15天以内的使用情况。
3. 数据分析
训练集所有用户中,约1/4的用户参与了线上及线下的活动,约1/4仅参与了线下,约1/2仅参与了线上
测试集中用户几乎被训练集中参与过线下活动的用户全部覆盖,有一小半是活跃用户<线上线下都参加>
线上与线下的商家完全没有交集
测试集中商家几乎被训练集中线下商家全部覆盖
测试集中全部是全新的优惠券<优惠券ID是不同的,所以对于优惠券的特征描述应当是其商家、折扣率等,与ID无关。
根据经验,我们知道活跃用户更可能使用优惠券,活跃商家所发出的优惠券更可能被使用,用户对某个商家的喜爱程度越高越可能使用这个商家发的优惠券
用户在周末更有时间更可能使用优惠券
4. 提取特征(pandas,numpy)
1) 优惠券相关特征,从预测样本的discount_rate,data_received提取:
Day_of_week //优惠券领取日期属于周几,使用独热编码
Is_weekend //优惠券领取日期是否属于周末
Day_of_month //优惠券领取日期属于一月中的哪天
Days_distance //优惠券领取日期离要预测的开始日期间隔天数
Discount_man //提取满减优惠券中满多少元
Discount_jian //提取满减优惠券中减多少元
Discout_rate //优惠券折扣率
2) 商户相关特征,从训练样本的distance,date_received,date提取:
Total_sales //商户被消费次数
Sales_use_coupon //商户使用优惠券被消费次数
Total_coupon //商户发放优惠券次数
Merchant_min_distance //所有使用优惠券消费的用户与商户的最小距离
Merchant_max_distance //所有使用优惠券消费的用户与商户的最大距离
Merchant_mean_distance //所有使用优惠券消费的用户与商户的平均距离
Use_coupon_rate //商户使用优惠券消费比例,等于sales_use_coupon/total_sales
Transfer_rate //商户优惠券转化率,等于sales_use_coupon/tatal_coupon
3) 用户相关特征,从训练样本的discount_rate, distance, data_received, data提取:
Count_merchant //用户消费商户数量
Buy_use_coupon //用户使用优惠券消费次数
Buy_total //用户消费次数
Coupon_received //用户领取优惠券次数
User_min_distance //所有使用优惠券消费的商户与用户的最小距离
User_max_distance //所有使用优惠券消费的商户与用户的最大距离
User_mean_distance //所有使用优惠券消费的商户与用户的平均距离
Avg_user_date_datereceived_gap //用户从领取优惠券到消费的平均时间间隔
Min_user_date_datereceived_gap //用户从领取优惠券到消费的最小时间间隔
Max_user_date_datereceived_gap //用户从领取优惠券到消费的最大时间间隔
Buy_use_coupon_rate //用户使用优惠券消费占总消费的比例
User_coupon_transfer_rate //用户优惠券转化为实际消费比例
4) 用户-商户相关特征,从训练样本date,date_received提取特征:
User_merchant_buy_total //用户在商户消费次数
User_merchant_received //用户领取商户优惠券次数
User_merchant_buy_use_coupon //用户在商户使用优惠券消费次数
User_merchant_buy_common //用户在商户普通消费次数
User_merchant_coupon_transfer_rate //用户对商户的优惠券转化率
User_merchant_rate //用户对商户消费占总交互比例
User_merchant_common_buy_rate //用户对商户普通消费占总消费比例
User_merchant_coupon_buy_rate //用户对商户使用优惠券消费占总消费比例
5. 训练模型(xgboost, sklearn)
选择xgboost模型,xgboost是一种迭代提升方法,由多个弱分类器组成的效果较好的强分类器,其中底层的弱分类器一般是由决策树实现的,每棵树所学习的是上一棵树的残差。
它的优势主要有:
使用L1、L2范数进行正则化,防止过拟合;
实现树节点粒度的并行计算;
允许自定义损失函数和评价标准;
XGBoost会一直分裂到指定的最大深度(max_depth),然后回过头来剪枝。如果某个节点之后不再有正值,它会去除这个分裂。 这种做法的优点,当一个负损失(如-2)后面有个正损失(如+10)的时候,就显现出来了。XGBoost会继续分裂,然后发现这两个分裂综合起来会得到+8,因此会保留这两个分裂。
内置交叉验证,XGBoost允许在每一轮boosting迭代中使用交叉验证。因此,可以方便地获得最优boosting迭代次数
重要参数:
1、eta[默认0.3]
和GBM中的 learning rate 参数类似。 通过减少每一步的权重,可以提高模型的鲁棒性。 典型值为0.01-0.2。
2、min_child_weight[默认1]
决定最小叶子节点样本权重和。 和GBM的 min_child_leaf 参数类似,但不完全一样。XGBoost的这个参数是最小样本权重的和,而GBM参数是最小样本总数。 这个参数用于避免过拟合。当它的值较大时,可以避免模型学习到局部的特殊样本。 但是如果这个值过高,会导致欠拟合。这个参数需要使用CV来调整。
3、max_depth[默认6]
和GBM中的参数相同,这个值为树的最大深度。 这个值也是用来避免过拟合的。max_depth越大,模型会学到更具体更局部的样本。 需要使用CV函数来进行调优。 典型值:3-10
4、max_leaf_nodes
树上最大的节点或叶子的数量。 可以替代max_depth的作用。因为如果生成的是二叉树,一个深度为n的树最多生成n2个叶子。 如果定义了这个参数,GBM会忽略max_depth参数。
5、gamma[默认0]
在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。Gamma指定了节点分裂所需的最小损失函数下降值。 这个参数的值越大,算法越保守。这个参数的值和损失函数息息相关,所以是需要调整的。
6、max_delta_step[默认0]
这参数限制每棵树权重改变的最大步长。如果这个参数的值为0,那就意味着没有约束。如果它被赋予了某个正值,那么它会让这个算法更加保守。 通常,这个参数不需要设置。但是当各类别的样本十分不平衡时,它对逻辑回归是很有帮助的。 这个参数一般用不到,但是你可以挖掘出来它更多的用处。
7、subsample[默认1]
和GBM中的subsample参数一模一样。这个参数控制对于每棵树,随机采样的比例。 减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。 典型值:0.5-1
8、colsample_bytree[默认1]
和GBM里面的max_features参数类似。用来控制每棵随机采样的列数的占比(每一列是一个特征)。 典型值:0.5-1
9、colsample_bylevel[默认1]
用来控制树的每一级的每一次分裂,对列数的采样的占比。 我个人一般不太用这个参数,因为subsample参数和colsample_bytree参数可以起到相同的作用。但是如果感兴趣,可以挖掘这个参数更多的用处。
10、lambda[默认1]
权重的L2正则化项。(和Ridge regression类似)。 这个参数是用来控制XGBoost的正则化部分的。
11、alpha[默认1]
权重的L1正则化项。(和Lasso regression类似)。 可以应用在很高维度的情况下,使得算法的速度更快。
12、scale_pos_weight[默认1]
在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。
参数调优(使用交叉验证):
1. 选择较高的学习速率(learning rate)。一般情况下,学习速率的值为0.1。但是,对于不同的问题,理想的学习速率有时候会在0.05到0.3之间波动。选择对应于此学习速率的理想决策树数量。XGBoost有一个很有用的函数“cv”,这个函数可以在每一次迭代中使用交叉验证,并返回理想的决策树数量。
2. 对于给定的学习速率和决策树数量,使用GridSearchCV进行决策树特定参数调优(max_depth, min_child_weight, gamma, subsample, colsample_bytree)。
3. xgboost的正则化参数的调优。(lambda, alpha)。这些参数可以降低模型的复杂度,从而提高模型的表现。
4. 降低学习速率,确定理想参数。
6、总结与收获
对大数据在实际场景的应用有了更深的了解
想要提高模型效果,特征很重要
熟悉如何运用python进行数据处理,特征提取
对使用的模型参数要了解















 7009
7009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









