









Spark学习笔记:3、Spark核心概念RDD
3.1 RDD概念
弹性分布式数据集(Resilient Distributed Datasets,RDD) ,可以分三个层次来理解:
- 数据集:故名思议,RDD 是数据集合的抽象,是复杂物理介质上存在数据的一种逻辑视图。从外部来看,RDD 的确可以被看待成经过封装,带扩展特性(如容错性)的数据集合。
- 分布式:RDD的数据可能在物理上存储在多个节点的磁盘或内存中,也就是所谓的多级存储。
- 弹性:虽然 RDD 内部存储的数据是只读的,但是,我们可以去修改(例如通过 repartition 转换操作)并行计算计算单元的划分结构,也就是分区的数量。
Spark数据存储的核心是弹性分布式数据集(RDD),我们可以把RDD简单地理解为一个抽象的大数组,但是这个数组是分布式的,逻辑上RDD的每个分区叫做一个Partition。
在物理上,RDD对象实质上是一个元数据结构,存储着Block、Node等映射关系,以及其他元数据信息。一个RDD就是一组分区(Partition),RDD的每个分区Partition对应一个Block,Block可以存储在内存,当内存不够时可以存储到磁盘上。
如下图所示,存在2个RDD:RDD1包含3个分区,分别存储在Node1、Node2和Node3的内存中;RDD2也包含3个分区,p1和p2分区存储在Node1和Node2的内存中,p3分区存在在Node3的磁盘中。
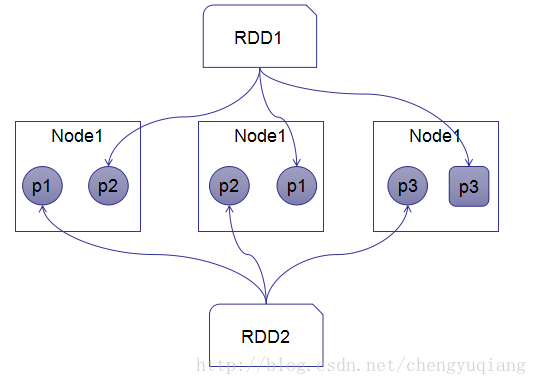
RDD的数据源也可以存储在HDFS上,数据按照HDFS分布策略进行分区,HDFS中的一个Block对应Spark RDD的一个Partition。
3.2 RDD基本操作
(1)RDD包括两大类基本操作Transformation和Acion
- Transformation
- 可以通过Scala集合或者Hadoop数据集钩子一个新的RDD
- 将已有RDD转换为新的RDD
- 常用算子(操作,方法)有map、filter、groupBy、reduceBy
- Aciton
- 通过RDD计算得到一个或者多个值
- 常用算子有count、reduce、saveAsTextFile
主要的Transformation和Acion如下表所示:

(2)作用在RDD上的操作(算子)
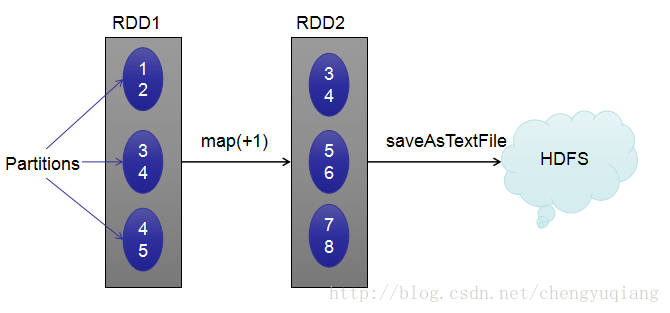
(3)惰性执行(Lazy Execution)
- Transformation只记录RDD的转换关系,并没有真正执行转换
- Action是触发程序执行的算子
3.3 RDD操作示例
3.3.1 简单例子
(1)代码
[root@master ~]# spark-shell
17/09/06 03:36:33 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/09/06 03:36:39 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Spark context Web UI available at http://192.168.1.180:4040
Spark context available as 'sc' (master = local[*], app id = local-1504683394043).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_144)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val rdd1=sc.parallelize(1 to 100,5)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> val rdd2=rdd1.map(_+1)
rdd2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[1] at map at <console>:26
scala> rdd2.take(2)
res0: Array[Int] = Array(2, 3)
scala> rdd2.count
res1: Long = 100
scala>
(2)程序说明
- spark-shell的日志信息
Spark context available as 'sc',表示spark-shell中已经默认将SparkContext类初始化为对象sc,在spark-shell中可以直接使用SparkContext的对象sc。 - SparkContext 的 parallelize(),将一个存在的集合,变成一个RDD,这种方式试用于学习spark和做一些spark的测试
- sc.parallelize(1 to 100,5)表示将1 to 100产生的集合(Range)转换成一个RDD,并创建5个partition。
- 当我们忘记了parallelize单词时,我们可以在spark-shell中输入sc.pa,然后按tab键,会自动补齐。这是一个非常实用的功能!
- rdd1.map(_+1)表示每个元素+1,并产生一个新的RDD。这是一个Transformation操作。
- take(2)表示取RDD前2个元素,这是个Action操作。当这个Action操作执行时,上面的map(_+1)操作才真正执行。
- count表示RDD元素总数,也是一个Action操作。
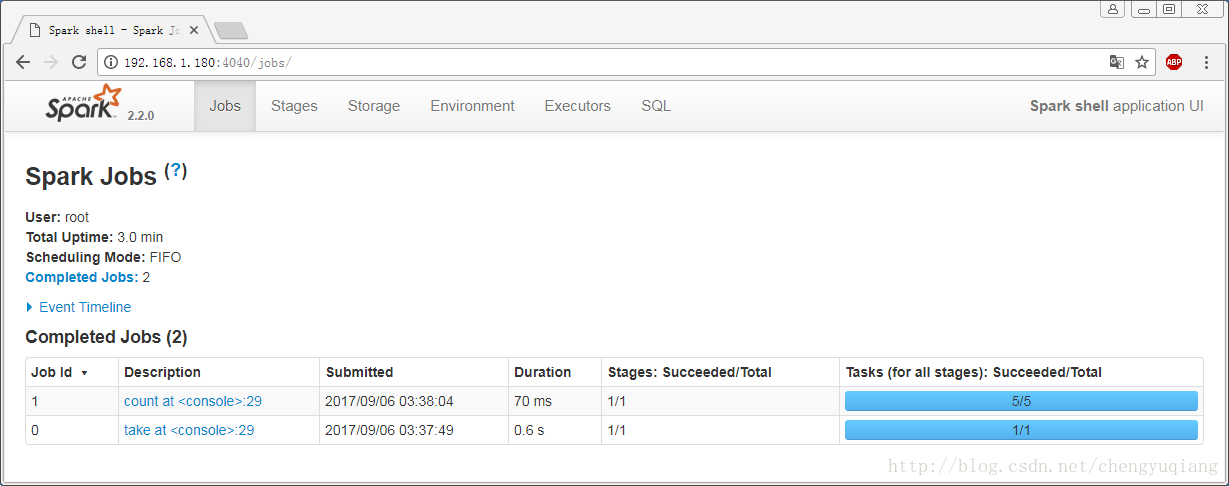
- 在Spark WebUI中可以看到两个Action操作,如下图。
3.3.2 常用算子
(1)代码
scala> val listRdd=sc.parallelize(List(1,2,3),3)
listRdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at parallelize at <console>:24
scala> val squares=listRdd.map(x=>x*x)
squares: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[4] at map at <console>:26
scala> squares.take(3)
res3: Array[Int] = Array(1, 4, 9)
scala> val even=squares.filter(_%2==0)
even: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[5] at filter at <console>:28
scala> squares.first
res4: Int = 1
scala> even.first
res5: Int = 4
scala> val nums=sc.parallelize(1 to 3)
nums: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[6] at parallelize at <console>:24
scala> val mapRdd=nums.flatMap(x=>1 to x)
mapRdd: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[7] at flatMap at <console>:26
scala> mapRdd.count
res6: Long = 6
scala> mapRdd.take(6)
res7: Array[Int] = Array(1, 1, 2, 1, 2, 3)
scala>
(2)程序说明
- map(x=>x*x)每个元素平方,生成新的RDD
- filter(_%2==0)对RDD中每个元素进行过滤(偶数留下),生成新的RDD
- nums.flatMap(x=>1 to x),将一个元素映射成多个元素,生成新的RDD
3.3.3 Key/Value型RDD
(1)代码
scala> val pets=sc.parallelize(List( ("cat",1),("dog",1),("cat",2) ))
pets: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[8] at parallelize at <console>:24
scala> val pets2=pets.reduceByKey(_+_)
pets2: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[9] at reduceByKey at <console>:26
scala> pets2.count
res8: Long = 2
scala> pets2.take(2)
res10: Array[(String, Int)] = Array((dog,1), (cat,3))
scala> val pets3=pets.groupByKey()
pets3: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[10] at groupByKey at <console>:26
scala> pets3.count
res11: Long = 2
scala> pets3.take(2)
res12: Array[(String, Iterable[Int])] = Array((dog,CompactBuffer(1)), (cat,CompactBuffer(1, 2)))
scala> val pets4=pets.sortByKey()
pets4: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[11] at sortByKey at <console>:26
scala> pets4.take(3)
res14: Array[(String, Int)] = Array((cat,1), (cat,2), (dog,1))
scala> (2)程序说明
- reduceByKey就是对元素为KV对的RDD中Key相同的元素的Value进行reduce,因此,Key相同的多个元素的值被reduce为一个值,然后与原RDD中的Key组成一个新的KV对。
reduceByKey(_+_)对每个key对应的多个value进行merge操作,自动在map端进行本地combine groupByKey()对每个key进行归并,但只生成一个sequence。sortByKey()按照key进行排序
3.3.4 WordCount
WordCount是大数据处理的HelloWorld,下面看看Spark是如何实现。
(1)准备数据
[root@master ~]# mkdir data
[root@master ~]# vi data/words
[root@master ~]# cat data/words
hi hello
how do you do?
hello, Spark!
hello, Scala!
[root@master ~]#(2)转换处理
scala> val rdd=sc.textFile("file:///root/data/words")
rdd: org.apache.spark.rdd.RDD[String] = file:///root/data/words MapPartitionsRDD[3] at textFile at <console>:24
scala> val mapRdd=rdd.flatMap(_.split(" "))
mapRdd: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[4] at flatMap at <console>:26
scala> mapRdd.first
res2: String = hi
scala> val kvRdd=mapRdd.map(x=>(x,1))
kvRdd: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[5] at map at <console>:28
scala> kvRdd.first
res3: (String, Int) = (hi,1)
scala> kvRdd.take(2)
res4: Array[(String, Int)] = Array((hi,1), (hello,1))
scala> val rsRdd=kvRdd.reduceByKey(_+_)
rsRdd: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[6] at reduceByKey at <console>:30
scala> rsRdd.take(2)
res5: Array[(String, Int)] = Array((how,1), (do?,1))
scala> rsRdd.saveAsTextFile("file:///tmp/output")
scala>程序说明:
- sc.textFile()方法表示将某个文件转换为RDD(实际上是利用了TextInputFormat生成了一个HadoopRDD),所以sc.textFile(“file:///root/data/words”)表示将本地文件/root/data/words转换为一个RDD。
- core-site.xml配置文件中fs.defaultFS默认值是file://,表示本地文件。file:///root/data/words实际上是file://和/root/data/words的组合,此处未使用HDFS,所以指定本地文件。
rdd.flatMap(_.split(" "))表示将RDD每个元素(文件的每行)按照空格分割,并生成新的RDDmapRdd.map(x=>(x,1))表示将RDD每个元素x生成(x,1)Key-Value对,并生成新的RDDkvRdd.reduceByKey(_+_)对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义(value值相加)。- rsRdd.saveAsTextFile(“file:///tmp/output”)表示将rsRdd数据保存到本地/tmp/output目录下。
(3)查看结果
[root@master ~]# ll /tmp/output
total 8
-rw-r--r-- 1 root root 48 Sep 6 03:51 part-00000
-rw-r--r-- 1 root root 33 Sep 6 03:51 part-00001
-rw-r--r-- 1 root root 0 Sep 6 03:51 _SUCCESS
[root@master ~]# cat /tmp/output/part-00000
(how,1)
(do?,1)
(hello,,2)
(hello,1)
(Spark!,1)
[root@master ~]# cat /tmp/output/part-00001
(you,1)
(Scala!,1)
(hi,1)
(do,1)
[root@master ~]# 3.4 Spark程序设计基本流程
Spark程序设计基本流程
1)创建SparkContext对象
每个Spark应用程序有且仅有一个SparkContext对象,封装了Spark执行环境信息
2)创建RDD
可以从Scala集合或Hadoop数据集上创建
3)在RDD之上进行转换和action
MapReduce只提供了map和reduce两种操作,而Spark提供了多种转换和action函数
4)返回结果
保存到HDFS中,或直接打印出来。














 2222
2222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









