






1 spark简介
(1) spark是基于内存计算的分布式并行计算框架,如今已成为apache软件基金会最重要的三大分布式计算系统开源项目之一(Hadoop、Spark、Storm)。
(2) spark组件
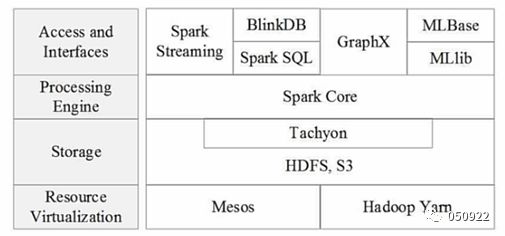
(3) spark组件应用场景
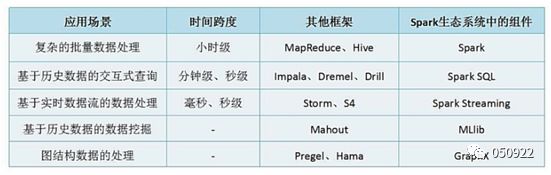
Spark Streaming:提供流计算功能
Sparl SQL:提供交互式查询分析
Spark Core:提供内存计算
Mllib:提供机器学习算法库的组件
Graphx:提供图计算
2 特点
运行速度快:使用DAG执行引擎支持循环数据流与内存计算;
容易使用:支持使用Scala、Java、Python和R语言进行编程,可以通过Spark Shell进行交互式编程;
通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件;
运行模式多样:可运行于独立的集群模式中,可运行于Hadoop中,也可以运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
3 运行模式
(1) 本地模式:单机模型,不会跟其他节点进行交互,主要是用来做调试用的
验证:[root@masterspark-2.2.0]# ./bin/run-example SparkPi 10 --master local[2]
后面数字表示用多少个线程来去并发
(2) Standalone模式:独立模式,使用spark自带的简单集群管理器,类似MapReduce1.0所采取的模式,完全由内部实现容错性和资源管理;
– Master/Slave结构
• Master:类似Yarn中的RM
• Worker:类似Yarn中的NM
验证:./bin/spark-submit--class org.apache.spark.examples.SparkPi --master spark://master:7077examples/jars/spark-examples_2.11-2.2.0.jar
(3) Yarn模式:使用Yarn作为集群管理器,这样可以与其他计算框架共享资源。
验证:./bin/spark-submit--class org.apache.spark.examples.SparkPi --master yarn-cluster examples/jars/spark-examples_2.11-2.1.2.jar10
Sparkon Yarn分为两种模式:
a) Yarn-Client:drive在本地,适用于交互与调试,结果显示在终端;
b) Yarn-Cluster:driver在集群中的AM,适用于生产环境,结果在log。
– Master/Slave结构
• RM:全局资源管理器,负责系统的资源管理和分配
• NM:每个节点上的资源和任务管理器
• AM:每个应用程序都有一个,负责任务调度和监视,并与RM调度器协商为任务获取资源。
(4) Mesos模式:使用Messos作为集群管理器
(5) 简单操作
启动spark:/usr/local/spark-2.2.0/sbin/start-all.sh
启动spark终端:/usr/local/spark-2.2.0/bin/spark-shell
启动,指定主机,怕多个spark集群时,启动混乱
./spark-shell –master spark://master:7707
指定资源启动
./spark-shell –master spark://master:7077 –executor-memory512m –total-executor-cores 2
spark-shell 启动spark
spark-submit 提交任务
4 Yarn Cluster和Yarn Client的区别
Yarn Cluster vs. Yarn Client区别:本质是AM进程的区别, cluster模式下,driver运行在AM中,负责向Yarn申请资源,并监督作业运行状况,当用户提交完作业后,就关掉Client,作业会继续在yarn上运行。cluster模式不适合交互类型的作业。
而Client模式,Driver在任务提交机(Client)上执行,ApplicationMaster只负责向ResourceManager申请executor需要的资源,client会和请求的container通信来调度任务,即client不能离开,基于yarn时,spark-shell和pyspark必须要使用yarn-client模式。
Driver在哪个位置也决定了是哪个模型
Driver运行在AM上就是Yarn-Cluster模式,运行在Client上就是Yarn-Client模式。
AM是Application Master,AM会被RM指定一个NM,然后AM在上面启动一个container,AM就是任务的监控与调度,向RM申请资源,给NM发送container更多的信息,寻求NM下面的容器,满足它的任务需求。container里的executor(jvm进程)运行任务。
5 Spark与hadoop区别
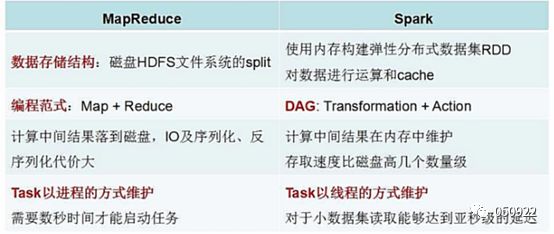
Hadoop缺点:
(1) 表达能力有限,只有map和reduce两个原语
(2) 延迟高,启动map、reduce太耗时
(3) 计算慢,每一步都要保存中间结果落磁盘
(4) 任务直接的衔接涉及IO开销
(5) 在前一个任务执行完成之前,其他任务就无法开始,难于胜任复杂、多阶段的计算任务(map阶段完成,reduce阶段才能开始)
Spark优点:
(1) Spark的计算模式也属于MapReduce,但不局限于map和reduce操作还提供了多种数据集操作类型,编程模型比mapreduce更灵活;
(2) 最大化利用了内存cache,因为是多线程共享内存资源,最大化的利用了内存;
(3) 内存计算,中间结果放内存中,加速迭代;
(4) Spark基于DAG的任务调度执行机制,要优于mapreduce的迭代执行机制。
Spakr为什么比mapreduce速度快?
Mapreduce中间有partition这个环节,从map的输出到reduce的输入,这中间要跨一些网络的IO,而且map内部和reduce内部,都有把数据往磁盘上存储这个过程,spark内存计算,减少了这些流程,处理数据的过程中,数据不需要再去读写HDFS,全部是在内部中完成的,所以,spark就能够更好的使用于数据挖掘,机器学习等迭代算法中。
spark只是计算框架,不具备数据存储功能 只能借助外部分布式存储系统:HDFS、HBase、Hive。
Mapreduce是多进程并发方式:
方便控制资源,独享进程空间,但是消耗更多的启动时间,不适合运行低延时作业,导致mapreduce时效性差;
Spark是多线程并发方式:
运行速度快,时效性更好,同节点上的任务都在一个进程中,最大化利用内存,适合内存密集型计算(加载大量词表程序);多线程并发方式有一个线程池的概念,同节点上所有任务运行在JVM进程(Executor)里面,省去进程频繁启停的开销,适合Executor所占资源被多批任务调用;但是会出现多个任务竞争资源,相比mapreduce,不知道每个任务需要多少资源,一个进程挂了,里面的线程都挂了,所以spark稳定性没有mapreduce好。
架构对比:
在没spark之前,主要是使用hadoop+storm,这种架构部署比较繁琐
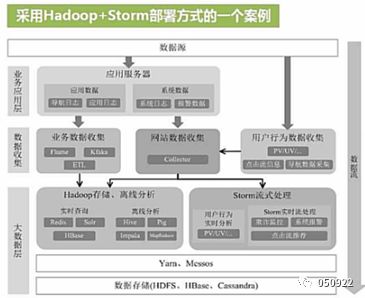
有了spark之后,spark架构满足批处理和流处理需求
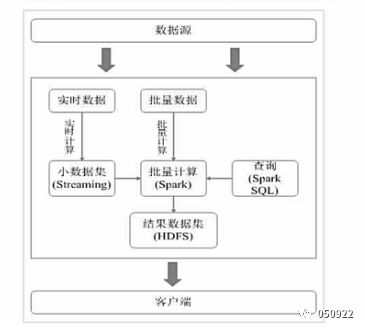
用Spark架构具有如下优点:
(1) 实现一键式安装和配置、线程级别的任务监控和告警
(2) 降低硬件集群、软件维护、任务监控和应用开发的难度
(3) 便于做成统一的硬件、计算平台资源池
(4) 需要说明的是,Spark Streaming无法实现毫秒级的流计算,因此,对于需要毫秒级实时响应的企业应用而言,仍然需要采用流计算框架(如Strom)
不同的计算框架统一运行在YARN中可以带来如下好处:
(1) 共享底层存储,避免数据跨集群迁移
(2) 计算资源需伸缩
(3) 不用负载应用混搭,集群利用率高
Spark无法取代Hadoop:
(1) 由于Hadoop生态系统中的一些组件所实现的功能,目前还是无法由Spark取代的
(2) 现有的Hadoop组件开发的应用,完全转移到Spark上需要一定的成本
6 基本概念
(1) Application:spark-submit提交的应用程序;
(2) RDD:是弹性分布式数据集的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模式;
(3) Driver:完成任务的调度和资源(container、executor)划分;
(4) DAG:有向无环图,RDD一系列的转换,反映RDD之间的依赖关系;
(5) Executor:是运行在工作节点的一个进程,作为一个YARN容器(container)运行,负责运行Task,一个从节点上可以有多个Executor;在Spark on Yarn模式下,其进程名称为 CoarseGrainedExecutor Backend;
(6) Job:和MR中Job不一样。 MR中Job主要是Map或者ReduceJob。而spark中的Job包含多个RDD及作用于相应RDD上的各种算子,如count,first等;
(7) Task:最基本的执行单元,RDD带有partition,每个partition在一个executor上的执行就是是一个task;
(8) Stage:是Spark中独有的,是Job的基本调度单位,一个Job会分为多组Task,每组task被称为Stage。或者也被称为TaskSet,代表了一组关联的,相互之间没有Shuffle依赖关系的任务组成的任务集;
(9) DAGScheduler:根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler,其划分Stage的依据是RDD之间的依赖关系;
(10)TaskScheduler:将TaskSet提交给worker运行,每个executor运行什么task就是在此分配。
7 Spark程序结构
应用程序--->driver+多个job--->多个stage--->多个task
(1) 应用程序:由一个driver program和多个job构成;
(2) Job:由多个stage组成,由action算子划分;
(3) Stage:由多个task组成,对应一个taskset,由宽依赖划分;
(4) Taskset:对应一组关联的相互之间没有shuffle依赖关系(窄依赖)的task组成;
(5) Task:任务最小的工作单元,RDD中的partition;
(6) 当执行Application时,Driver会向集群管理器申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行Task,运行结束后,执行结果会返回给Driver,或者写到HDFS或者其他数据库中。
8 Spark运行架构
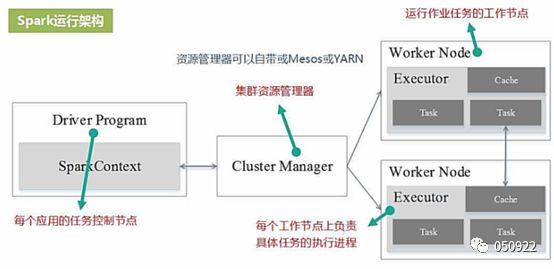
(1) Driver Program:每个任务应用的控制节点;
(2) Cluster Manager:集群资源管理器,管理cpu、内存等资源,可以用yarn或者自带的或者Mesos;
(3) Worker node:运行作业任务的工作节点;
(4) Executor:每个工作节点上负责具体任务的执行进程。
采用executor好处:
(1) 当内存空间足够大的时间,全部计算过程都放在内存中执行。优先使用内存利用多线程来执行具体的任务,减少任务的启动开销;
(2) executor中有一个blockManager存储模块,会将内存和磁盘共同存储设备,有效减少IO开销。
架构特点:
(1) 每个Application都有自己专属的executor进程,并且该进程在Application运行期间一直驻留,executor进程以多线程的方式运行task;
(2) spark运行过程与资源管理器无关,只要能够获取executor进程并保持通信即可;
(3) task采用了数据本地性和推测执行等优化机制;
(4) 推测执行机制:就是等待较近的机器资源,推测等待的时间比传输到别的机子的时间要多,所以就等待当前机子任务执行完释放资源,自己替位执行任务。
9 Spark on yarn架构

(1) Spark是下一代的mapreduce,扩展了mr的数据处理流程;
(2) executor都是装载在container里运行,container默认内存是1G(参数yarn.scheduler.minimum-allocation-mb定义);
(3) executor分配的内存是executor-memory,向YARN申请的内存是executor-memory * num-executors;
(4) AM在Spark中叫driver, AM向RM申请的是executor资源,当分配完资源后,executor启动后,由spark的AM向executor分配task,分配多少task、分配到哪个executor由AM决定,可理解为spark也有个调度过程,这些task都运行在executor的坑里;
(5) Executor有线程池多线程管理这些坑内的task,executor伴随整个app的生命周期,线程池模型,省去进程频繁启停的开销。
10 RDD定义
RDD(ResilientDistributed Dataset ):弹性分布式数据集(相当于集合),它的本质是分区记录的集合(只读的、可分区的分布式数据集),而不是数据集本身。
Spark基于弹性分布式数据集(RDD)模型,具有良好的通用性、容错性与并行处理数据的能力。
一个RDD就是一个分布式对象集合,本质是一个只读的分区记录集合,每个RDD可分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
RDD不存储数据,只存储数据获取方法,分区方法和数据类型,真正的数据只有在执行的时候才加载进来的,加载数据主要有两个来源:
(1) Spark外部--->比如HDFS
(2) Spark内部--->其他RDD
11 RDD特征
(1) RDD使用户能够显式将计算结果保存在内存中,控制数据的划分,并使用更丰富的操作集合来处理;
(2) 只读,不能对本身RDD做修改,可以通过转换得到新的RDD;
(3) 容错性:记录数据的变换而不是数据本身,保证容错(lineage);
•通常在不同机器上备份数据或者记录数据更新的方式完成容错,但这种对任务密集型任务代价很高;
•RDD采用数据应用变换(map,filter,join),若部分数据丢失,RDD拥有足够的信息得知这部分数据是如何计算得到的,可通过重新计算来得到丢失的数据;
•这种恢复数据方法很快,无需大量数据复制操作,可以认为Spark是基于RDD模型的系统,窄依赖数据恢复比宽依赖快。
(4) 懒操作:延迟计算, action的时候才操作;
(5) 瞬时性:用时才产生,用完就释放。
数据回滚,依赖lineage,防止数据丢失
Spark任务来说,最终目标是Action(save、collect)
Lineage主要目的就是做一个容错
窄依赖数据恢复是会很快的,是不需要备份的,对于宽依赖数据恢复是很慢;
数据是很宝贵的,通常的优化方法是把宽依赖得到的数据要做一次缓存备份。
12 RDD创建
(1) 基于外部数据源创建RDD,外部数据源包括HDFS上的文件,通过JDBC访问的数据库表或者Spark shell中创建的本地对象集合;
如从HDFS中读取数据构建RDD:val a = sc.textFile(“/xxx/yyy/file”)
(2) 通过现有RDD转换得到:val b = a.map(x => (x,1))
(3) 定义一个scala数组(调试中比较常用):val c = sc.parallelize(1 to 10,1)
(4) 有一个已经存在的RDD通过持久化操作生成(数据落地比较常用)
val d =a.persist(),a.saveAsHadoopFile( “/xxx/yyy/zzz”)
sc是Sparkcontext,是spark的入口,编写spark程序用到的第一个类,包含sparkconf sparkenv等类。
13 RDD操作
Spark针对RDD提供了两类操作:transformations和action
(1) Transformations是RDD之间的变换,action会对数据一定的操作;
(2) transformations采用懒策略,仅在对相关RDD进行action提交时才触发计算
Tansformations
| filter(func) | 筛选出满足函数func的元素,并返回一个新的数据集,打平数据集 |
| map(func) | 将每个元素传递到函数func中,并将结果返回为一个新的数据集 |
| flatMap(func) | 与map()相似,但每个输入元素都可以映射到0或多个输出结果 |
| groupByKey() | 应用于(K,V)键值对的数据集时,返回一个新的(K,Lterable)形式的数据集 |
| rerduceByKey(func) | 应用于(k,v)键值对的数据集时,返回一个新的(k,v)形式的数据集,其中的每个值都是将每个key传递到函数func中进行聚合 |
| sample(withReplacement, fraction, seed) | 根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子 |
| union(otherDataset) | 对源RDD和参数RDD求并集后返回一个新的RDD |
| intersection(otherDataset) | 对源RDD和参数RDD求交集后返回一个新的RDD |
| distinct([numTasks])) | 对源RDD进行去重后返回一个新的RDD |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | 先按分区聚合 再总的聚合 每次要跟初始值交流 例如:aggregateByKey(0)(_+_,_+_) 对k/y的RDD进行操作 |
| sortByKey([ascending], [numTasks]) | 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
| join(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD 相当于内连接(求交集) |
| cogroup(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD |
| cartesian(otherDataset) | 两个RDD的笛卡尔积 的成很多个K/V |
| pipe(command, [envVars]) | 调用外部程序 |
| coalesce(numPartitions) | 重新分区 第一个参数是要分多少区,第二个参数是否shuffle 默认false 少分区变多分区 true 多分区变少分区 false |
| repartition(numPartitions) | 重新分区 必须shuffle 参数是要分多少区 少变多 |
| cache | RDD缓存,可以避免重复计算从而减少时间,区别:cache内部调用了persist算子,cache默认就一个缓存级别MEMORY-ONLY ,而persist则可以选择缓存级别 |
| persist | |
| partitionBy(partitioner) | 对RDD进行分区 partitioner是分区器 |
| combineByKey | 合并相同的key的值 rdd1.combineByKey(x => x, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n) |
| foldByKey(zeroValue)(seqOp) | 该函数用于K/V做折叠,合并处理 ,与aggregate类似 第一个括号的参数应用于每个V值 第二括号函数是聚合例如:_+_ |
| repartitionAndSortWithinPartitions(partitioner) | 重新分区+排序 比先分区再排序效率高 对K/V的RDD进行操作 |
| leftOuterJoin | leftOuterJoin类似于SQL中的左外关联left outer join,返回结果以前面的RDD为主,关联不上的记录为空。只能用于两个RDD之间的关联,如果要多个RDD关联,多关联几次即可。 |
| rightOuterJoin | rightOuterJoin类似于SQL中的有外关联right outer join,返回结果以参数中的RDD为主,关联不上的记录为空。只能用于两个RDD之间的关联,如果要多个RDD关联,多关联几次即可 |
| subtractByKey | substractByKey和基本转换操作中的subtract类似只不过这里是针对K的,返回在主RDD中出现,并且不在otherRDD中出现的元素 |
Action
行动操作是真正触发计算的地方。Spark程序执行到行动操作时,才会执行真正的计算,从文件中加载数据,完成一次又一次转换操作,最终计算得到结果。
| count() | 返回数据集中的元素个数 |
| collect() | 以数组的形式返回数据集中的所有元素 |
| first() | 返回数据集中的第一个元素 |
| reduce(func) | 通过函数func聚合RDD中所有元素 |
| lookup() | 取前多少行(head) |
| take(n) | 以数组的形式返回数据集中的前n个元素 |
| foreach(func) | 将数据集中的每个元素传递到函数func中运行 |
| takeSample(withReplacement,num, [seed]) | 返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定随机数生成器种子 |
| saveAsTextFile(path) | 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
| saveAsSequenceFile(path) | 将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
| countByKey() | 针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
| aggregate | 先对分区进行操作,在总体操作 |
14 RDD执行过程
(1) RDD读入外部数据源进行创建;
(2) RDD经过一系列的转换(Transformation)操作,每一次都会产生不同的RDD供给下一个转换操作使用;
(3) 最后一个RDD经过“动作”操作进行转换,并输出到外部数据源。
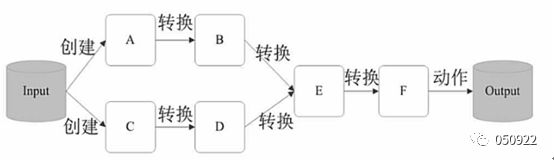
这一系列处理称为一个lineage(血缘关系),即DAG拓扑排序的结果;
优点:惰性调用、管道化、避免同步等待、计算不经磁盘、每次操作变得简单;
15 依赖关系
窄依赖(Narrow Dependencies):是指每一个父RDD的分区最多被子RDD的一个分区使用,比如map、filter、union等;
宽依赖(Wide Dependencies):是指多个子RDD的分区会依赖同一个父RDD的分区,关系错乱,也叫洗牌,比如groupByKey、reduceByKey、join等;
血统(lineage):lineage会记录RDD的元数据和转换行为,以便恢复丢失的分区。
16 划分Stage
DAG(有向无环图):RDD一系列的转换;
spark通过分析各个RDD的依赖关系生成DAG,再通过分析各个RDD中的分区之间的依赖关系来决定如何划分Stage;
划分stage依据:是否发生了shuffle或者宽依赖过程;
划分stage思路:划分stage是从后往前推的,在DAG中进行反向解析,遇到宽依赖就断开,划分为一个stage;遇到窄依赖就把当前的RDD加入到Stage中。
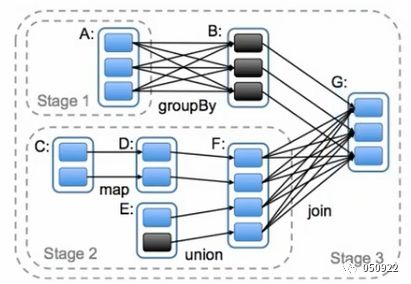
RDDB到RDDA发生宽依赖,所以RDDA是一个stage,记为stage1;
RDDG到RDDF是宽依赖,DAG断开,RDDF之前的全是窄依赖,加入到当前stage中,所以RDDC到RDDF是一个stage,记为stage2;
到RDDG产生join,发生shuffle,RDDG之前的都为同一个stage,记为stage3。
在spark中,task的类型分为2种:shufflemaptask和resulttask
DAG的最后一个阶段会为每个结果的partition生成一个resulttask,即每个stage里面的task数量是又该stage中最后一个RDD的partition的数量所决定的,而其余所有的阶段都会生成shufflemaptask;之所以称为shufflemaptask是因为它需要将自己的计算结果通过shuffle到下一个stage中,也就是说图中的stage1和stage2相当于mapreduce中的mapper,而resulttask所代表的stage3就相当于mapreduce中的reducer。
每个RDD包含了数据分块/分区(partition)的集合,每个partition是不可分割的
每个partition的计算就是一个taks,task是调度的基本单位;
此时的调度指的是:由spark的AM来决定计算partition的task,分配到哪个executor上
若一个stage包含的其他stage中的任务已全部完成,这个stage中的任务才会被加入调度;
调度遵循数据局部性原则,使得数据传输代价最小:如果一个任务需要的数据在某个节点的内存中,这个任务就会被分配至那个节点,需要的数据在某个节点的文件系统中,就分配至那个节点。
17 容错
(1) 如果此task失败, AM会重新分配task;
(2) 如果task依赖的上层partition数据已经失效了,会先将其依赖的partition计算任务再重算一遍;
(3) 宽依赖中被依赖partition,可以将数据保存HDFS,以便快速重构(checkpoint)
窄依赖只依赖上层一个partition,恢复代价较少;
宽依赖依赖上层所有partition,如果数据丢失,上层所有partiton要重算
(4) 可以指定保存一个RDD的数据至节点的cache中,避免数据重新生成,如果内存不够,会LRU(缓存淘汰算法)释放一部分,仍有重构的可能,这是一个递归过程,会一直追本溯源,甚至直到最初的输入数据;
(5) RDD数据保存方式两种:cache和persist。
18 任务运行原理
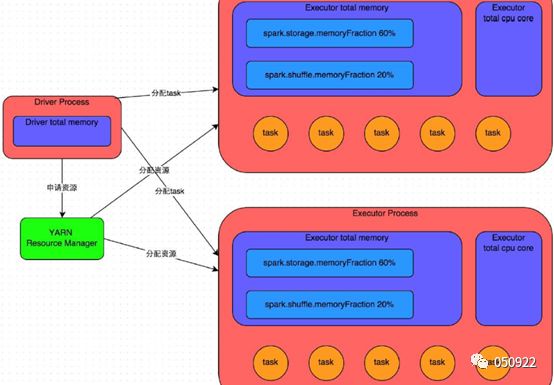
每一个进程包含一个executor对象,内部有一个线程池,每一个线程执行一个task;
线程池的优点:同节点上所有任务运行在JVM进程(Executor)里面,省去进程频繁启停的开销。
task并发度的概率:
一个节点表示一个机器,每个节点可以启动一个或多个executor;
每个executor由若干个虚拟的core(CPU内核)组成,每一个core一次只执行一个task,core是线程粒度;
每个task的执行结果,生成目标RDD的一个partition;
所以:task并发度 = executor数目 * 每一个executo的core数目
除了core这类资源外,还需要内存资源
Executor的内存分为3个部分:
• executor内存(20%):执行内存。Join,aggreate算子都在这块内存执行,shuffle数据缓存在这个内存上,如果内存满了(写磁盘),shuffle过程数据尽量不要往磁盘上写,影响spark执行效率;
• storage内存(60%):存储数据,RDD持久化使用,如cache、persist、broadcast(广播)数据;
• other内存(20%):exector留给自己的内存,task通过shuffle过程拉取上一个stage的task的输出后,进行聚合等操作时使用。
1.6.0版本之前,每一个类的内存是相互隔离的,导致executor内存利用率不高
1.6.0版本之后,executor和storage之间的内存可以相互借用,提高了内存利用率,减少了OOM(out of memory内存溢出)的发生。
Task的执行速度和每个executor进程的CPU Core数量有直接关系,一个CPUCore同一时间只能执行一个线程,每个executor进程上分配到的多个task,都是以task一条线程的方式,多线程并发运行的。如果CPU Core数量比较充足,而且分配到的task数量比较合理,那么可以比较快速和高效地执行完这些task线程。
19 任务运行流程
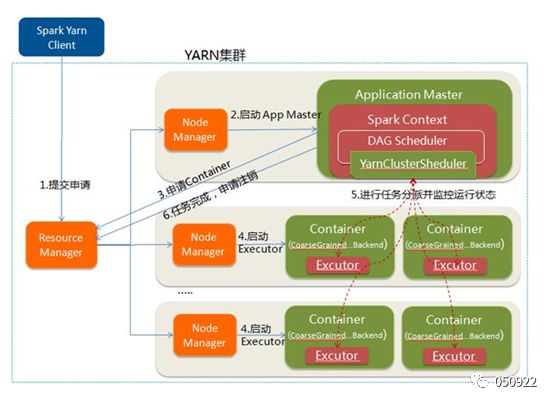
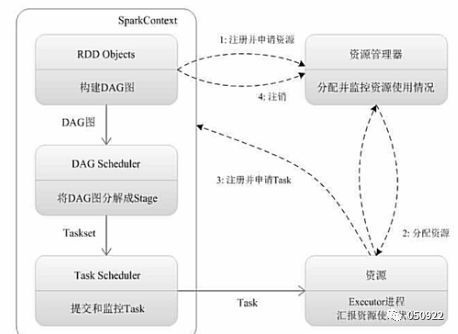
Spark Context:Spark应用的入口,创建需要的变量,连接集群的通道、任务分配、资源分发、监控任务执行等。
(1) 为应用构建起基本的运行环境,即由Driver创建一个SparkContext进行资源的申请、任务的分配和监控;
(2) 资源管理器(standalone、mesos、yarn)为executor分配资源,并启动executor进程;
(3) sparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler,TaskScheduler解析成一系列tasks;
(4) Executor向SparkContext申请Task任务,TaskScheduler将Task发放给Executor运行并提供应用程序代码,任务分发原则:计算向数据靠拢,最小化数据传输,把任务优先分发到数据所在的机器;
(5) Task在Executor上运行把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源。
20 提交任务参数
前三个参数是必须指定的,后面的看需求
• num-executors:该作业总共需要多少executor进程执行;
– 建议:每个作业运行一般设置50~100个左右较合适
• executor-memory:设置每个executor进程的内存,num-executors*numexecutors代表作业申请的总内存量(尽量不要超过最大总内存的1/3~1/2);
– 建议:设置4G~8G较合适
• executor-cores:每个executor进程的CPU Core数量,该参数决定每个executor进程并行执行task线程的能力, num-executors* executor-cores代表作业申请总CPU core数(不要超过总CPUCore的1/3~1/2 );
– 建议:设置2~4个较合适
• driver-memory:设置Driver进程的内存;
– 建议:通常不用设置,一般1G就够了,若出现使用collect算子将RDD数据全部拉取到Driver上处理,就必须确保该值足够大,否则OOM内存溢出
• spark.default.parallelism:每个stage的默认task数量;
– 建议:设置500~1000较合适,默认一个HDFS的block对应一个task, Spark默认值偏少,这样导致不能充分利用资源
• spark.storage.memoryFraction:设置RDD持久化数据在executor内存中能占的比例,默认0.6,即默认executor60%的内存可以保存持久化RDD数据;
– 建议:若有较多的持久化操作,可以设置高些,超出内存的会频繁gc导致运行缓慢
• spark.shuffle.memoryFraction:聚合操作占executor内存的比例,默认0.2;
– 建议:若持久化操作较少,但shuffle较多时,可以降低持久化内存占比,提高shuffle操作内存占比















 2401
2401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









