










这篇博文没有给出源码,如果需要这个项目的源码,可以到https://github.com/common1994/Project/tree/master/FileCompress下载。
(1)项目背景:练习哈夫曼树时,了解了哈夫曼树的应用,开始着手写这个文件压缩项目。
(2)项目描述:
- 哈夫曼树:根据一系列权值,每次选出其中最小的两个作为两个树节点,把这两个节点的和作为他们的根节点并把根节点放入这个权值向量中,再次取出其中最小的两个,构建另外的节点,这样最后剩下一个节点就是哈夫曼树的根节点。 哈夫曼树特点: 权值都放在了叶子节点上; 因为每次选最小的两个,从下到上构建哈夫曼树,这样,权值较大的都放到上层,较小的都放到下层。
- 哈夫曼编码: 从根节点往下遍历,若规定向左,则为0,反之则为1,这样每个权值都有一个唯一的路径,也就有一个唯一的编码,这个编码成为哈夫曼编码;
- 如果把一个文件中字符出现的次数作为权值,这样,出现次数多的字符都被放到上层,这个字符的编码就比较短,因为哈夫曼编码是以二进制位为单位,总体下来,压缩文件大小是小于源文件的,从而达到压缩的目的。
(3)主要技术:哈夫曼树,哈夫曼编码,堆
(4)哈夫曼编码原理:

(5)工程框架&效率比较:
使用open/read/write系列函数完成的:
使用fopen/fread/fwrite系列函数完成的:
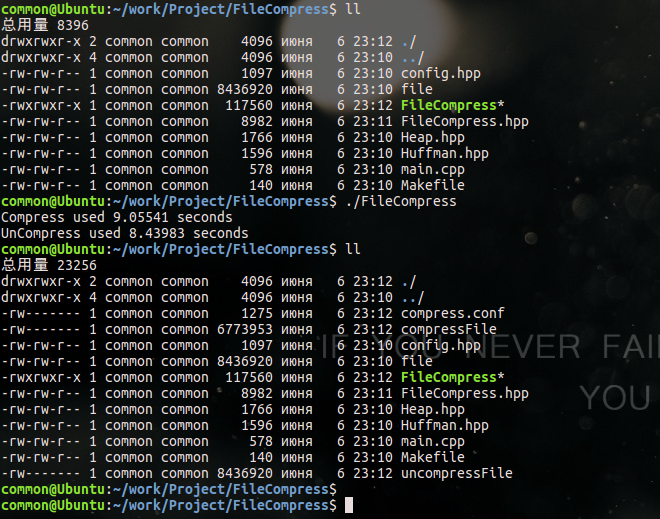
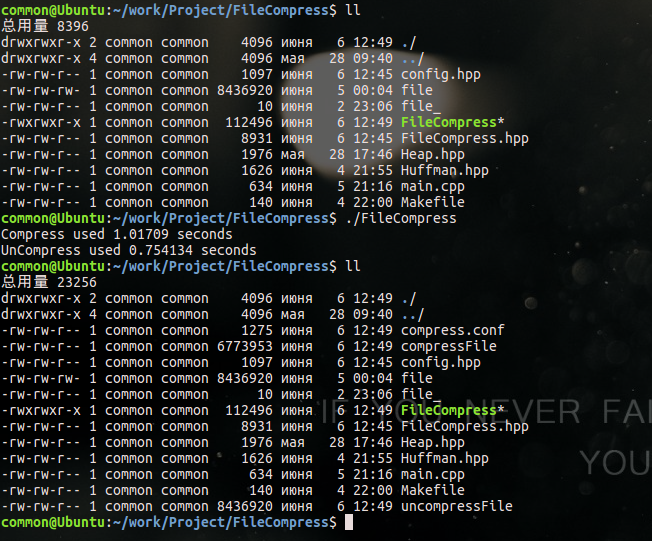
从以上两幅图可以看出,使用fread系列函数比使用read系列函数,性能提升了10倍,这是因为fread系列函数从某种程度优于read系列函数,这里先不说,等文章最后给出两者的差别。
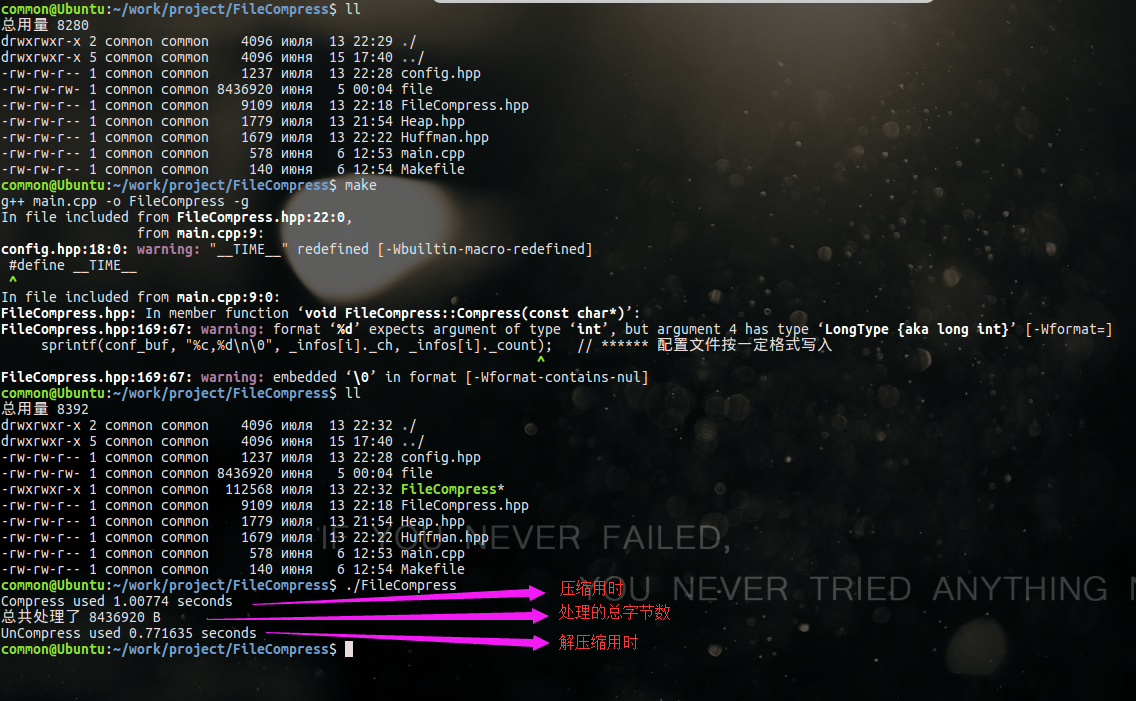
(6)最终运行结果:
没有定义 PRINT 宏:
(ps: PRINT 宏是条件编译,是否编译打印哈夫曼树的函数)
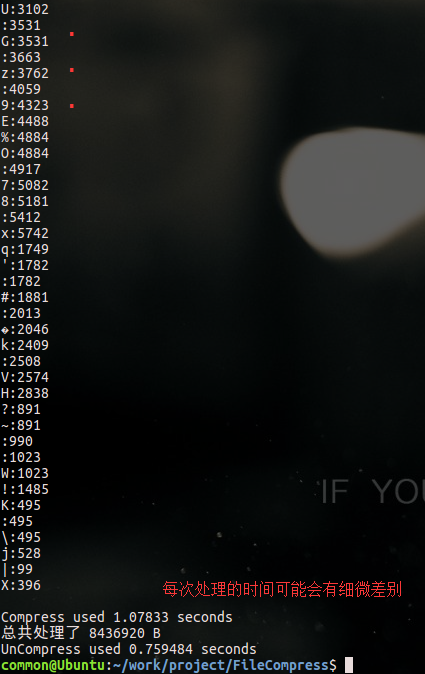
定义了PRINT宏:
(ps:打印的内容是 文件中出现的字符+冒号+该字符在该文件中出现的次数+换行。
这里因为图片太大,只截取了其中一部分,上面还有很多字符的信息没有显示出来)
下面是原文件(待压缩文件)和解压缩文件的对比:(使用了软件Compare来比较)
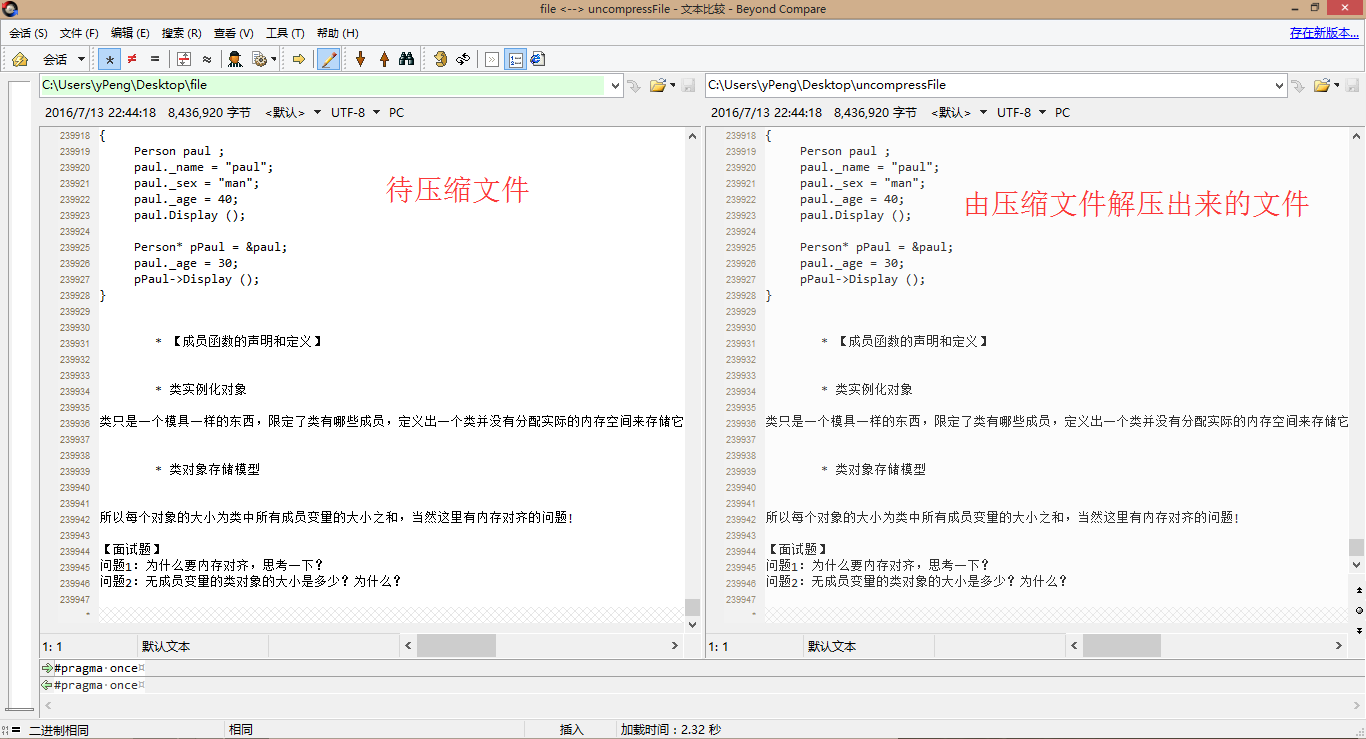
可以看出,解压缩文件与原文件一模一样,说明压缩与解压缩没有问题。
附: fread系列函数与read系列函数的比较:
1. 如果程序对内存有限制,则用read/write比较好。
2. fopen返回文件指针,open返回文件描述符(整数).。
3. fopen是标准C的库函数,操作的对象是 文件指针,open是POSIX中定义的,是系统调用,操作对象是文件描述符。
4. 前者fopen/fread的实现是靠调用底层的open/read来实现的。
5. fopen不能指定要创建文件的权限,open可以指定权限.
6. fread可以读一个结构. read在linux/unix中读二进制与普通文件没有区别.
7. linux/unix中任何设备都是文件,都可以用open,read.
最重要的一点,read是系统调用,调用该函数会陷入内核态,而程序不断从用户态到内核态切换,会消耗大量的CPU时间,所以对于处理约8000000 字节的数据,fread系列函数能比read系列函数性能提升10倍。
















 2248
2248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









