









 本文介绍如何使用TinyXML库创建和读取XML文件。通过一个简单的例子展示了创建XML文件的方法,并从中读取猫的信息节点。适用于Windows和Linux平台。
本文介绍如何使用TinyXML库创建和读取XML文件。通过一个简单的例子展示了创建XML文件的方法,并从中读取猫的信息节点。适用于Windows和Linux平台。
使用Tinyxml创建和读取XML文件的优点:1,可在Windows和Linux中使用;2,方便易学,易用,可在http://sourceforge.net/projects/tinyxml/获取源代码。将其中的文件tinystr.h,tinyxml.h,tinystr.cpp,tinyxmlerror.cpp,tinyxmlparser.cpp和tinyxml.cpp拷贝到您的工程目录,即可方便使用。
下边我写了一个简单的测试程序,创建XML文件,之后从该文件中读取XML节点元素。测试程序在VS2005中测试通过。
下边是生成的cat.xml文件
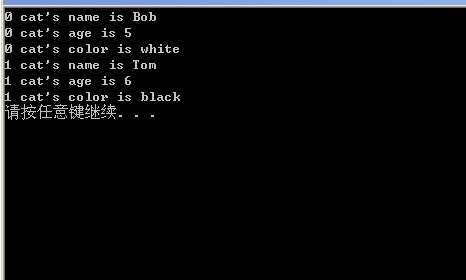
从cat.xml文件读取节点元素,进行打印


















 5662
5662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











