







练习 13-1
编写一个程序,读入一个文件,将每行内容拆解为单词,剥去单词周围的空白字符和标点,并转换为小写。
例如如下文本emma.txt,地址为:点击打开链接
1 import string
2
3 def process_line(line,hist):
4 line = line.replace('-',' ')
5 for word in line.split():
6 word = word.strip(string.punctuation+string.whitespace)
7 word = word.lower()
8 hist[word] = hist.get(word,0) + 1
9
10 def process_file(filename):
11 hist = dict()
12 fin = open(filename)
13 for line in fin:
14 process_line(line,hist)
15 return hist
16
17 hist = process_file("emma.txt")
18 print hist
练习 13-2
去往古腾堡工程(Project Gutenberg,http://www.gutenberg.org)并下载你最喜欢的无版权书籍的纯文本文档。
修改前一个练习中的程序,并和前面一样将文本处理为单词。
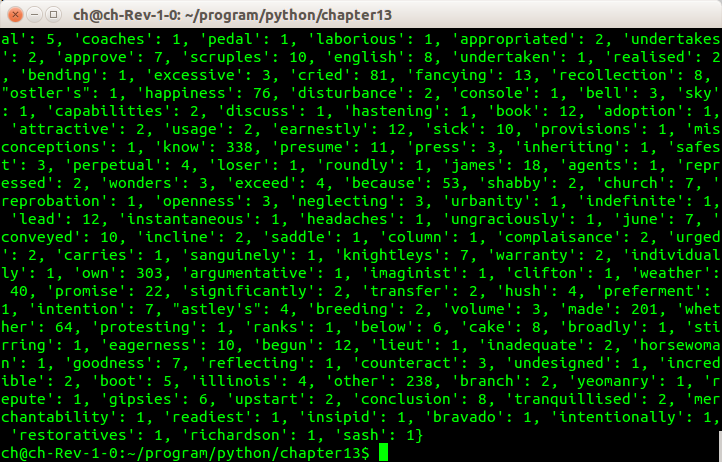
接着修改程序,计算书中出现的全部单词的总数,以及每个单词使用的次数。
def total_words(hist):
return sum(hist.values())
def different_words(hist):
return len(hist)

练习 13-3
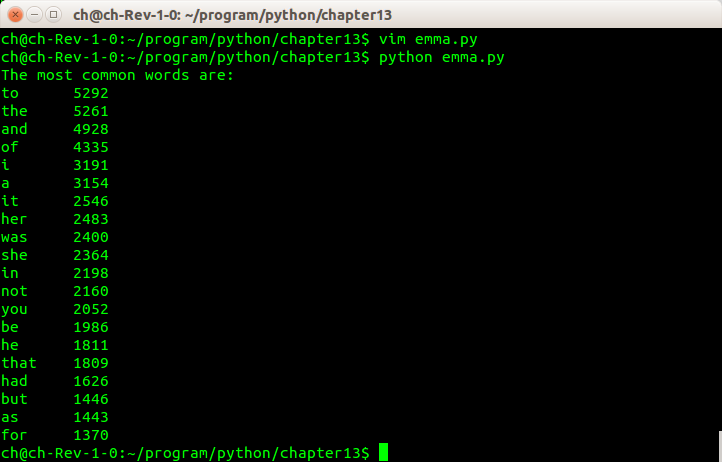
修改前一个练习中的程序,计算书中使用频率最高的20个单词。
def most_common(hist):
t = []
for key,value in hist.items():
t.append((value,key))
t.sort(reverse = True)
return t
hist = process_file("emma.txt")
t = most_common(hist)
print 'The most common words are:'
for value,key in t[:20]:
print key,'\t',value
练习 13-4
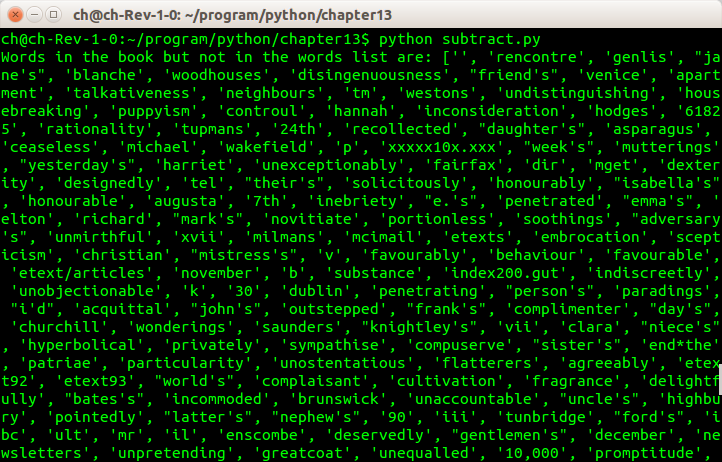
修改前面的程序,读入一个单词表,并打印出书中所有不在单词表之中的单词。
def substract(dict1,dict2):
res = dict()
for key in dict1:
if key not in dict2:
res[key] = None
return res
hist = process_file("emma.txt")
words = process_file("words.txt")
res = substract(hist,words)
print "Words in the book but not in the words list are:",res.keys()
练习 13-7
编写一个程序,使用这个算法来从书中选择一个随机的单词。
1 import string
2 import random
3
4 from bisect import bisect
5 from analyze_book import *
6
7 def random_word(hist):
8 words = []
9 freqs = []
10 total_freq = 0
11
12 for word, freq in hist.items():
13 total_freq += freq
14 words.append(word)
15 freqs.append(total_freq)
16
17 x = random.randint(0, total_freq-1)
18 index = bisect(freqs, x)
19 return words[index]
20
21
22 if __name__ == '__main__':
23 hist = process_file('emma.txt', skip_header=True)
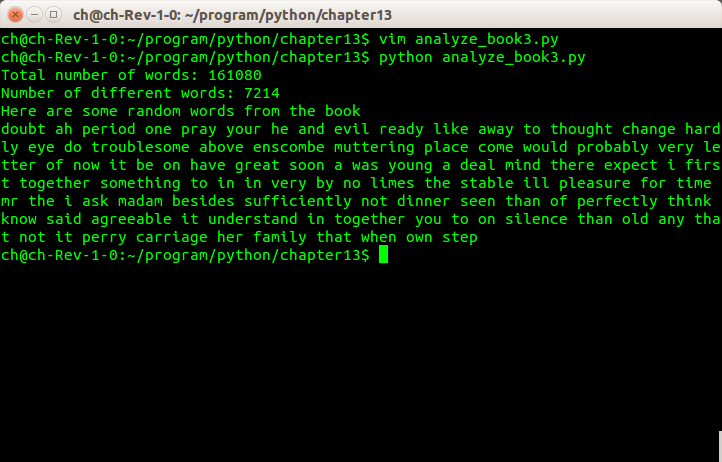
24 print 'Total number of words:', total_words(hist)
25 print 'Number of different words:', different_words(hist)
26
27 print "Here are some random words from the book"
28 for i in range(100):
29 print random_word(hist),
练习 13-8
马尔可夫分析:
1.编写一个程序从文本中读入文本,并进行马尔可夫分析。结果应该是一个字典,将前缀映射到可能后缀的集合。集合可以是列表、元组或者字典;由你来做出合适的选择。你可以使用前缀长度2来测试程序,但编写程序时应当考虑可以方便的改为其他前缀长度。当增加前缀长度时,结果会怎么样?随机生成的文本会不会看来更有意义?
1 import sys
2 import string
3 import random
4
5 # global variables
6 suffix_map = {} # map from prefixes to a list of suffixes
7 prefix = () # current tuple of words
8
9
10 def process_file(filename, order=2):
11 fp = open(filename)
12 skip_gutenberg_header(fp)
13
14 for line in fp:
15 for word in line.rstrip().split():
16 process_word(word, order)
17
18
19 def skip_gutenberg_header(fp):
20 for line in fp:
21 if line.startswith('*END*THE SMALL PRINT!'):
22 break
23
24
25 def process_word(word, order=2):
26 global prefix
27 if len(prefix) < order:
28 prefix += (word,)
29 return
30
31 try:
32 suffix_map[prefix].append(word)
33 except KeyError:
34 # if there is no entry for this prefix, make one
35 suffix_map[prefix] = [word]
36
37 prefix = shift(prefix, word)
38
39
40 def random_text(n=100):
41 # choose a random prefix (not weighted by frequency)
42 start = random.choice(suffix_map.keys())
43
44 for i in range(n):
45 suffixes = suffix_map.get(start, None)
46 if suffixes == None:
47 # if the start isn't in map, we got to the end of the
48 # original text, so we have to start again.
49 random_text(n-i)
50 return
51
52 # choose a random suffix
53 word = random.choice(suffixes)
54 print word,
55 start = shift(start, word)
56
57
58 def shift(t, word):
59 return t[1:] + (word,)
60
61
62 def main(name, filename='', n=100, order=2, *args):
63 try:
64 n = int(n)
65 order = int(order)
66 except:
67 print 'Usage: randomtext.py filename [# of words] [prefix length]'
68 else:
69 process_file(filename, order)
70 random_text(n)
71
72
73 if __name__ == '__main__':
74 main(*sys.argv)
练习 13-9
一个单词的“排名”是它在单词列表中按频率排序的位置:最常见的词排名第1,次常见的词排第2,等等。
齐普夫定律描述了排名和自然语言中词频的关系。特别的,它预测了排名为r的单词的频率f: f = cr的(-s)次幂。
这里 s 和 c 是依赖于语言和文本的参数。如果你在表达式两侧都调用对数,则得到: log g = log c - s log r
所以如果你以log r为横轴给 log f 绘图,则会得到斜率为 -s,截距为 log c 的直线。
编写一个程序,从文件中读入文本,计算单词词频,并按照词频的降序,每一行打印出一个单词,以及log f 和 log r。使用你喜欢的制图将结果以图表形式展现出来,并检查它是否为直线。你能估计s的值么?
1 import sys
2 import string
3
4 import matplotlib.pyplot as pyplot
5
6 from analyze_book import *
7
8
9 def rank_freq(hist):
10 freqs = hist.values()
11 freqs.sort(reverse=True)
12
13 rf = [(r+1, f) for r, f in enumerate(freqs)]
14 return rf
15
16
17 def print_ranks(hist):
18 for r, f in rank_freq(hist):
19 print r, f
20
21
22 def plot_ranks(hist, scale='log'):
23 t = rank_freq(hist)
24 rs, fs = zip(*t)
25
26 pyplot.clf()
27 pyplot.xscale(scale)
28 pyplot.yscale(scale)
29 pyplot.title('Zipf plot')
30 pyplot.xlabel('rank')
31 pyplot.ylabel('frequency')
32 pyplot.plot(rs, fs, 'r-')
33 pyplot.show()
34
35
36 def main(name, filename='emma.txt', flag='plot', *args):
37 hist = process_file(filename, skip_header=True)
38
39 # either print the results or plot them
40 if flag == 'print':
41 print_ranks(hist)
42 elif flag == 'plot':
43 plot_ranks(hist)
44 else:
45 print 'Usage: zipf.py filename [print|plot]'
46
47
48 if __name__ == '__main__':
49 main(*sys.argv)















 8232
8232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









