







字符串匹配的KMP算法,我之前复习数据结构的时候看过一遍没有看懂,今天我结合左程云的“程序员代码面试指南”和 阮一峰:字符串匹配的KMP算法 可以算是基本理解了KMP算法的思想。突然发现这个算法也并不复杂,之前想到就头痛(我滴天!)。
KMP算法基本思想
KMP算法是一种用于字符串匹配的算法,这个算法的高效之处在于当在某个位置匹配不成功的时候可以根据之前的匹配结果从模式字符串的另一个位置开始,而不必从头开始匹配字符串。
举例来说,有一个字符串”BBC ABCDAB ABCDABCDABDE”,我想知道,里面是否包含另一个字符串”ABCDABD”?
字符串匹配
-

首先,字符串”BBC ABCDAB ABCDABCDABDE”的第一个字符与搜索词”ABCDABD”的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。 -

因为B与A不匹配,搜索词再往后移。
3.

就这样,直到字符串有一个字符,与搜索词的第一个字符相同为止。 -

接着比较字符串和搜索词的下一个字符,还是相同。
5.

直到字符串有一个字符,与搜索词对应的字符不相同为止。 -

这时,最自然的反应是,将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把”搜索位置”移到已经比较过的位置,重比一遍。 -

一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是”ABCDAB”。KMP 算法的想法是,设法利用这个已知信息,不要把”搜索位置”移回已经比较过的位置,继续把它向后移,这样就提高了效率。 -

怎么做到这一点呢?可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)。这张表是如何产生的,后面再介绍,这里只要会用就可以了。 
已知空格与D不匹配时,前面六个字符”ABCDAB”是匹配的。查表可知,最后一个匹配字符B对应的”部分匹配值”为2,因此按照下面的公式算出向后移动的位数:移动位数 = 已匹配的字符数 - 对应的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动 4 位。
-

因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2(”AB”),对应的”部分匹配值”为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移 2 位。 -

因为空格与A不匹配,继续后移一位。 -

逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动 4 位。 -

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动 7 位,这里就不再重复了。
子串的部分匹配值next数组
获得记录跳转状态的next数组。这个数组的长度与子串的长度一样,next[i]的含义是在match[i]之前的字符串match[0…i-1]中,必须以match[i-1]结尾的后缀子串(不能包含match[0])与必须以match[0]开头的前缀子串(不能包含match[i-1])最大匹配长度是多少。这个长度就是next[i]的值。
求解过程如下:
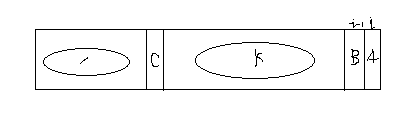
- 因为是左到右依次求解next,所以在求解next[i]时,next[0…i-1]的值都已经求出。假设match[i]字符为下图的A字符,match[i-1]为B字符。
match:
通过next[i-1]的值可以知道B字符的最长前缀和最长后缀匹配,图中的/区域为最长匹配的前缀子串,k区域为最长匹配的后缀子串,字符C为/区域之后的字符。然后看字符C是否与字符B相等。 - 如果字符C与字符B相等,那么A字符之前的字符串的最长前缀与后缀匹配区域就可以确定,前缀子串为/区域+C字符,后缀子串就是K区域+B字符,即next[i] = next[i-1] + 1;
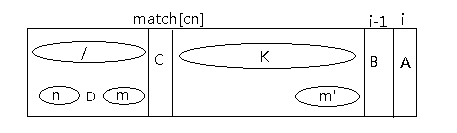
- 如果字符C与字符B不相等,那就看字符C之前的前缀与后缀匹配情况,假设字符C是第cn个字符,那么next[cn]就是其最长前缀和后缀匹配长度。如图
match:
m区域和n区域分别是字符C之前的字符串的最长匹配的后缀与前缀区域,这是通过next[cn]的确定的,当然两个区域是相等的,m’区域为k区域最优的区域且长度与m区域一样,因为k区域和/区域是相等的,所以m区域和m’区域也相等,字符串D为n区域之后的一个字符串,接下来比较D是否与字符串B相等。
- 如果相等,A字符之前的字符串的最长前缀与后缀匹配区域就可以确定,前缀子串为n区域+D字符,后缀子串为m’区域+B字符,则next[i] = next[cn] + 1。
- 如果不等,继续往前跳到字符D,之后的过程与跳到字符C类似,一直进行这样的跳过程,跳的每一步都会有一个新的字符和B比较,只要有相等的情况,next[i]的值就能确定。
- 如果向前跳到最左位置,此时next[0] = -1,说明字符A之前的字符串不存在前缀和后缀的匹配情况,则令next[i] = 0。用这种不断向前跳的方式可以算出正确的next[i]值的原因还是因为每跳到一个位置cn,next[cn]的意义就表示他之前字符串的最大匹配长度。
代码实现
package com.xqq.字符串匹配KMP;
public class Test {
public static void main(String[] args) {
String s = "acbc";
String m = "bc";
System.out.println(getIndexOf(s, m));
}
public static int getIndexOf(String s, String m){
if(s == null || m == null || m.length() < 1 || s.length() < m.length())
return -1;
char [] ss = s.toCharArray();
char [] ms = m.toCharArray();
int si = 0;
int mi = 0;
int [] next = getNextArray(ms);
while(si < ss.length && mi < next.length){
if(ss[si] == ms[mi]){
si++;
mi++;
}else if(next[mi] == -1){
si++;
}else {
mi = next[mi];
}
}
return ((mi == ms.length) ? (si - mi) : -1);
}
/**
* 获取next数组
*/
public static int [] getNextArray(char [] ms){
if(ms.length == 1)
return new int[]{-1};
int [] next = new int[ms.length];
next[0] = -1;
next[1] = 0;
int pos = 2;
int cn = 0;
while(pos < ms.length){
if(ms[pos] == ms[cn])
next[pos++] = ++cn;
else if(cn > 0)
cn = next[cn];
else
next[pos++] = 0;
}
return next;
}
}
运行结果:
2加油~~~~















 1355
1355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









