







“在一个字符串S中查找一个词W出现的位”是一道常见的面试题。
相对于那些要对树、图进行操作的算法,这个算法要处理的是一维线性的字符序列。看起来似乎简单不少,那么算法难度会更低吗?让我们来看看。
简单直接的字符串查找算法
算法原理
首先,如果只是笼统地从一个字符串中查找另一个字符串,有一种很直接的方法,那就是:
从 S 的第 1 个字符开始,与 W的每一个字符一一匹配。
-
如果一致,就继续匹配下一个,如果w的所有字符都匹配上了,则说明已经查找到了W。
如果不一致,则从S的第 2 个字符开始重复整个过程;如果还不行就再从第三个字符开始……总之就是跳回到本次匹配S开始处的下一个字符,然后重新开始整个匹配过程
如果到最后都没有匹配上完整的W,则说明S中根本无法找到 W。
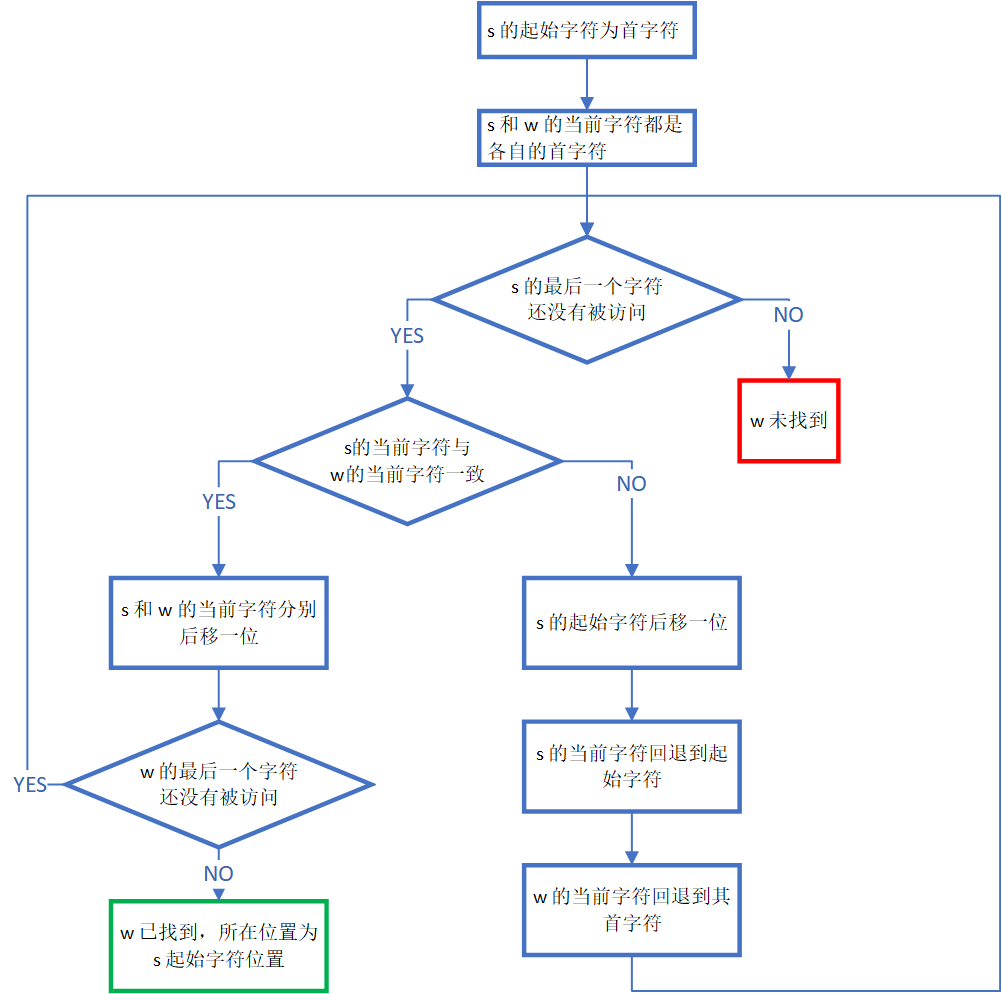
算法流程图
本算法流程图如下:
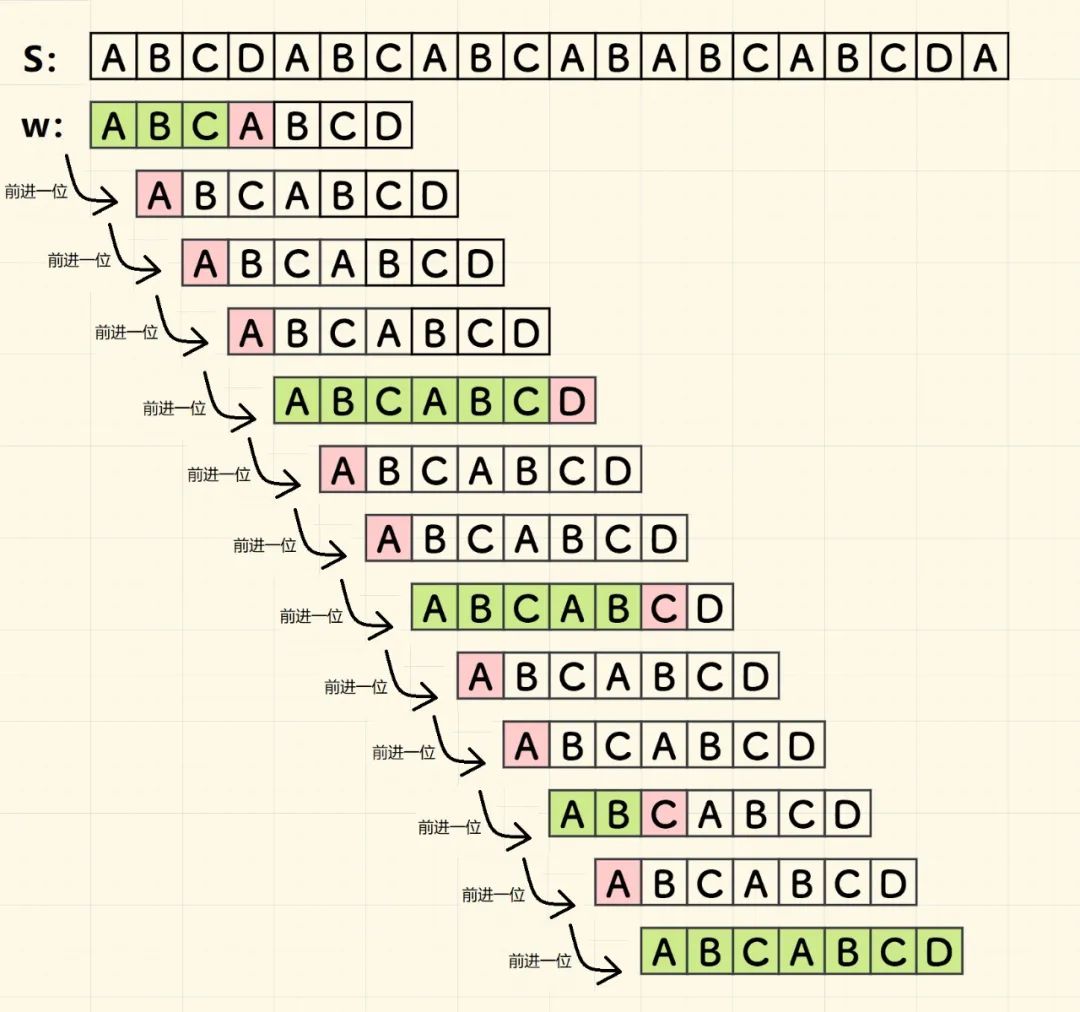
算法运行示例
按照它进行字符串查找的案例如下:
算法性能
这个算法又简单又好操作,唯一的缺点是有点慢。

假设 S 的长度为 n 而 W的长度为 m,则这个直接算法的时间复杂度是 O(n*m)。
有没有效率更高的,时间复杂度类似 O(n)的算法呢?还真的有,这个算法的名字叫做 KMP算法。
高效率的 KMP 算法
算法历史
K, M, P 这三个字母是本算法的三位发明人名字的缩写,这三位是:Knuth (大名鼎鼎的高德纳),Morris,和 Pratt。三人于1977年联合发表了该算法。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 8692
8692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











