







 本文介绍了如何使用TensorFlow和Softmax回归方法对手写数字进行识别,结合MNIST数据集,详细解释了模型构建、代价函数、交叉熵以及训练过程,展示了一个简单的模型就能达到92%的识别准确率。
本文介绍了如何使用TensorFlow和Softmax回归方法对手写数字进行识别,结合MNIST数据集,详细解释了模型构建、代价函数、交叉熵以及训练过程,展示了一个简单的模型就能达到92%的识别准确率。
对于人类来说,识别手写的数字是一件非常容易的事情。我们甚至不用思考,就可以看出下面的数字分别是5,0,4,1。
但是想让机器识别这些数字,则要困难得多。
如果让你用传统的编程语言(如Java)写一个程序去识别这些形态各异的数字,你会怎么写?写很多方法去检测横、竖、圆这些基本形状,然后计算它们的相对位置?我想你很快就会陷入绝望之中。即使你花很多时间写出来了程序,精确度也一定不高。当你在传统编程方法的小黑屋里挣扎时,机器学习这种更高阶的方法却为我们打开了一扇窗。
为了找到识别手写数字的方法,机器学习界的大师Yann LeCun利用NIST(National Institute of Standards and Technology 美国国家标准技术研究所)的手写数字库构建了一个便于机器学习研究的子集MNIST。MNIST由70000张手写数字(0~9)图片(灰度图)组成,由很多不同的人写成,其中60000张是训练集,另外10000张是测试集,每张图片的大小是28 * 28像素,数字的大小是20 * 20,位于图片的中心。更详细的信息可以参考Yann LeCun的网站:http://yann.lecun.com/exdb/mnist/
已经有很多研究人员利用该数据集进行了手写数字识别的研究,也提出了很多方法,比如KNN、SVM、神经网络等,精度已经达到了人类的水平。
抛开这些研究成果,我们从头开始,想想怎样用机器学习的方法来识别这些手写数字。因为数字只包含0~9,对于任意一张图片,我们需要确定它是0~9中的哪个数字,所以这是一个分类问题。对于原始图片,我们可以将它看作一个28 * 28的矩阵,或者更简单地将它看作一个长度为784的一维数组。将图片看作一维数组将不能理解图片里的二维结构,我们暂且先这么做,看能够达到什么样的精度。这样一分析,我们很自然地就想到可以用Softmax回归来解决这个问题。关于Softmax Regression可以参考下面的文章:
http://ufldl.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92
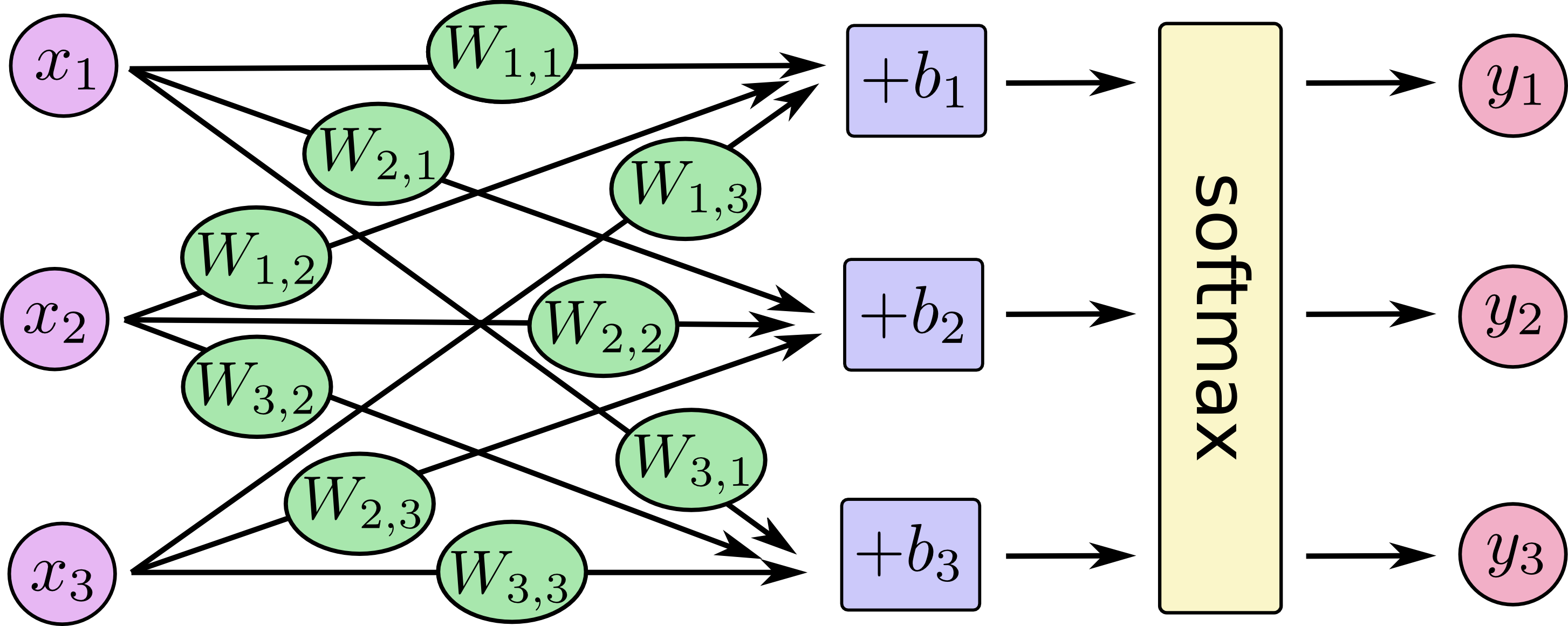
我们的模型如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 457
457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









